使用Scikit-Learn进行集成学习:友好介绍
使用Scikit-Learn进行集成学习介绍
集成学习算法如XGBoost或随机森林是Kaggle竞赛中表现最好的模型之一。它们是如何工作的?

对于机器学习问题来说,基本学习算法如逻辑回归或线性回归通常过于简单,难以达到令人满意的结果。虽然使用神经网络是一种可能的解决方案,但它们需要大量的训练数据,而这种数据很少可用。集成学习技术可以提升简单模型的性能,即使只有有限的数据量。
想象一下让一个人猜一个大罐子里有多少颗软糖。一个人的答案不太可能是准确的估计值。相反,如果我们问一千个人同样的问题,平均答案很可能接近实际数字。这种现象被称为众包的智慧[1]。在处理复杂的估计任务时,群体的精度往往比个体更高。
集成学习算法通过聚合一组模型(如回归器或分类器)的预测结果来利用这个简单的原理。对于一组分类器的聚合模型,集成模型可以简单地选择低级分类器预测中最常见的类别。对于回归任务,集成可以使用所有预测的平均值或中位数。
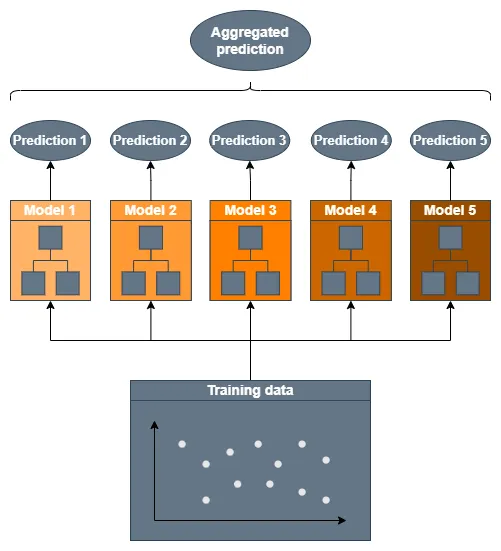
通过聚合大量的弱学习者,即仅比随机猜测略好的分类器或回归器,我们可以实现难以想象的结果。考虑一个二元分类任务。通过聚合1000个独立分类器,每个分类器的准确率为51%,我们可以创建一个准确率达到75%的集成模型[2]。
这就是为什么集成算法往往是许多机器学习竞赛中获胜的解决方案的原因!
有几种构建集成学习算法的技术。主要的技术有装袋法、提升法和堆叠法。在接下来的部分…





