康奈尔大学的人工智能(AI)研究人员提出了一种新的神经网络框架,以解决视频抠像问题
康奈尔大学的研究人员提出了新的神经网络框架,用于解决视频抠像问题


图像和视频编辑是计算机用户最常用的两个应用之一。随着机器学习(ML)和深度学习(DL)的出现,图像和视频编辑已经通过几种神经网络架构逐渐被研究。直到最近,大多数用于图像和视频编辑的DL模型都是有监督的,更具体地说,需要训练数据包含输入和输出数据的对,用于学习所需转换的细节。最近,提出了端到端学习框架,它们只需要一个单一图像作为输入,就可以学习到所需编辑输出的映射。
视频抠像是属于视频编辑的特定任务。”抠像”这个术语可以追溯到19世纪,当时在拍摄过程中,在摄像机前设置了一些使用磨砂漆的玻璃板,以营造出在拍摄地点不存在的环境的幻象。现在,多个数字图像的组合遵循类似的过程。一个组合公式被利用来调节每个图像的前景和背景的强度,表示为两个组成部分的线性组合。
尽管这个过程非常强大,但它也有一些限制。它需要将图像明确分解为前景和背景层,并假设它们可以独立处理。在一些情况下,比如视频抠像,因此是一系列时间和空间相关的帧,图层分解变得更加复杂。
- 2023年机器学习研究中的顶级数据版本控制工具
- 中国的研究人员提出了一种基于联邦学习(FL)的新型μXRD图像筛选方法,旨在在保护数据隐私的同时提高筛选效果
- 梅奥诊所的AI研究人员引入了一种基于机器学习的方法,利用扩散模型构建了一种多任务的脑肿瘤修复算法
本文的目标是启发这个过程并提高分解的准确性。作者提出了因子抠像(FactorMatte),这是抠像问题的一种变体,将视频分解成更独立的组件,以便进行后续的编辑任务。为了解决这个问题,他们还提出了FactorMatte,一个易于使用的框架,它将经典的抠像先验与基于场景中预期变形的条件先验相结合。例如,经典的贝叶斯公式,用于估计最大后验概率,被推广以消除前景和背景独立性的限制假设。此外,大多数方法还假设背景层随时间保持静态,这对于大多数视频序列来说是严重限制的。
为了克服这些限制,FactorMatte依赖于两个模块:一个分解网络,用于将输入视频分解为每个组件的一个或多个图层,以及一组基于补丁的判别器,用于表示每个组件的条件先验。该架构流程如下图所示。
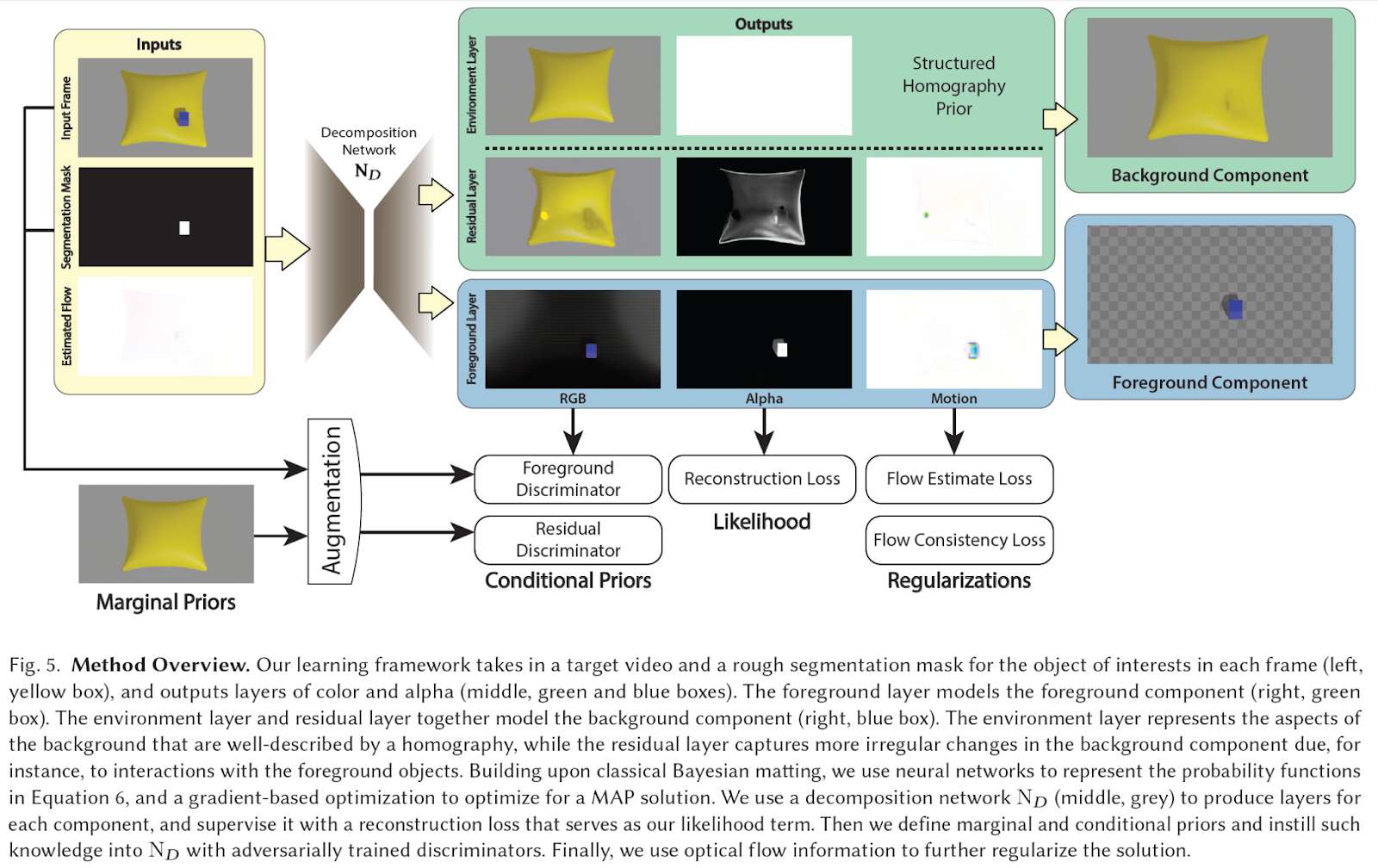
分解网络的输入由视频和关于感兴趣对象的粗糙分割掩码组成。根据这些信息,网络根据重构损失生成颜色和alpha的图层。前景图层模拟前景组件,而环境图层和残差图层则共同模拟背景组件。环境图层表示背景的静态部分,而残差图层捕捉到背景组件与前景对象的相互作用引起的更不规则的变化(例如图中的枕头变形)。对于每个图层,都训练了一个判别器来学习相应的边际先验。
下图展示了一些选定样本的抠像结果。

虽然FactorMatte并非完美,但生成的结果明显比基准方法(OmniMatte)更准确。在所有给定的样本中,背景和前景层之间呈现出清晰的分离,而对比的解决方案则不能做出这样的断言。此外,已经进行了消融研究来证明所提出的解决方案的有效性。
这是FactorMatte的摘要,这是一个解决视频抠图问题的新框架。如果您有兴趣,可以在下面的链接中找到更多信息。






