使用React和Express构建一个由ChatGPT驱动和支持语音的助手
使用React和Express构建ChatGPT驱动的语音助手

随着大型语言模型在当今世界变得越来越流行,对其用于开发的兴趣也在增加,尽管弄清楚从何处开始并不总是容易的。
在本文中,我们将介绍如何构建一个由ChatGPT语言模型(在本例中为gpt-35-turbo)驱动的简单聊天机器人,作为了解这些模型如何在现实应用中实现的一种方式。我们将开发的聊天机器人将由一个简单的Web应用程序组成,主要使用TypeScript编写。我们将使用Azure OpenAI服务来访问模型,Azure AI Speech来启用语音到文本和文本到语音功能,使用Express服务器来处理API请求和聊天机器人与Azure服务之间的通信,最后使用React前端。
应用程序的快速演示。
GPT代表“生成式预训练转换器”。它是一个机器学习模型,它通过对大量文本数据进行训练来预测单词或短语在给定上下文中出现的可能性。GPT模型可用于各种自然语言处理任务,包括语言翻译、文本摘要和聊天机器人开发。而不是深入探讨这些模型的工作原理,我更愿意引导您阅读一篇由Beatriz Stollnitz撰写的深入文章,文章链接在这里。
该应用程序可以在此GitHub存储库中找到:github.com/gcordido/VoiceEnabledGPT,其中包含安装和运行应用程序的说明,有关提示编写和如何准备模型以获得准确结果的提示。
要开发此应用程序,我们首先必须考虑其“架构”,并回答以下问题:聊天机器人界面是什么样的?用户如何向机器人提供输入?应用程序如何与模型通信?输入将是什么样子?我们如何将信息从模型传递给用户?
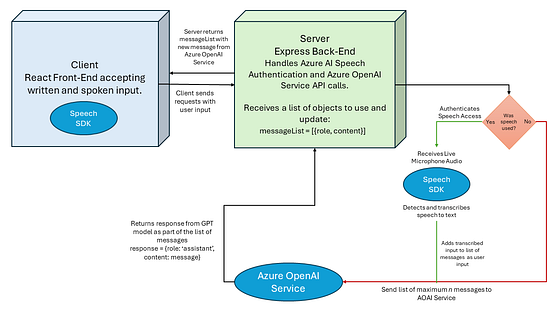
应用程序架构图
首先,让我们勾勒一下聊天窗口的外观。在这种情况下,我选择了一个典型的聊天界面,其中窗口显示一系列消息,用户的消息显示在右侧,聊天机器人的回复显示在左侧。为了实现这一点,我们使用一个React组件来渲染聊天界面,包括输入框、语音到文本按钮和可展开的聊天主体等元素。
应用程序与模型之间的通信是通过API实现的。Azure OpenAI服务通过通过REST API进行调用,并使用端点和API密钥的形式来访问这些模型。由于后者是机密信息,我们需要确保在进行API调用时不会泄露这些信息。因此,我们创建一个Express服务器来处理这些API请求。
一旦用户按下“发送”按钮,服务器将从主聊天机器人界面接收一个调用,并接收以将这些消息提供给模型的方式进行API调用的上一条消息列表。请注意,我说的是上一条消息列表,而不仅仅是最新的消息。这是有意的,因为GPT模型最有趣的特点之一是只要提供上下文,它就能在对话中保持上下文。该列表被编码为一个对象列表,每个对象具有两个属性:“角色”和“内容”。 “角色”属性区分用户和助手的消息,而“内容”属性仅包含消息文本。
现在定义了应用程序与GPT模型之间的通信过程,最后一步是添加音频支持。为此,我们使用Azure AI Speech,它为JavaScript提供了一个易于使用的SDK。该SDK提供了检测实时麦克风音频、识别语音和从文本合成语音的方法。
要从客户端访问Speech SDK及其方法,我们需要一个授权令牌。该令牌是通过在服务器端使用Azure AI Speech服务的API密钥和区域对我们的应用程序进行身份验证来生成的。获得令牌后,我们可以使用SDK中的SpeechRecognizer方法来检测和转录来自麦克风的音频。然后将此转录添加到我们的消息列表中作为用户输入,并以与书面输入相同的方式发送给服务器。
在生成回复后,模型的输出被发送回服务器上的聊天界面。助手角色的消息列表中添加了一个新条目,并且聊天窗口会根据新条目更新,显示聊天机器人的消息。然后,可以通过语音 SDK 的 SpeechSynthesizer 方法将该新条目传递,使应用程序能够通过扬声器朗读聊天机器人的回复。
虽然应用程序没有更进一步,但我们仍然有很多方法可以调整和修改与模型的通信方式以及它如何回应我们。
作为一个坚信通过实践学习的人,我强烈建议克隆存储库并尝试使用应用程序参数进行实验。例如,尝试将系统提示(初始指令)更改为让模型以散文或俳句回应,将语音合成器语言更改为西班牙语,或限制保留的上下文消息数量并观察模型的回应!
文章最初发布在此处。获得授权后重新发布。






