医疗人工智能的基础模型
医疗人工智能基础模型
介绍PLIP,一种病理学基础模型

引言
正在进行的AI革命为我们带来了各个方向的创新。OpenAI的GPT(s)模型引领着发展,并展示了基础模型实际上能够使我们的日常任务更加轻松。从帮助我们写作更好到简化我们的一些任务,每天我们都会看到新的模型被宣布。
我们面前有很多机会。在未来几年里,能够帮助我们工作的AI产品将成为我们最重要的工具之一。
我们将在哪些领域看到最有影响力的变化?我们在哪些领域可以帮助人们更快地完成任务?医疗AI工具是AI模型最令人兴奋的领域之一。
在这篇博文中,我将介绍PLIP(病理学语言和图像预训练)作为病理学的第一个基础模型之一。PLIP是一种视觉语言模型,可以将图像和文本嵌入到同一个向量空间中,从而实现多模态应用。PLIP基于OpenAI在2021年提出的原始CLIP模型,并最近发表在《自然医学》杂志上:
Huang, Z., Bianchi, F., Yuksekgonul, M., Montine, T., Zou, J., 基于医学Twitter的病理图像分析的视觉语言基础模型。2023年,《自然医学》。
在我们开始冒险之前,这里有一些有用的链接:
- HuggingFace权重;
- 《自然医学》论文;
- GitHub仓库。
对比预训练101
我们展示了通过在社交媒体上收集数据并使用一些额外的技巧,我们可以构建一个可以在医疗AI病理学任务中使用的模型,并取得良好的结果,而无需注释数据。
虽然介绍CLIP(PLIP的来源模型)及其对比损失超出了本博文的范围,但了解一些基本概念仍然是有益的。CLIP背后的非常简单的想法是,我们可以构建一个模型,将图像和文本放在一个向量空间中,其中“图像和它们的描述将会靠得很近”。
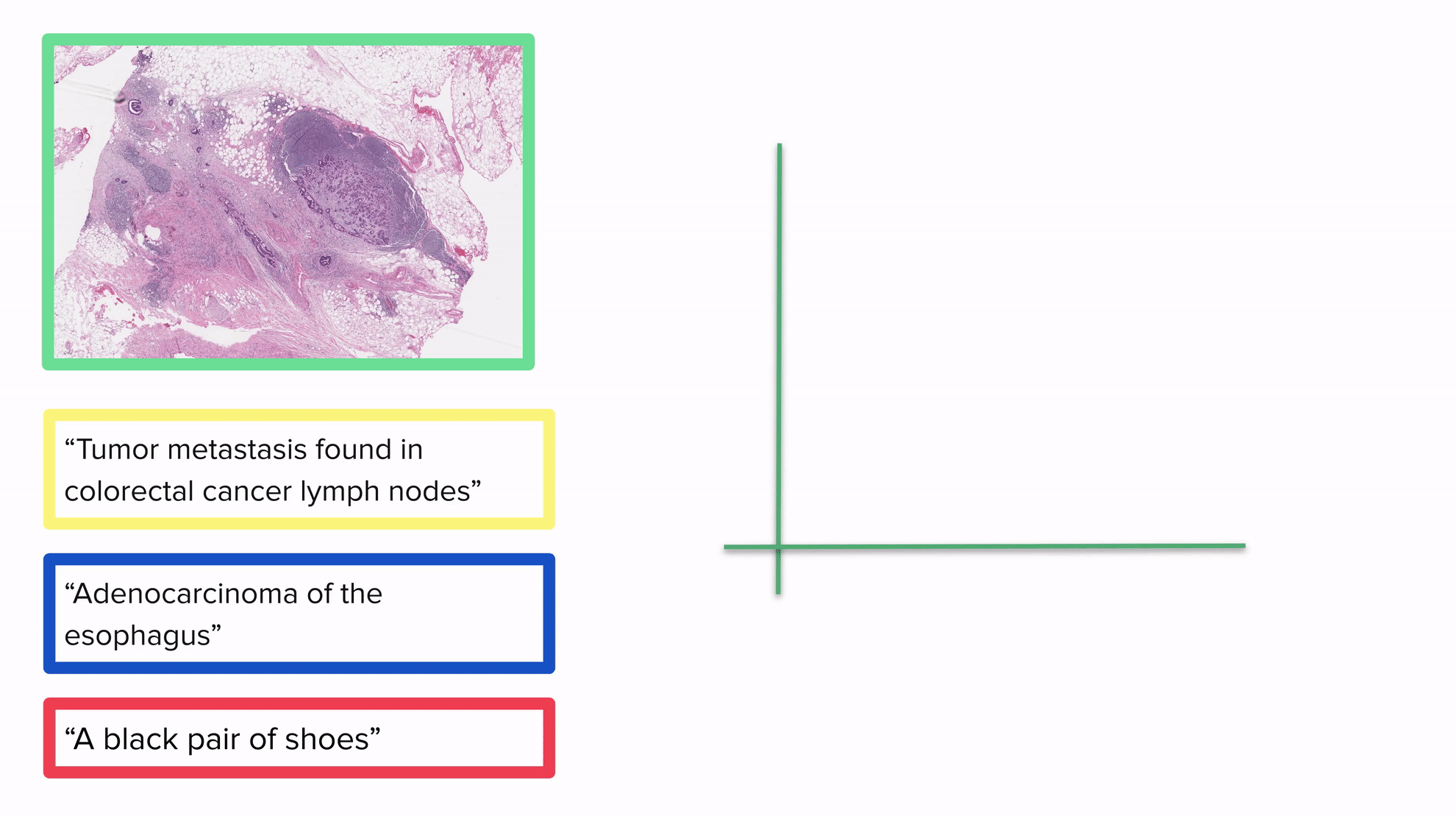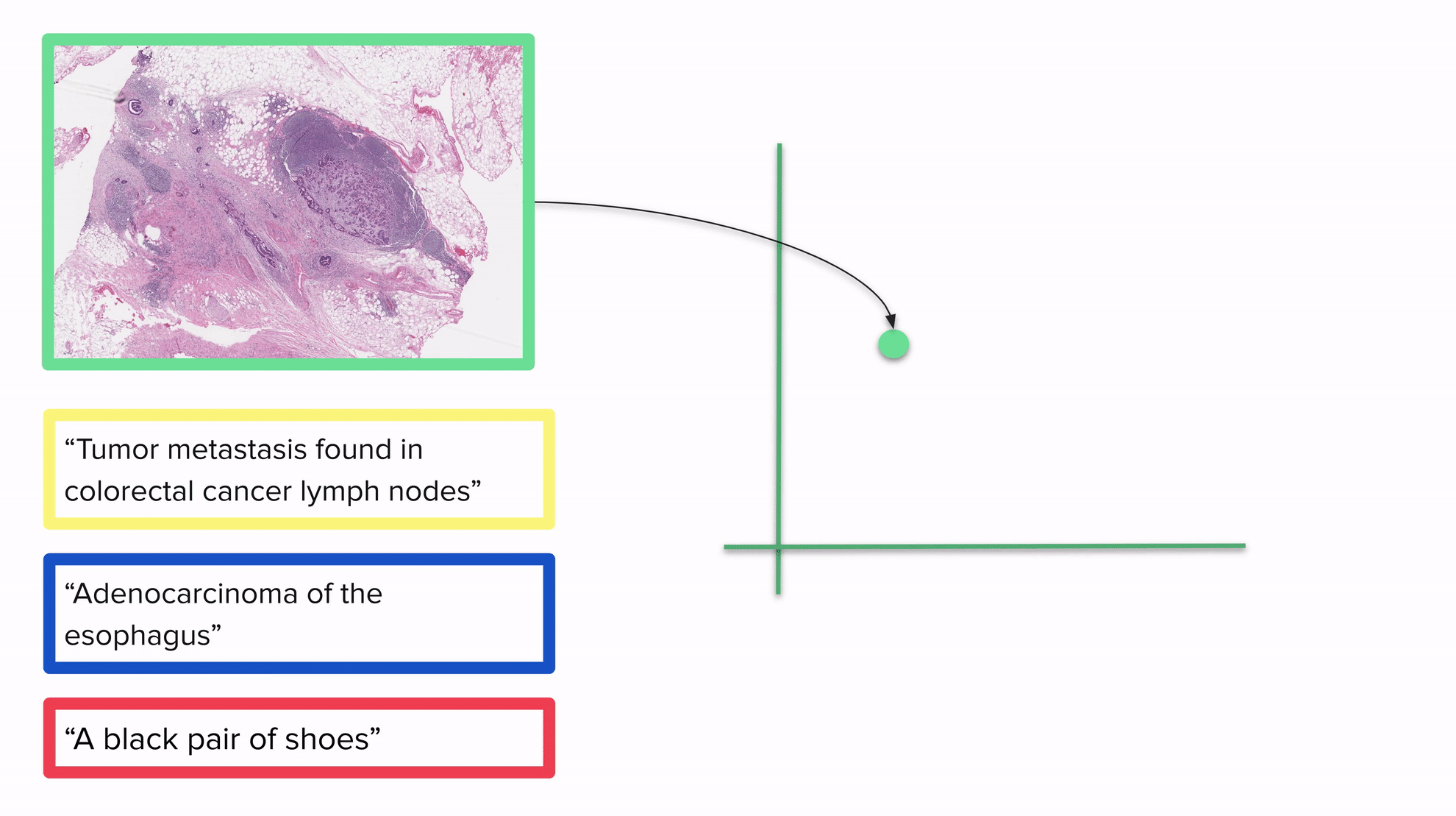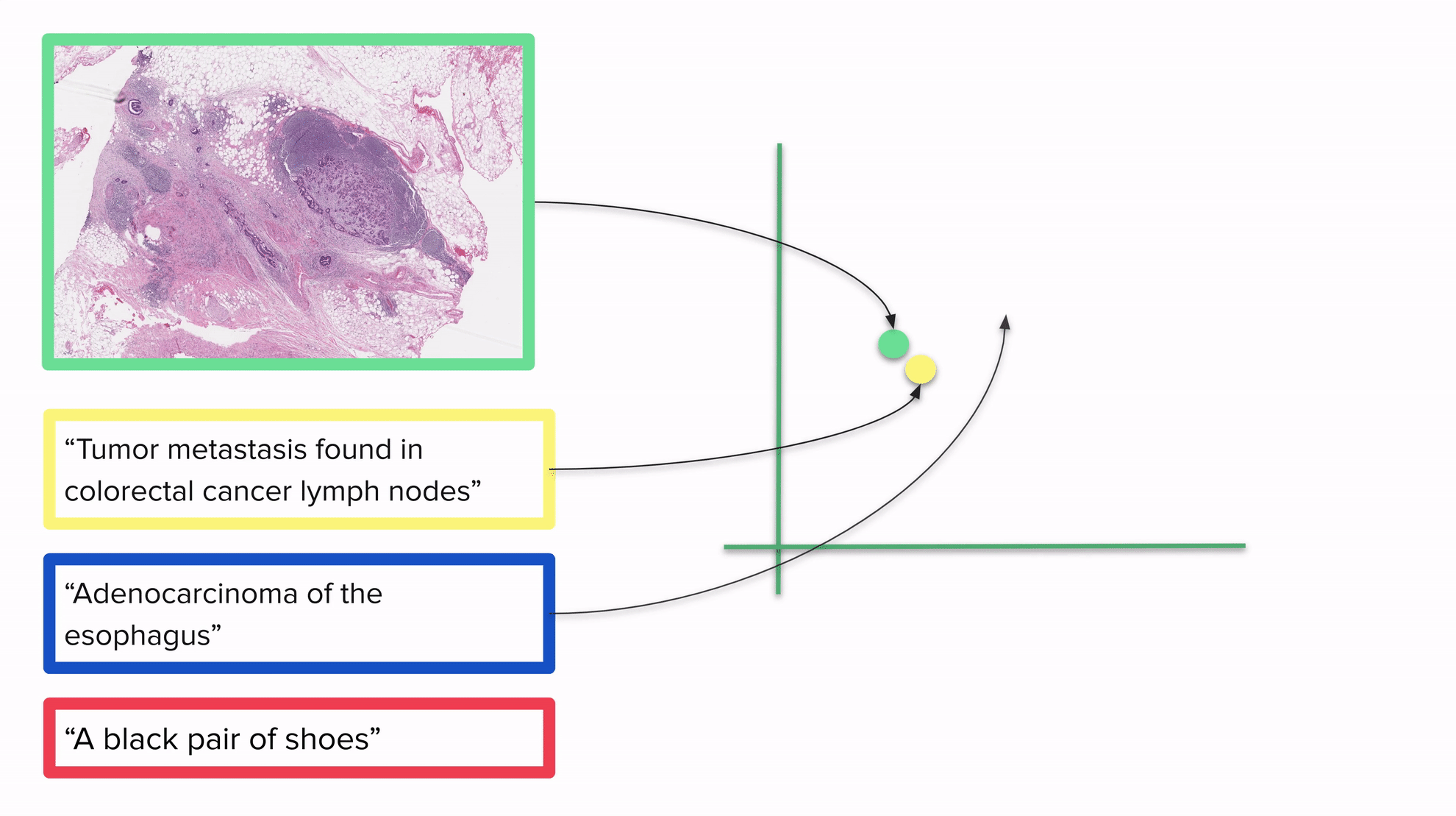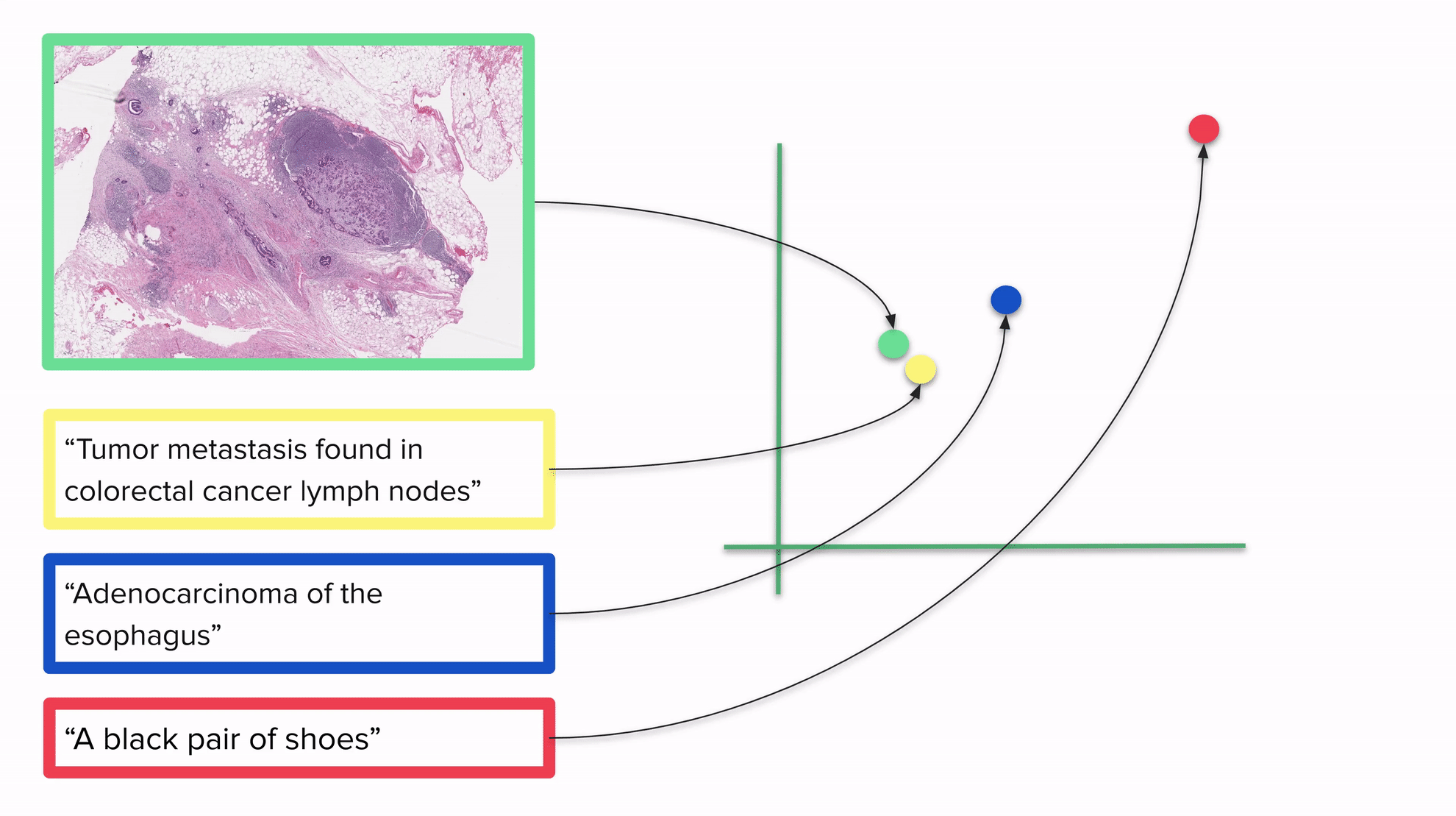
上面的GIF还展示了将图像和文本嵌入到同一个向量空间的模型如何用于分类:通过将所有内容放在同一个向量空间中,我们可以通过考虑向量空间中的距离将每个图像与一个或多个标签相关联:描述与图像越接近,结果越好。我们预期最接近的标签将是图像的真实标签。
需要明确的是:一旦CLIP训练完成,您可以嵌入任何图像或任何文本。请注意,该GIF显示的是一个二维空间,但通常CLIP使用的空间维度要高得多。
这意味着一旦图像和文本在同一个向量空间中,我们可以做很多事情:从零样本分类(找到与图像更相似的文本标签)到检索(找到与给定描述更相似的图像)。
我们如何训练CLIP?简单来说,模型被提供了很多图像-文本对,并试图将相似的匹配项放在一起(如上图所示),而将其余的项远离。您拥有的图像-文本对越多,您将学到的表示就越好。
我们将在这里介绍CLIP的背景,这应该足够理解本文的其余部分。我在Towards Data Science上有一篇更详细的关于CLIP的博文。
如何训练您的CLIP
CLIP介绍以及在HuggingFace社区周期间如何对其进行意大利语微调
towardsdatascience.com
CLIP已经训练成一个非常通用的图像-文本模型,但它在特定用例(例如时尚(Chia等人,2022))中的效果并不好,而且还有一些情况下CLIP表现不佳,特定领域的实现效果更好(Zhang等人,2023)。
病理语言和图像预训练(PLIP)
我们现在描述一下我们构建的PLIP,这是原始CLIP模型的经过微调的版本,专门用于病理学。
构建用于病理语言和图像预训练的数据集
我们需要数据,而且这些数据必须足够好,可以用来训练模型。问题是我们如何找到这些数据?我们需要具有相关描述的图像,就像我们在上面的GIF中看到的那样。
虽然网络上有大量的病理数据可用,但它经常缺少注释,并且可能是非标准格式,例如PDF文件、幻灯片或YouTube视频。
我们需要在其他地方寻找,这个其他地方将是社交媒体。通过利用社交媒体平台,我们可以潜在地访问丰富的与病理相关的内容。病理学家使用社交媒体在线共享他们自己的研究,并向同事提问问题(参见Isom等人,2017,关于病理学家如何使用社交媒体的讨论)。还有一组通常推荐的Twitter标签,病理学家可以使用这些标签进行沟通。
除了Twitter数据,我们还从LAION数据集(Schuhmann等人,2022)中收集了一部分图像,这是一个包含50亿个图像-文本对的庞大数据集。LAION是通过从网络上抓取数据来收集的,它是用来训练许多流行的OpenCLIP模型的数据集。
病理学Twitter
我们使用病理学Twitter标签收集了超过10万条推文。这个过程相当简单,我们使用API收集与一组特定标签相关的推文。我们删除包含问号的推文,因为这些推文通常包含对其他病例的请求(例如,“这是哪种肿瘤?”),而不是我们实际上可能需要构建模型的信息。

从LAION中采样
LAION包含50亿个图像-文本对,我们收集数据的计划如下:我们可以使用来自Twitter的自己的图像,并在这个大型语料库中找到相似的图像;这样,我们应该能够获得相当相似的图像,希望这些相似的图像也是病理图像。
现在,手动进行这个过程是不可行的,对50亿个嵌入进行搜索是非常耗时的任务。幸运的是,LAION有预先计算的向量索引,我们可以使用API将实际图像查询到它!因此,我们只需嵌入我们的图像,然后使用K-NN搜索在LAION中找到相似的图像。请记住,每个图像都有一个标题,这对于我们的用例来说非常完美。
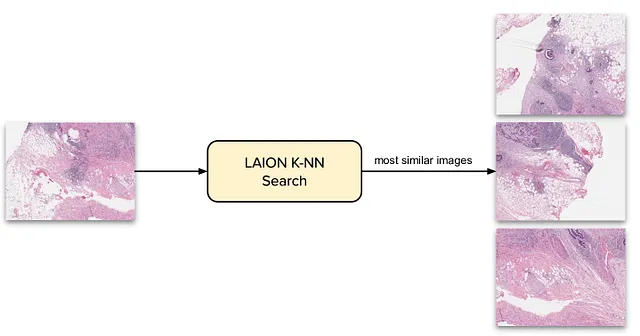
确保数据质量
并非我们收集的所有图像都是好的。例如,从Twitter上,我们收集了许多医学会议的合照。从LAION上,我们有时会得到一些类似分形的图像,它们模糊地类似于某种病理模式。
我们所做的非常简单:我们使用一些病理数据作为正类数据,使用ImageNet数据作为负类数据训练了一个分类器。这种分类器具有极高的精确度(实际上很容易区分出病理图像和网络上的随机图像)。
此外,对于LAION数据,我们还应用了一个英文语言分类器来删除非英文的示例。
训练病理语言和图像预训练
数据收集是最困难的部分。一旦完成并且我们信任我们的数据,我们就可以开始训练。
为了训练PLIP,我们使用了原始的OpenAI代码进行训练 – 我们实现了训练循环,添加了余弦退火损失,并在各个方面进行了一些调整,以确保一切都能平稳运行并且可以验证(例如,Comet ML跟踪)。
我们训练了很多不同的模型(数百个),并比较了参数和优化技术,最终,我们能够得到一个令我们满意的模型。关于这方面的更多细节可以在论文中找到,但在构建这种对比模型时,最重要的组成部分之一是确保在训练过程中批量大小尽可能大,这样模型可以学会尽可能多地区分元素。
医学人工智能的病理语言和图像预训练
现在是测试我们的PLIP的时候了。这个基础模型在标准基准测试中表现如何?
我们运行了不同的测试来评估我们的PLIP模型的性能。其中最有趣的三个是零样本分类、线性探测和检索,但我在这里主要关注前两个。为了简洁起见,我将忽略实验配置,但这些都可以在论文中找到。
PLIP作为零样本分类器
下面的GIF演示了如何使用像PLIP这样的模型进行零样本分类。我们使用点积作为向量空间中相似度的度量(值越高,越相似)。

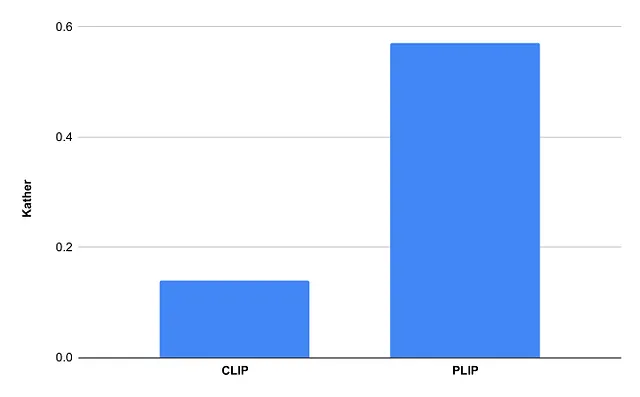
在下面的图中,您可以看到PLIP与CLIP在我们用于零样本分类的数据集上的快速比较。使用PLIP代替CLIP在性能方面有显著的提升。
PLIP作为线性探测的特征提取器
使用PLIP的另一种方式是将其用作病理图像的特征提取器。在训练过程中,PLIP会看到许多病理图像,并学习为它们构建向量嵌入。
假设你有一些注释数据,并且想要训练一个新的病理分类器。你可以使用PLIP提取图像嵌入,然后在这些嵌入之上训练一个逻辑回归(或者你喜欢的任何类型的回归器)。这是一种简单有效的执行分类任务的方法。
为什么这样做有效?这个想法是,为了训练一个分类器,PLIP嵌入应该比CLIP嵌入更好,因为PLIP嵌入是特定于病理学的,而CLIP嵌入是通用的。

这是CLIP和PLIP在两个数据集上性能比较的例子。虽然CLIP表现良好,但我们使用PLIP的结果要高得多。

使用病理语言和图像预训练
如何使用PLIP?下面是一些在Python中使用PLIP的示例以及可以用来玩一下模型的Streamlit演示。
代码:使用PLIP的API
我们的GitHub存储库提供了一些额外的示例供您参考。我们构建了一个API,可以让您轻松地与模型进行交互:
from plip.plip import PLIPimport numpy as npplip = PLIP('vinid/plip')# 我们创建图像嵌入和文本嵌入image_embeddings = plip.encode_images(images, batch_size=32)text_embeddings = plip.encode_text(texts, batch_size=32)# 我们将嵌入归一化为单位范数(这样我们可以使用点积而不是余弦相似度进行比较)image_embeddings = image_embeddings/np.linalg.norm(image_embeddings, ord=2, axis=-1, keepdims=True)text_embeddings = text_embeddings/np.linalg.norm(text_embeddings, ord=2, axis=-1, keepdims=True)您还可以使用更标准的HF API来加载和使用模型:
from PIL import Imagefrom transformers import CLIPProcessor, CLIPModelmodel = CLIPModel.from_pretrained("vinid/plip")processor = CLIPProcessor.from_pretrained("vinid/plip")image = Image.open("images/image1.jpg")inputs = processor(text=["a photo of label 1", "a photo of label 2"], images=image, return_tensors="pt", padding=True)outputs = model(**inputs)logits_per_image = outputs.logits_per_image probs = logits_per_image.softmax(dim=1) 演示:PLIP作为教育工具
我们还认为PLIP和未来的模型可以有效地用作医学人工智能的教育工具。PLIP允许用户进行零样本检索:用户可以搜索特定关键词,PLIP将尝试找到最相似/匹配的图像。我们在Streamlit中构建了一个简单的Web应用程序,您可以在这里找到。
结论
感谢您阅读全部内容!我们对这项技术的可能未来发展感到兴奋。
在结束这篇博文时,我将讨论一些PLIP的非常重要的限制,并提出一些我写过的可能会引起兴趣的其他事情。
限制
虽然我们的结果很有趣,但PLIP也有很多不同的限制。数据不足以学习病理学的所有复杂方面。我们已经构建了数据过滤器来确保数据质量,但我们需要更好的评估指标来了解模型做对了什么和模型做错了什么。
更重要的是,PLIP无法解决当前病理学面临的挑战;PLIP不是一个完美的工具,可能会出现许多需要调查的错误。我们所看到的结果确实是令人兴奋的,并为未来结合视觉和语言的病理学模型开辟了一系列可能性。然而,在我们能够看到这些工具在日常医学中使用之前,还有很多工作要做。
其他
我还有一些关于CLIP建模和CLIP限制的其他博文。例如:
教CLIP一些时尚
为时尚创建一个特定领域的CLIP模型
towardsdatascience.com
你的视觉语言模型可能只是一袋单词
我们在ICLR 2023的口头报告中探索视觉语言模型对语言的理解限制
towardsdatascience.com
参考文献
Chia, P.J., Attanasio, G., Bianchi, F., Terragni, S., Magalhães, A.R., Gonçalves, D., Greco, C., & Tagliabue, J. (2022). Contrastive language and vision learning of general fashion concepts. Scientific Reports, 12.
Isom, J.A., Walsh, M., & Gardner, J.M. (2017). Social Media and Pathology: Where Are We Now and Why Does it Matter? Advances in Anatomic Pathology.
Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C., Wightman, R., Cherti, M., Coombes, T., Katta, A., Mullis, C., Wortsman, M., Schramowski, P., Kundurthy, S., Crowson, K., Schmidt, L., Kaczmarczyk, R., & Jitsev, J. (2022). LAION-5B: An open large-scale dataset for training next generation image-text models. ArXiv, abs/2210.08402.
Zhang, S., Xu, Y., Usuyama, N., Bagga, J.K., Tinn, R., Preston, S., Rao, R.N., Wei, M., Valluri, N., Wong, C., Lungren, M.P., Naumann, T., & Poon, H. (2023). Large-Scale Domain-Specific Pretraining for Biomedical Vision-Language Processing. ArXiv, abs/2303.00915.






