发布Swift Transformers:在Apple设备上运行的On-Device LLMs
发布Swift Transformers:在Apple设备上运行的On-Device LLMs
我非常尊重iOS/Mac开发者。我从2007年开始为iPhone编写应用程序,当时连API或文档都不存在。新设备在约束空间中采用了一些不熟悉的决策,结合了强大的功能、屏幕空间、UI习惯、网络访问、持久性和延迟,与我们之前所习惯的有所不同。然而,这个社区很快就成功地创建了顶级应用程序,让人感觉它们与新范式相得益彰。
我相信机器学习是构建软件的一种新方式,我知道许多Swift开发者希望在他们的应用程序中加入AI功能。机器学习生态系统已经成熟了很多,有成千上万个解决各种问题的模型。此外,最近出现了几乎通用的LLM工具,只要我们能将我们的任务建模为在文本或类似文本的数据上工作,它们就可以适应新的领域。我们正在见证计算历史的一个决定性时刻,LLM正走出研究实验室,成为每个人的计算工具。
然而,将像Llama这样的LLM模型用于应用程序涉及许多任务,许多人都面临并独自解决。我们一直在探索这个领域,并希望与社区继续合作。我们的目标是创建一套工具和构建块,帮助开发者更快地构建。
今天,我们发布了这个指南,介绍了在Mac上使用Core ML运行像Llama 2这样的模型所需的步骤。我们还发布了alpha版的库和工具,以支持开发者在这个过程中。我们呼吁所有对机器学习感兴趣的Swift开发者来共同贡献PR、错误报告或意见,共同改进这个项目。
- 用DPO对Llama 2进行微调
- “NVIDIA H100 Tensor Core GPU 现已正式发布,用于新的 Microsoft Azure 虚拟机系列”
- “在NVIDIA Studio中进行内容创作,得益于新的专业GPU、AI工具、Omniverse和OpenUSD合作功能的增强”
我们开始吧!
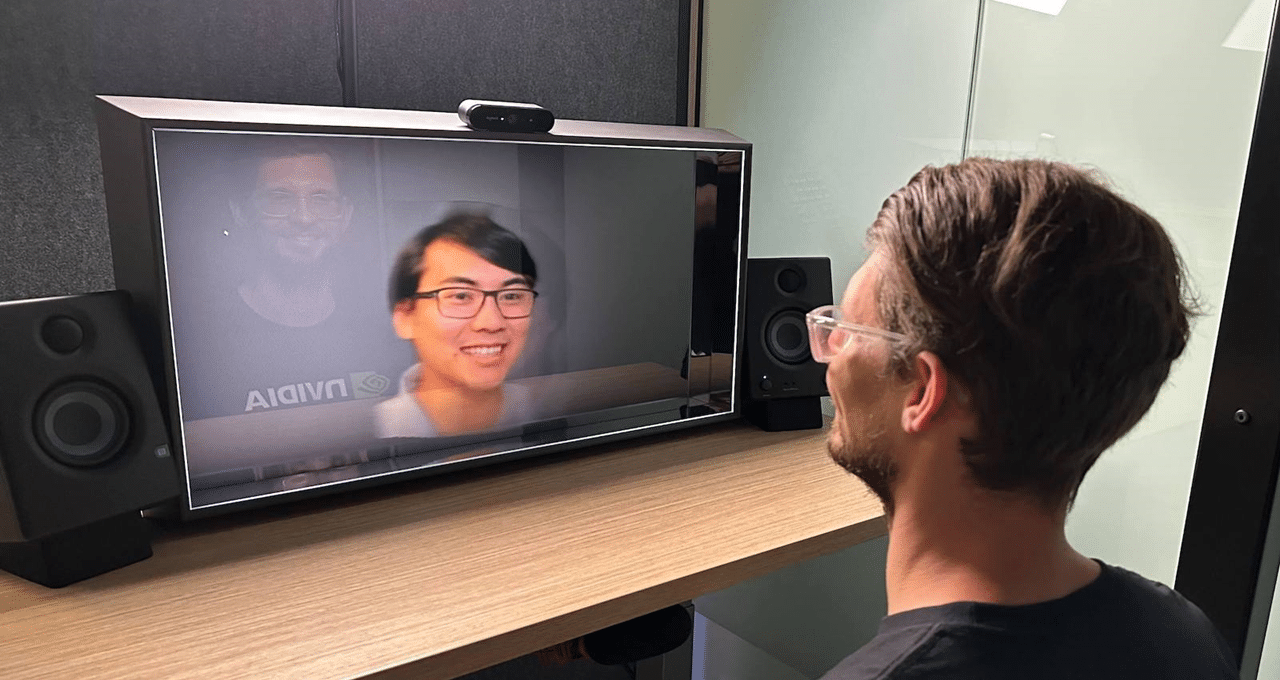
视频:在配备Core ML的M1 MacBook Pro上运行Llama 2 (7B)聊天模型。
今日发布
swift-transformers,一个正在开发中的Swift包,用于在Swift中实现类似transformers的API,重点是文本生成。它是swift-coreml-transformers的进化版,目标更广泛:集成Hub,支持任意的分词器,以及可插拔的模型。swift-chat,一个简单的应用程序,演示如何使用该包。exporters的更新版本,用于将transformers模型转换为Core ML的转换包。transformers-to-coreml的更新版本,一个基于exporters构建的无代码Core ML转换工具。- 一些已转换的模型,如Llama 2 7B或Falcon 7B,可与这些文本生成工具一起使用。
任务概述
当我发布展示Falcon或Llama 2在我的Mac上运行的推文时,其他开发者向我提出了许多问题,问如何将这些模型转换为Core ML,因为他们也想在他们的应用程序中使用它们。转换是一个关键的步骤,但只是谜题的第一部分。我编写这些应用程序的真正原因是面对任何其他开发者都会遇到的问题,并确定我们可以帮助的领域。在本文的其余部分,我们将介绍其中一些任务,解释我们在哪些任务上有工具可以帮助(以及在哪些任务上没有)。
- 转换为Core ML。我们将以Llama 2作为一个真实的例子。
- 优化技术,以使您的模型(和应用程序)运行速度快,内存消耗尽可能少。这是一个贯穿整个项目的领域,没有银弹解决方案可供应用。
swift-transformers,我们的新库,以帮助处理一些常见任务。- 分词器。分词是将文本输入转换为模型处理的实际数字集合(以及从生成的预测结果转换回文本)的方法。这比听起来复杂得多,因为有许多不同的选项和策略。
- 模型和Hub封装。如果我们想支持Hub上的各种模型,我们不能硬编码模型设置。我们创建了一个简单的
LanguageModel抽象和各种实用工具,用于从Hub下载模型和分词器配置文件。 - 生成算法。语言模型被训练成预测在一系列文字之后可能出现的下一个标记的概率分布。我们需要多次调用模型来生成文本输出,并在每一步选择一个标记。有许多方法可以决定我们应该选择哪个标记。
- 支持的模型。并非所有的模型系列都得到支持(但会有)。
swift-chat。这是一个简单的应用程序,演示如何在项目中使用swift-transformers。- 缺失的部分/即将推出。一些重要但尚不可用的内容,作为未来工作的方向。
- 资源。所有项目和工具的链接。
转换为Core ML
Core ML是Apple的原生机器学习框架,也是它使用的文件格式的名称。在将模型从(例如)PyTorch转换为Core ML之后,您可以在Swift应用程序中使用它。Core ML框架会自动选择最佳的硬件来运行您的模型:CPU、GPU或称为神经引擎的专用张量单元。根据您的系统特性和模型细节,还可以组合使用这些计算单元的几个。
为了看看在实际生活中转换模型是什么样子,我们将看看如何转换最近发布的Llama 2模型。这个过程有时可能很复杂,但我们提供了一些工具来帮助您。这些工具并不总是有效的,因为新模型不断推出,我们需要进行调整和修改。
我们推荐的方法是:
- 使用
transformers-to-coreml转换空间:
这是一个构建在exporters之上的自动化工具(见下文),它要么适用于您的模型,要么不适用。它不需要编码:输入Hub模型标识符,选择您计划使用该模型的任务,然后点击应用。如果转换成功,您可以将转换后的Core ML权重推送到Hub,然后完成!
您可以访问该空间或直接在此处使用:
- 使用
exporters,它是构建在苹果的coremltools之上的Python转换软件包(见下文)。
此库为您提供了更多配置转换任务的选项。此外,它还允许您创建自己的转换配置类,您可以使用它来进行额外的控制或解决转换问题。
- 使用苹果的转换软件包
coremltools。
这是最底层的方法,因此提供了最大的控制能力。对于某些模型(尤其是新模型),它可能仍然失败,但您始终可以选择深入源代码并尝试找出原因。
Llama 2的好消息是,我们已经完成了大量工作,并且转换过程可以使用这些方法中的任何一个。坏消息是,它在发布时无法转换,我们不得不做一些修复工作来支持它。我们在附录中简要介绍了发生了什么,这样您就可以对出现问题时该如何处理有所了解。
重要的经验教训
我已经按照最近的一些模型(Llama 2、Falcon、StarCoder)的转换过程,并将我所学到的应用于exporters和transformers-to-coreml空间。以下是一些要点总结:
- 如果您必须使用
coremltools,请使用最新版本:7.0b1。尽管从技术上说它是一个测试版,但我已经使用了几周,效果非常好:稳定,包含了许多修复程序,支持PyTorch 2,并且具有先进的量化工具等新功能。 exporters在转换文本生成任务时不再应用softmax。我们意识到这对于某些生成算法是必要的。exporters现在默认使用固定的序列长度来处理文本模型。Core ML有一种方法可以指定“灵活的形状”,这样您的输入序列可以在1到4096个标记之间具有任意长度。我们发现,灵活的输入只能在CPU上运行,而不能在GPU或神经引擎上运行。更多的调查即将到来!
我们将继续向我们的工具添加最佳实践,以便您不必再次发现相同的问题。
优化
如果在目标硬件上运行得不快且不符合系统资源的要求,那么将模型转换是没有意义的。本文提到的模型对于本地使用来说相当庞大,我们有意地使用它们来推动当前技术的极限,并了解瓶颈所在。
我们已经确定了一些关键的优化领域。它们对我们来说非常重要,并且是当前和即将进行的工作的主题。其中一些包括:
- 缓存先前生成的注意力键和值,就像PyTorch实现的transformers模型一样。到目前为止,注意力分数的计算需要在整个已生成序列上运行,但所有过去的键-值对已经在之前的运行中计算过了。我们目前没有为Core ML模型使用任何缓存机制,但计划这样做!
- 使用离散的形状而不是固定的小序列长度。不使用灵活的形状的主要原因是它们与GPU或神经引擎不兼容。其次,由于缺乏上述提到的缓存机制,随着序列长度的增长,生成速度会变慢。使用一组离散的固定形状,结合缓存键-值对,应该可以实现更大的上下文大小和更自然的聊天体验。
- 量化技术。我们已经在稳定扩散模型的背景下探索了这些技术,并对它们所带来的选项感到非常兴奋。例如,6位调色板化可以减小模型大小并且在资源上非常高效。混合位量化是一种新技术,可以在不对模型质量产生较大影响的情况下实现4位量化(平均值)。我们计划为语言模型的这些主题进行研究!
对于生产应用程序,考虑在开发过程中使用较小的模型进行迭代,然后应用优化技术选择尽可能小的模型以适应您的用例。
swift-transformers
swift-transformers是一个正在进行中的Swift软件包,旨在为Swift开发人员提供类似transformers的API。让我们看看它有哪些功能和缺少什么。
分词器
分词解决了两个互补的任务:将文本输入适应模型使用的张量格式,并将模型的结果转换回文本。这个过程是微妙的,例如:
- 我们使用单词、字符、字符组还是字节?
- 我们应该如何处理小写和大写字母?我们是否需要处理这种差异?
- 我们应该去除重复的字符,比如空格,还是它们很重要?
- 我们如何处理模型词汇表中没有的单词?
有一些通用的分词算法,以及许多不同的规范化和预处理步骤对于有效使用模型至关重要。transformers库决定将所有这些操作抽象在同一个库(tokenizers)中,并将决策表示为存储在Hub中的配置文件。例如,这是Llama 2分词器配置的摘录,描述了规范化步骤:
"normalizer": {
"type": "Sequence",
"normalizers": [
{
"type": "Prepend",
"prepend": "▁"
},
{
"type": "Replace",
"pattern": {
"String": " "
},
"content": "▁"
}
]
},它的意思是:规范化是按顺序应用的一系列操作。首先,我们在输入字符串前面Prepend字符_。然后我们用_替换所有的空格。有一个巨大的操作列表,它们可以应用于正则表达式匹配,并且必须按照非常特定的顺序执行。tokenizers库中的代码负责处理Hub中所有模型的所有这些细节。
相比之下,在其他领域(如Swift应用程序)中使用语言模型的项目通常会将这些决策硬编码为应用程序源代码的一部分。这对于一些模型来说还好,但是难以用不同的模型替换一个模型,并且很容易犯错。
我们在swift-transformers中所做的就是在Swift中复制这些抽象,这样我们只需编写一次,每个人都可以在他们的应用程序中使用它们。我们刚刚开始,所以覆盖范围还很小。请随时在存储库中提出问题或贡献您自己的内容!
具体来说,我们目前支持BPE(字节对编码)分词器,这是今天使用的三个主要方法之一。 GPT模型、Falcon和Llama都使用此方法。对于Unigram和WordPiece分词器的支持将在以后添加。我们还没有移植所有可能的规范化器、预分词器和后处理器,只移植了在转换Llama 2、Falcon和GPT模型过程中遇到的那些。
这是如何在Swift中使用Tokenizers模块:
import Tokenizers
func testTokenizer() async throws {
let tokenizer = try await AutoTokenizer.from(pretrained: "pcuenq/Llama-2-7b-chat-coreml")
let inputIds = tokenizer("Today she took a train to the West")
assert(inputIds == [1, 20628, 1183, 3614, 263, 7945, 304, 278, 3122])
}但是,通常情况下,您不需要自己对输入文本进行分词-Generation代码会处理它。
模型和Hub封装
如上所述,transformers广泛使用存储在Hub中的配置文件。我们准备了一个简单的Hub模块,用于从Hub下载配置文件,该模块用于实例化分词器并检索有关模型的元数据。
关于模型,我们创建了一个简单的LanguageModel类型作为Core ML模型的包装器,专注于文本生成任务。使用协议,我们可以使用相同的API查询任何模型。
为了检索您使用的模型的适当元数据,swift-transformers依赖于一些必须在转换时添加到Core ML文件中的自定义元数据字段。swift-transformers将使用此信息从Hub下载所有必要的配置文件。这些是我们使用的字段,如Xcode的模型预览所示:

如果您手动使用coremltools,请确保自己添加这些字段。
生成算法
语言模型训练用于预测可能作为输入序列继续的下一个令牌的概率分布。为了组成响应,我们需要多次调用模型,直到它产生一个特殊的终止令牌,或者达到我们期望的长度。有许多方法可以决定下一个最佳令牌的使用方式。我们目前支持其中两种:
- 贪婪解码。这是一种明显的算法:选择概率最高的令牌,将其附加到序列中,然后重复。这将始终为相同的输入序列产生相同的结果。
- top-k抽样。选择
top-k(其中k是一个参数)最可能的令牌,然后使用temperature等参数从中随机抽样,它会增加变异性,但可能导致模型走神并丧失内容的追踪能力。
其他方法,如“核心抽样”,将在以后推出。我们建议阅读这篇博文(最近更新)以了解生成方法以及它们的工作原理。辅助生成等复杂方法也可以非常有用于优化!
支持的模型
到目前为止,我们已经用一些模型对swift-transformers进行了测试,以验证主要的设计决策。我们期待尝试更多模型!
- Llama 2。
- Falcon。
- 基于GPT架构的StarCoder模型的变体。
- GPT系列,包括GPT2、distilgpt、GPT-NeoX、GPT-J。
swift-chat
swift-chat是一个简单的演示应用程序,构建在swift-transformers上。它的主要目的是展示如何在您的代码中使用swift-transformers,但也可以用作模型测试工具。
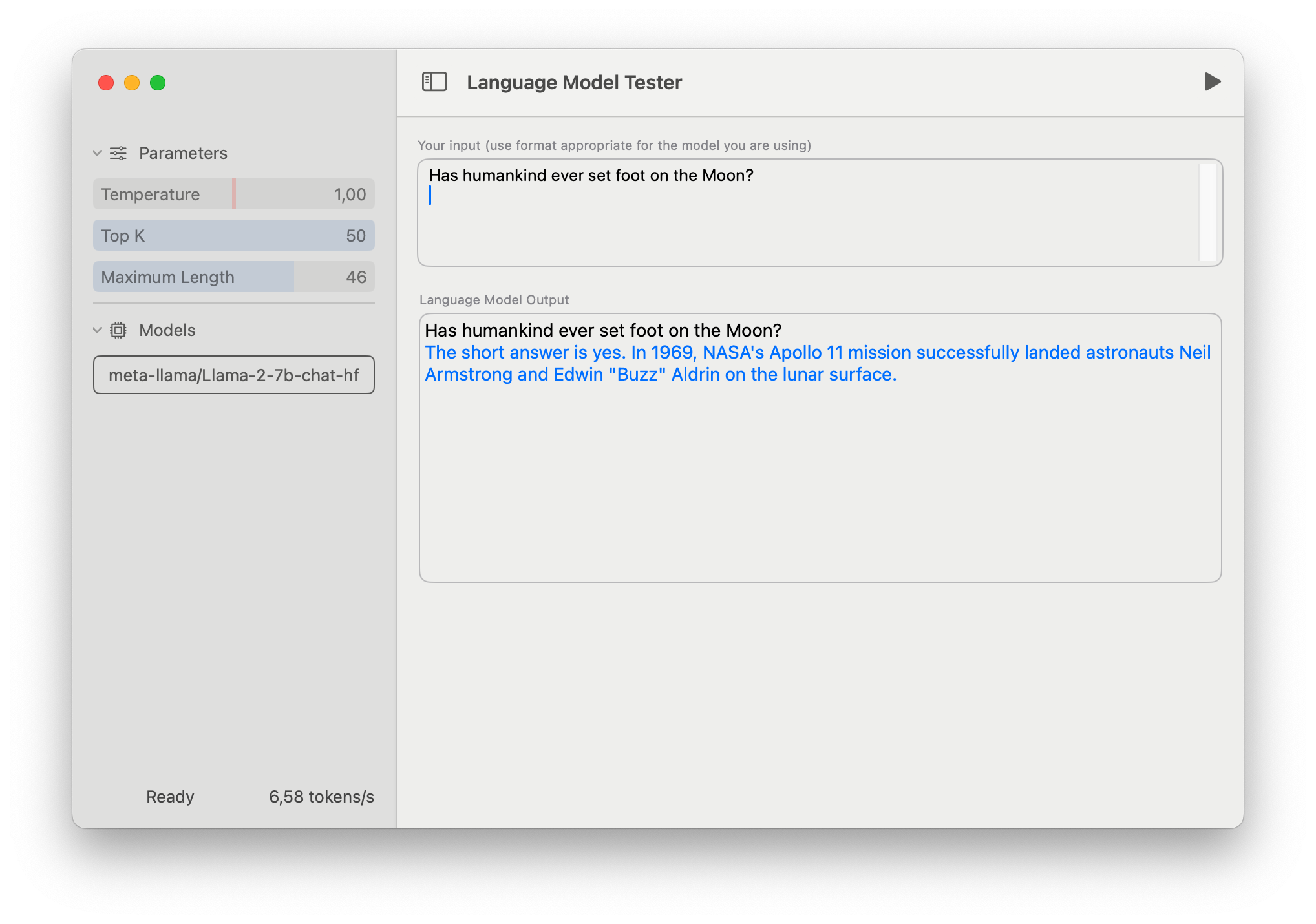
要使用它,请从Hub下载一个Core ML模型或创建您自己的模型,并从UI中选择它。所有相关的模型配置文件将从Hub下载,使用元数据信息来识别所使用的模型类型。
第一次加载新模型时,准备过程需要一些时间。在此阶段,CoreML框架将编译模型并根据您的机器规格和模型结构决定要在哪些计算设备上运行它。此信息将被缓存并在将来的运行中重用。
该应用程序故意保持简单,以使其易读和简洁。它还缺少一些功能,主要是由于模型上下文大小的当前限制。例如,它没有任何用于指定语言模型行为甚至其个性的“系统提示”的规定。
缺失的部分/接下来
正如所述,我们刚刚开始!我们即将优先考虑的事项包括:
- 编码器-解码器模型,例如T5和Flan。
- 更多的分词器:支持Unigram和WordPiece。
- 额外的生成算法。
- 支持键值缓存以进行优化。
- 使用离散的序列形状进行转换。与键值缓存一起,这将允许更大的上下文。
让我们知道您认为我们下一步应该做什么,或者转到Good First Issues的存储库尝试一下吧!
结论
我们推出了一套工具,帮助Swift开发者在他们的应用中使用语言模型。我迫不及待地想看到你们用它们创造出什么,我期待着与社区的帮助一起改进它们!不要犹豫,随时与我们联系:)
附录:以困难的方式将Llama 2转换
除非你遇到了Core ML转换问题并准备好解决:),否则你可以安全地忽略这一部分。
根据我的经验,PyTorch模型无法使用coremltools转换为Core ML的原因有两个:
- 不支持的PyTorch操作或操作变体
PyTorch有很多操作,它们都必须映射到中间表示(MIL,即模型中间语言),然后转换为原生Core ML指令。PyTorch操作的集合不是静态的,因此新的操作也必须添加到coremltools中。此外,一些操作非常复杂,可以在它们的参数的奇特组合上工作。最近添加的一个非常复杂的操作是缩放点积注意力,它在PyTorch 2中引入。部分支持的操作示例是einsum:并非所有可能的方程式都被转换为MIL。
- 边缘情况和类型不匹配
即使对于支持的PyTorch操作,确保转换过程在所有不同的输入类型上适用于所有可能的输入是非常困难的。请记住,单个PyTorch操作可以有多个不同设备(cpu,CUDA)、输入类型(整数,浮点数)或精度(float16,float32)的后端实现。所有组合的乘积是惊人的,有时候模型使用PyTorch代码的方式会触发一条可能未被考虑或测试过的转换路径。
这就是当我第一次尝试使用coremltools转换Llama 2时发生的情况:
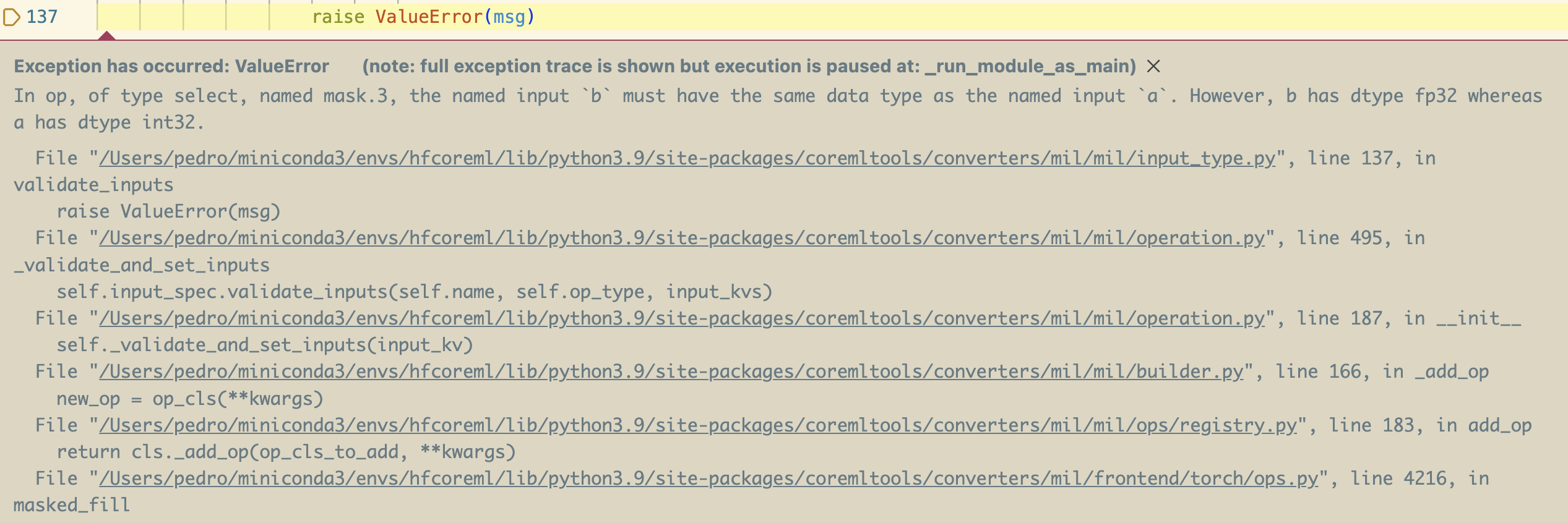
通过比较不同版本的transformers,我发现问题是在引入这行代码时开始发生的。这是最近的transformers重构的一部分,用于更好地处理所有使用到它们的模型中的因果掩码,因此这对于其他模型也是一个大问题,而不仅仅是对Llama。
错误截图告诉我们的是,试图填充掩码张量时存在类型不匹配。这是发生在该行中的0:它被解释为一个int,但要填充的张量包含floats,而使用不同类型的操作被转换过程拒绝了。在这种特殊情况下,我给coremltools提供了一个补丁,但幸运的是,这种情况很少发生。在许多情况下,您可以修补您的代码(在transformers的本地副本中使用0.0),或者创建一个用于处理特殊情况的“特殊操作”。我们的exporters库对自定义的特殊操作有很好的支持。请参阅此示例了解缺失的einsum方程式,或者参阅此示例以在新版本的coremltools发布之前使StarCoder模型正常工作的解决方法。
幸运的是,coremltools对于新操作的支持很好,团队反应也非常迅速。
资源
swift-transformers。swift-chat。exporters。transformers-to-coreml。- 一些用于文本生成的Core ML模型:
- Llama-2-7b-chat-coreml
- Falcon-7b-instruct