在数据清洗中使用Pandas之前,你应该阅读这篇文章的原因
在使用Pandas之前,应该阅读这篇文章
使用Pandas进行数据清洗、处理和探索

欢迎来到使用Pandas进行数据操作的快速教程!
在本教程中,我们将涵盖广泛的主题,从数据帧中的文本替换到数据帧的合并。
目录· 数据帧中的文本替换· 数据类型转换· 重命名数据帧列· 使用条件过滤数据· 数据帧排序· 数据分组和聚合· 数据帧合并· 最后的话Pandas库是Python中最重要的数据操作和清洗库之一。
因此,如果您计划从事任何与数据相关的业务,本文将对您有所帮助。
- ChatGPT被推翻:克劳德如何成为新的AI领导者
- 大多数公司在数据访问方面严重不足,71%的人认为合成数据可以提供帮助
- Justin McGill,Content at Scale的创始人兼首席执行官-访谈系列
让我们开始学习这些方法,作为数据科学家,您可能每天都会使用它们来准备数据。
但是,首先,让我们加载我们的数据集。
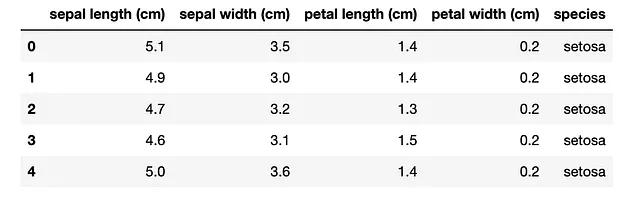
from sklearn.datasets import load_irisimport pandas as pdiris_bunch = load_iris()iris = pd.DataFrame(data=iris_bunch.data, columns=iris_bunch.feature_names)iris['species'] = iris_bunch.targetiris['species'] = iris['species'].map({0: 'setosa', 1: 'versicolor', 2: 'virginica'})iris.head()这是输出结果。
数据帧中的文本替换
通常,您应该替换数据帧中的内容,以使其按照您的意愿进行更改,例如清理分类数据或进行标准化。
import pandas as pdimport numpy as npiris_replaced = pd.DataFrame(data=iris['data'], columns=iris['feature_names'])iris_replaced['target'] = iris['target']iris_replaced['target'] = np.where(iris_replaced['target'] == 0, 'iris_setosa', iris_replaced['target'])iris_replaced.head()




