使用ChatGPT代码解释器分析人道主义数据的非结构化Excel表格
使用ChatGPT代码解释器分析非结构化Excel表格
使用代码解释器进行初步探索

TL;DR
新的实验性功能“代码解释器”为使用ChatGPT生成和运行Python代码提供本地支持。它显示出在数据工程和分析任务中具有巨大潜力,提供了一个对非技术用户可能使用的对话界面。本文对ChatGPT(GPT-4)代码解释器在我之前的博客文章中的一个非结构化Excel表格上进行了一些测试,以查看它能否自动将该表格转换为可加载到数据库中的更标准的形式。在有限的提示下,它能够识别出层次结构的标题结构,但无法生成能够准确解析表格的代码。在调整提示以建议使用openpyxl Python库提取有关Excel合并单元格的信息后,它能够在一次尝试中解析表格。然而,在重复相同的提示任务时,它失败了。由于目前无法控制温度参数以使结果更加确定性,代码解释器似乎无法始终处理这个特定任务。然而,这只是早期阶段,仅为测试功能,使用大型语言模型进行自动化数据处理的模式可能会持续存在,并且无疑会随着时间的推移而改进。
本周,ChatGPT发布了一个名为“代码解释器”的新功能,它允许ChatGPT生成和调用Python代码,并上传数据文件以执行数据分析等任务。正如我在之前的博客文章中探讨过的那样,大型语言模型有可能简化数据工程和分析任务。LangChain项目有一些很好的模式,并且在这个领域已经有很多商业活动,因此看到OpenAI开始提供本地支持是很有趣的。
已经有很多文章探索了OpenAI代码解释器,但我想知道它在使用我之前在人道数据交换(HDX)上发现的一些表格数据时表现如何。为HDX等平台提供自然语言界面使非技术用户能够探索和理解这些数据,这对于预测和加快人道灾害事件的响应时间具有影响。
获取Open AI的代码解释器访问权限
代码解释器是一个“Alpha”功能,目前处于早期测试阶段,不是ChatGPT的标准部分。要访问它,您需要:
- 成为ChatGPT+订阅者,每月费用为20美元
- 访问https://chat.openai.com/
- 在左下角的名称旁边选择“…”,然后选择“设置”
- 点击“Beta功能”并激活“代码解释器”
- 回到聊天窗口,在GPT-3.5或GPT-4上悬停并选择“代码解释器”
值得注意的是,最初您必须在OpenAI的插件等待列表中,但我不确定现在是否还是这样。尽管我没有收到通过列表获得访问权限的确认,但这些功能对我来说已经出现了。如果上述方法不起作用,您可能需要被添加进去。
分析Excel文件中的非结构化表格
正如之前的博客文章中提到的,Excel文件中的表格可能有各种形式的合并单元格、空行和其他使自动处理变得有点困难的因素。对于本文,我决定尝试使用GPT-4和代码解释器来分析一个在人道数据交换(HDX)上找到的典型的Excel表格……
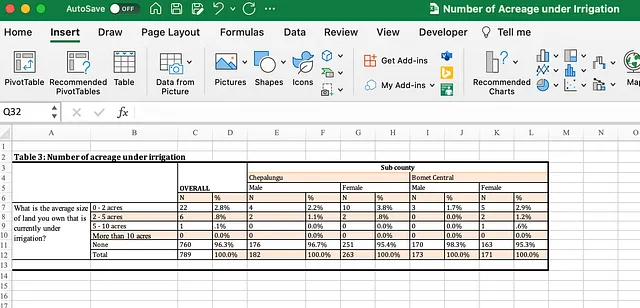
尽管代码解释器可以访问开放数据集,但它尚未包含HDX,并且无法访问互联网。我预计这很快会发生变化,但与此同时,我下载了该文件,按照上述描述在https://chat.openai.com/上启动了一个会话,然后通过在聊天输入框中点击“+”来上传了该文件…

上传后,ChatGPT立即加载数据到Python Pandas并进行一些初步分析…

它立即发现表格中的数据有些不规则,并立即尝试解决这个问题…

这实际上是正确的。实际上,它还继续问道…

我回答道…

你还可以通过在每个回答下选择“显示工作”下拉菜单来查看它是如何得出这个结论的,该菜单提供了生成的Python代码和结果…

它的方法似乎是合理的,但值得注意的是,它不使用关于合并单元格的本地Excel信息,而是直接加载到Pandas中。
ChatGPT开始工作并自动开始处理数据…

但它立即失败了。在选择“显示工作”后,我们可以看到它生成了一些解析表格的Python代码…
# 删除不需要的行
data = data.drop([0, 1])
# 重置索引
data = data.reset_index(drop=True)
# 定义土地大小类别
land_sizes = data.iloc[:, 1].values
# 初始化空列表以容纳整理后的数据
sub_counties = []
genders = []
land_sizes_tidy = []
numbers = []
percentages = []
# 遍历子县和性别
for i in range(4, data.shape[1], 2):
sub_county = data.columns[i].split(' ')[0]
gender = data.columns[i].split(' ')[1]
# 遍历土地大小类别
for j in range(len(land_sizes)):
land_size = land_sizes[j]
number = data.iloc[j, i]
percentage = data.iloc[j, i + 1]
# 将值添加到列表中
sub_counties.append(sub_county)
genders.append(gender)
land_sizes_tidy.append(land_size)
numbers.append(number)
percentages.append(percentage)
# 创建整理后的数据框
tidy_data = pd.DataFrame({
'子县': sub_counties,
'性别': genders,
'土地大小': land_sizes_tidy,
'数量': numbers,
'百分比': percentages
})
tidy_data但这导致了一个边界错误…

ChatGPT不会放弃,并自动开始调试…

这一点相当令人印象深刻,因为它似乎正确地识别出了问题。然而,令人印象不佳的是,它在对话的一开始已经准确地识别出了确切的列层次结构,但似乎“丢失”了这些信息。
再次,它重新回到事情中并自动进行下去…

这样就得到了一个带有如下标题的表格…

在这里,我们看到数据包含在列标题中,表明它没有识别出列结束和数据开始的位置。实际上,它甚至注意到了这一点,并勇敢地继续…
在这一点上,它陷入了一种困惑的状态,在这里尝试了很多在这里没有显示的循环中的东西。
最终,我认为标记限制被突破,生成停止,表格看起来像这样…

通过在“显示工作”输出中对上述值进行抽查,与原始表格进行比较,我们发现对于最后一行“Total”来说,值看起来是正确的,但有两个“Bomet Central Femail N Bomet”列标题。它注意到了这一点…

由于它似乎离成功很近,我要求ChatGPT继续…

我在请求它继续之前等了一会儿,我怀疑代码环境作业被终止了。它似乎很乐意重新开始这个过程,但在这样做时丢失了一些变量…

我按照提示重新上传了文件,然后它继续进行。最终,它生成了这个表格…
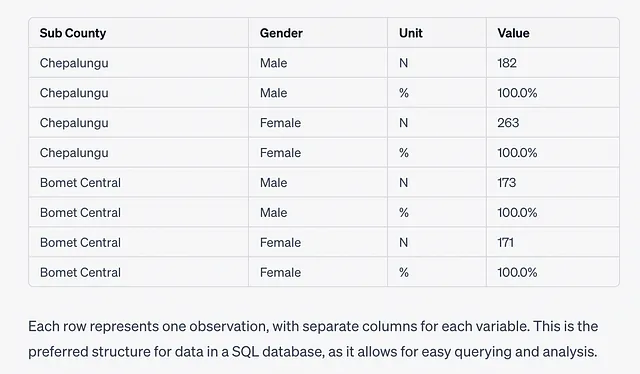
这很棒…只对应原始表格中的“Total”行。ChatGPT丢失了所有其他根据面积划分的数据行,所以实际上解析失败了。
我指出它实际上缺少一个与土地面积相关的列,这实际上是在第一次上传后立即识别出来的…

这时,ChatGPT开始了另一个任务,通过多次尝试解析表格,但最终都没有成功。完整的聊天链接可以在这里找到。
我开始了一个全新的聊天会话,再次尝试,结果得到了不同的结果,这对于这种技术的可重复性有影响。但无论我如何努力,结果都从未正确。
给ChatGPT一些编码建议
在我之前的博客文章中,通过使用从Excel中提取的信息来指示哪些单元格已合并,我能够在解析类似提供的示例的表格时取得最大的成功。这对于理解表格标题层次结构和我们人类在查看Excel表格时使用的内容非常重要。如果仅使用Pandas Excel解析 – 这是ChatGPT在我们的测试中所做的 – 而不是逐个单元格地询问Excel结构,这些信息就会丢失,这样成功解析具有合并标题单元格的表格会更加困难。
那么,如果我们给ChatGPT一个提示,让它直接使用’openpyxl’并考虑合并单元格呢?

就像上次一样,它一开始就做得很对…

然后继续进行分析…

然而,这次提供了一些关于技术的指导…它几乎完美地展开了表格,只需上面的一个提示,不需要进一步的干预。

唯一的问题是最后一行,但通过进一步的提示,我们可以轻松地去除它。要查看完整的交互和生成的代码,请参见此处。
我要求ChatGPT生成完整的代码,看看它最终得出了什么…

from openpyxl import load_workbookimport pandas as pd# 加载工作簿wb = load_workbook(filename='/mnt/data/Number of Acreage under Irrigation.xlsx')ws = wb.activedata = ws.valuesdata = list(data)# 将元组转换为列表data = [list(row) for row in data]# 处理第一列和第二列中的空值的函数def handle_none(data): last_valid = [None, None] for row in data: for i in range(2): if row[i] is not None: last_valid[i] = row[i] else: row[i] = last_valid[i] return datadata_filled = handle_none(data)# 构造标题headers = [None] * len(data_filled[0])for row in data_filled[2:6]: for i, value in enumerate(row): if value is not None: if headers[i] is None: headers[i] = value else: headers[i] += '_' + value# 调整前两个标题headers[0] = 'Question'headers[1] = 'Category'# 调整'%'标题for i in range(len(headers)): if headers[i] == '%': headers[i] = headers[i-1].rsplit('_', 1)[0] + '_%'# 调整'Female_N'和'Female_%'标题headers[6] = 'Sub county_Chepalungu_Female_N'headers[7] = 'Sub county_Chepalungu_Female_%'headers[10] = 'Bomet Central_Female_N'headers[11] = 'Bomet Central_Female_%'# 创建DataFramedf = pd.DataFrame(data_filled[6:], columns=headers)# 将DataFrame保存为CSV文件df.to_csv('/mnt/data/Number_of_Acreage_under_Irrigation_SQL.csv', index=False)这似乎是合理的。它不是通用的,其中有针对正在处理的文件的特定行。我怀疑我们需要更多的提示来(或许)让ChaGPT生成通用的代码,但对于这个研究中的任务,它能够很好地解析非结构化的表格。
很好的结果!
鉴于在第一次测试中ChatGPT对相同的提示给出了不同的结果,我决定重复完全相同的成功提示,看看在成功的测试中情况如何。可悲的是,它使用完全相同的提示给出了一个完全不同且不正确的答案。
结果并不理想!
在API中,通过降低温度参数,可以使模型更加确定性,并产生可重复的结果。但由于代码解释器目前尚不可用于API,我无法进行相关实验。
结论
尽管最初失败了,但我们成功地通过提供关于如何在Python中完成此任务的一些编码提示,使ChatGPT能够正确解析一个非结构化表格,这实际上是一个非常惊人的结果。然而,重复相同提示的结果是无法复现的,这很可能是因为在这个测试版功能中我们尚无法控制模型的温度参数。
还有一个有趣的限制是当超过令牌限制并且完成在任务完成之前停止时,需要另一个提示来继续。此外,ChatGPT在尝试不同代码块的迭代中非常缓慢。目前它还不适用于需要快速响应的任务。
基本上,代码解释器看起来令人印象深刻,显示出巨大的潜力,但在上述尝试的任务中似乎还不准备好。
所以至少现在,在与ChatGPT的竞争中,我占上风了。😊






