墨水到洞察:使用书店分析比较SQL和Python查询
墨水到洞察:书店分析比较SQL和Python查询
哪种方法对你的探索性数据分析更好?
SQL是任何数据科学家工具箱中的基本工具 —— 快速从数据源中提取数据进行分析的能力对于任何处理大量数据的人来说都是一项必备技能。在本文中,我想给出一些在EDA过程中我通常在SQL中使用的几个基本查询的示例。我将比较这些查询与在Python中生成相同输出的类似脚本,作为对这两种方法的比较。
对于这个分析,我将使用一些关于去年最高评分书籍的合成数据来自一个假设的书店连锁店(Total Fiction Bookstore)。可以在这里找到该项目的github文件夹的链接,其中我详细介绍了运行此分析的细节。
顺便提一句 —— 虽然本文主要关注SQL查询,但值得注意的是,可以使用pandaSQL库将这些查询与Python相互整合得相当无缝(就像我在这个项目中所做的那样)。这可以在该项目的GitHub链接上的Jupyter笔记本中详细了解,但是这个查询的结构通常如下所示:
query = """SELECT * FROM DATA"""output = sqldf(query,locals())outputPandaSQL是一个非常实用的库,对于那些对SQL查询比典型的Pandas数据集操作更熟悉的人来说,这个库通常更容易阅读,正如我在这里所展示的。
数据集
下面可以看到数据集的一部分 —— 包括书名和出版年份、页数、流派、书籍的平均评分、作者、销售单位数和书籍收入的列。
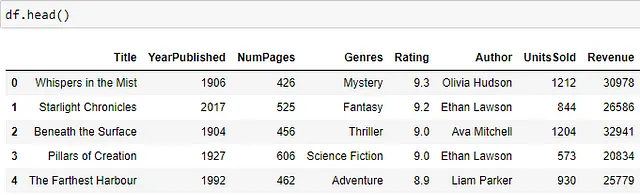
按十年进行收入分析
假设我想知道哪个十年出版的书籍对书店来说最有利可图。原始数据集没有一个列来表示书籍出版的十年 —— 不过这相对容易输入到数据中。我运行一个子查询来使用地板除法将年份转换成十年数据,然后按十年对投票进行聚合和平均。然后我按总收入排序得到书店中收入最高的出版十年的结果。
WITH bookshop AS(SELECT TITLE, YEARPUBLISHED,(YEARPUBLISHED/10) * 10 AS DECADE,NUMPAGES, GENRES, RATING, AUTHOR, UNITSSOLD,REVENUEfrom df)SELECT DECADE, SUM(REVENUE) AS TOTAL_REVENUE,ROUND(AVG(REVENUE),0) AS AVG_REVENUEFROM bookshopGROUP BY DECADEORDER BY TOTAL_REVENUE DESC相比之下,在Python中的等效输出可能看起来像下面的代码片段。我应用了一个lambda函数来运行地板除法并输出十年,然后按十年对投票进行聚合并按总收入对结果进行排序。
# 创建df bookshopbookshop = df.copy()bookshop['Decade'] = (bookshop['YearPublished'] // 10) * 10# 按十年分组,按总收入进行汇总和平均result = bookshop.groupby('DECADE') \ .agg({'Revenue': ['sum', 'mean']}) \ .reset_index()result.columns = ['Decade', 'Total_Revenue', 'Avg_Revenue']# 按十年排序result = result.sort_values('Total_Revenue')注意 Python 脚本中有更多的单独步骤来实现相同的结果 – 函数在第一次浏览时显得笨拙且难以理解。相比之下,SQL 脚本在呈现上更清晰,阅读起来更容易。
现在,我可以将此查询可视化,以了解不同十年间的图书收入趋势,使用以下脚本设置一个 matplotlib 图表 – 条形图显示按十年计算的总收入,辅以散点图显示平均图书收入。
# 创建主 y 轴(总收入)fig, ax1 = plt.subplots(figsize=(15, 9))ax1.bar(agg_decade['DECADE'], agg_decade['TOTAL_REVENUE'], width = 0.4, align='center', label='总收入(美元)')ax1.set_xlabel('十年')ax1.set_ylabel('总收入(美元)', color='blue')# 调整主 y 轴上的网格线ax1.grid(color='blue', linestyle='--', linewidth=0.5, alpha=0.5)# 创建辅助 y 轴(平均收入)ax2 = ax1.twinx()ax2.scatter(agg_decade['DECADE'], agg_decade['AVG_REVENUE'], marker='o', color='red', label='平均收入(美元)')ax2.set_ylabel('平均收入(美元)', color='red')# 调整辅助 y 轴上的网格线ax2.grid(color='red', linestyle='--', linewidth=0.5, alpha=0.5)# 为 ax1 和 ax2 设置相同的 y 轴限制ax1.set_ylim(0, 1.1*max(agg_decade['TOTAL_REVENUE']))ax2.set_ylim(0, 1.1*max(agg_decade['AVG_REVENUE']))# 合并两个坐标轴的图例lines, labels = ax1.get_legend_handles_labels()lines2, labels2 = ax2.get_legend_handles_labels()ax2.legend(lines + lines2, labels + labels2, loc='左上方')# 设置标题plt.title('按十年计算的总收入和平均收入')# 显示图表plt.show()下方可见可视化结果 – 1960 年代出版的图书显然是书店中最赚钱的,为 Total Fiction Bookstore 赚取了超过 192,000 美元的收入。相比之下,列表中来自 1900 年代的图书平均利润更高,但销售不如 1960 年代的图书。

所有年代的图书平均收入趋势与总收入类似 – 除了 1900 年代和 1980 年代的图书,它们的平均利润更高,但整体上不如其他年代。
作者分析
现在,假设我想要获取列表中前 10 位作者的数据,按他们的总收入排序。对于此查询,我想要知道他们在列表中出现的图书数量,他们在这些图书上产生的总收入,每本图书的平均收入以及书店中这些图书的平均评分。使用 SQL 回答这个简单的问题非常容易 – 我可以使用 count 语句获取他们制作的图书总数,并使用 avg 语句获取每位作者的平均收入和评分。之后,我可以按导演分组这些语句。
SELECT AUTHOR,COUNT(TITLE) AS NUM_BOOKS,SUM(REVENUE) AS TOTAL_REVENUE,ROUND(AVG(REVENUE),0) AS AVG_REVENUE,ROUND(AVG(RATING),2) AS AVG_RATING_PER_BOOKFROM bookshopGROUP BY AUTHORORDER BY TOTAL_REVENUE DESCLIMIT 10等效的 Python 脚本如下 – 长度大致相同,但对于相同的输出来说更加复杂。我在指定如何聚合每一列之前,按作者对值进行分组,然后按总收入排序。再次比较起来,SQL 脚本更清晰明了。
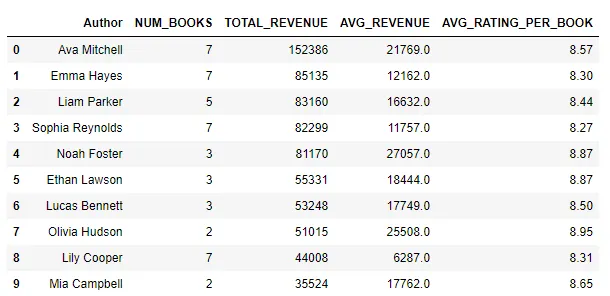
result = bookshop.groupby('Author') \ .agg({ 'Title': 'count', 'Revenue': ['sum', 'mean'], 'Rating': 'mean' }) \ .reset_index()result.columns = ['Author', 'Num_Books', 'Total_Revenue', 'Avg_Revenue', 'Avg_Rating_per_Book']# 按总收入排序result = result.sort_values('Total_Revenue', ascending=False)# 前 10 位result_top10 = result.head(10)从这个查询的输出可以看到,Ava Mitchell在图书销售中以超过152,000美元的总收入领先,Emma Hayes以超过85,000美元的收入排名第二,Liam Parker以超过83,000美元的收入紧随其后。
使用以下脚本在matplotlib中可视化,我们可以生成显示每位作者平均图书收入的数据点的总收入条形图。平均评分也在次轴上绘制。
# 创建图形和轴fig1, ax1 = plt.subplots(figsize=(15, 9))# 绘制总收入条形图ax1.bar(agg_author['Author'], agg_author['TOTAL_REVENUE'], width=0.4, align='center', color='silver', label='总收入(美元)')ax1.set_xlabel('作者')ax1.set_xticklabels(agg_author['Author'], rotation=-45, ha='left')ax1.set_ylabel('总收入(美元)', color='blue')# 调整主要y轴上的网格线ax1.grid(color='blue', linestyle='--', linewidth=0.5, alpha=0.5)# 创建平均收入散点图ax1.scatter(agg_author['Author'], agg_author['AVG_REVENUE'], marker="D", color='blue', label='每本书平均收入(美元)')# 创建平均评分散点图ax2 = ax1.twinx()ax2.scatter(agg_author['Author'], agg_author['AVG_RATING_PER_BOOK'], marker='^', color='red', label='每本书平均评分')ax2.set_ylabel('平均评分', color='red')# 调整次要y轴上的网格线ax2.grid(color='red', linestyle='--', linewidth=0.5, alpha=0.5)# 合并两个轴的图例lines, labels = ax1.get_legend_handles_labels()lines2, labels2 = ax2.get_legend_handles_labels()ax1.legend(lines + lines2, labels + labels2, loc='upper right')# 设置标题plt.title('收入和评分最高的前10位作者')# 显示图形plt.show()运行以上代码,我们得到以下图形:
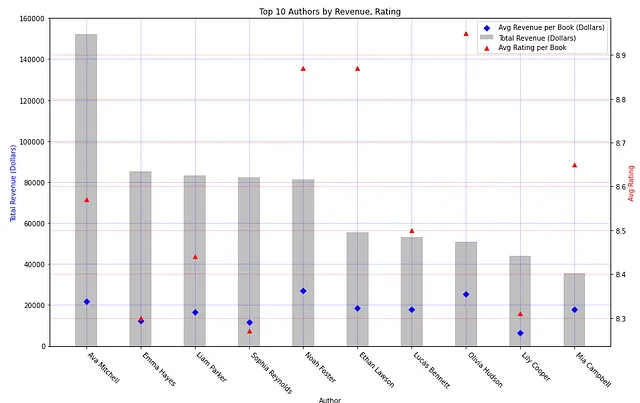
这个图形确实指出了一个明确的断言——收入与每位作者的平均评分没有相关性。Ava Mitchell的收入最高,但在上面列出的作者中评分处于中位数。Olivia Hudson的平均评分最高,但在总票数中排名第8;一个作者的收入与他们的知名度之间没有明显的趋势。
比较书籍长度与收入
最后,假设我想展示根据书籍长度不同书籍的收入差异。为了回答这个问题,我首先要在SQL中定义四分位数,使用子查询生成这些值,然后使用case when语句将书籍分成这些桶。
首先,在SQL中使用子查询定义四分位数,然后使用case when语句将书籍排序到这些桶中。
WITH PERCENTILES AS ( SELECT PERCENTILE_CONT(0.25) WITHIN GROUP (ORDER BY NUMPAGES) AS PERCENTILE_25, PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY NUMPAGES) AS MEDIAN, PERCENTILE_CONT(0.75) WITHIN GROUP (ORDER BY NUMPAGES) AS PERCENTILE_75 FROM bookshop)SELECT TITLE, TITLE, REVENUE, NUMPAGES, CASE WHEN NUMPAGES< (SELECT PERCENTILE_25 FROM PERCENTILES) THEN '第1四分位数' WHEN NUMPAGES BETWEEN (SELECT PERCENTILE_25 FROM PERCENTILES) AND (SELECT MEDIAN FROM PERCENTILES) THEN '第2四分位数' WHEN NUMPAGES BETWEEN (SELECT MEDIAN FROM PERCENTILES) AND (SELECT PERCENTILE_75 FROM PERCENTILES) THEN '第3四分位数' WHEN NUMPAGES > (SELECT PERCENTILE_75 FROM PERCENTILES) THEN '第4四分位数' END AS PAGELENGTH_QUARTILEFROM bookshopORDER BY REVENUE DESC另外(对于不支持百分位函数的SQL方言,如SQLite),可以先单独计算四分位数,然后将其手动输入到case when语句中。
--对于SQLite方言SELECT TITLE, REVENUE, NUMPAGES,CASEWHEN NUMPAGES < 318 THEN '第一四分位数'WHEN NUMPAGES BETWEEN 318 AND 375 THEN '第二四分位数'WHEN NUMPAGES BETWEEN 375 AND 438 THEN '第三四分位数'WHEN NUMPAGES > 438 THEN '第四四分位数'END AS PAGELENGTH_QUARTILEFROM bookshopORDER BY REVENUE DESC在Python中运行相同的查询,我在使用cut函数将书籍按页数分组之前,使用numpy定义了百分位数。与之前一样,这个过程比SQL中的等效脚本更复杂。
# 使用numpy定义百分位数percentiles = np.percentile(bookshop['NumPages'], [25, 50, 75])# 使用计算出的百分位数定义分箱边界bin_edges = [-float('inf'), *percentiles, float('inf')]# 定义桶的标签bucket_labels = ['第一四分位数', '第二四分位数', '第三四分位数', '第四四分位数']# 根据分箱边界和标签创建'RUNTIME_BUCKET'列bookshop['RUNTIME_BUCKET'] = pd.cut(bookshop['NumPages'], bins=bin_edges, labels=bucket_labels)result = bookshop[['Title', 'Revenue', 'NumPages', 'PAGELENGTH_QUARTILE']].sort_values(by='NumPages', ascending=False)可以使用seaborn将此查询的输出可视化为箱线图,下面是生成箱线图的脚本片段。请注意,运行时间桶被手动排序以正确呈现。
# 设置绘图样式sns.set(style="whitegrid")# 设置利润桶的顺序pagelength_bucket_order = ['第一四分位数', '第二四分位数', '第三四分位数', '第四四分位数']# 创建箱线图plt.figure(figsize=(16, 10))sns.boxplot(x='PAGELENGTH_QUARTILE', y='Revenue', data=pagelength_output, order = pagelength_bucket_order, showfliers=True)# 添加标签和标题plt.xlabel('页数四分位数')plt.ylabel('收入(美元)')plt.title('按页数桶划分的收入箱线图')# 显示图像plt.show()下面是箱线图的结果—请注意,每个书籍长度四分位数的中位数收入随着书籍长度的增加而上升。这表明在书店里,更长的书籍更有利可图。
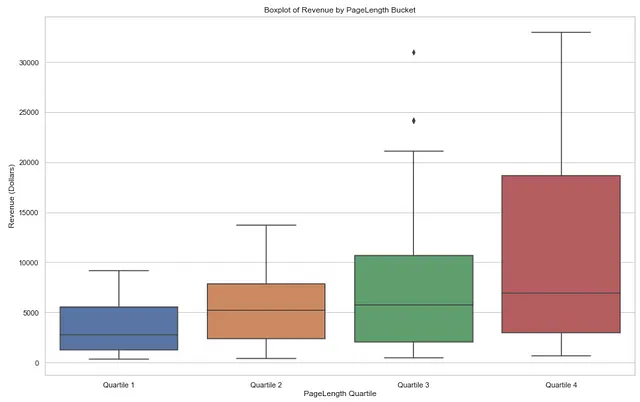
另外,第四四分位数的范围比其他四分位数要大得多,这表明大型书籍的价格点有更大的变化。
最后的思考和进一步应用
总之,对于数据分析查询,使用SQL通常比使用Python进行等效操作更简单直接;这种语言比Python查询更容易编写,同时广泛能够产生相同的结果。我不会认为其中任何一种比另一种更好—在本文中,我使用了这两种语言的组合—相反,我相信同时使用这两种语言可以产生更高效和更有效的数据分析。
因此,鉴于编写SQL查询比编写Python查询更具清晰性,我认为在执行项目的初始EDA时使用SQL更加自然。正如我在本文中所示,SQL更容易阅读和编写,特别适用于这些早期的探索性任务。我在开始项目时经常使用它,并且我建议已经对SQL查询有一定掌握的人采用这种方法。




