使用模仿学习创建交互式代理
使用模仿学习创建交互式代理
人类是一种互动的物种。我们与物理世界和彼此互动。为了使人工智能(AI)能够普遍有用,它必须能够与人类及其环境进行有效的互动。在这项工作中,我们提出了多模交互代理(MIA),它通过融合视觉感知、语言理解和生成、导航和操作,与人类进行延续且常常令人惊讶的物理和语言互动。

我们基于Abramson等人(2020)提出的方法进行改进,该方法主要使用模仿学习来训练代理。训练之后,MIA展示了一些基本的智能行为,我们希望能够通过人类反馈进一步完善。这项工作侧重于创建这种智能行为的先验知识,进一步的基于反馈的学习留待将来的工作。
我们创建了Playhouse环境,这是一个由随机组合的房间和大量家庭可交互物体构成的3D虚拟环境,为人类和代理提供了一个共同互动的空间和背景。人类和代理可以通过控制虚拟机器人在Playhouse中互动,进行位置移动、物体操作和文本通信。这个虚拟环境允许进行各种具体对话,从简单的指令(例如,“请从地板上拿起书放在蓝色书架上”)到创造性的游戏(例如,“把食物拿到桌子上,我们可以一起吃”)。
我们使用语言游戏收集了Playhouse互动的人类示例,这些语言游戏是一系列提示人类即兴表演特定行为的线索。在语言游戏中,一个玩家(设置者)收到一个预先编写的提示,指示提议给另一个玩家(解决者)一种任务。例如,设置者可能收到提示“问另一个玩家一个关于物体存在的问题”,经过一些探索后,设置者可以问:“请告诉我是否有一个蓝色的鸭子在一个没有任何家具的房间里。”为了确保行为多样性,我们还包括了自由形式的提示,允许设置者自由选择即兴互动(例如,“现在选择你喜欢的任何物体,用它打台上的网球球,使其滚到靠近时钟的地方,或者靠近它的某个地方。”)。总共,我们在Playhouse中收集了2.94年的实时人类互动数据。
.jpg)
我们的训练策略是人类行为的监督预测(行为克隆)和自我监督学习的组合。在预测人类行为时,我们发现使用分层控制策略可以显著提高代理的性能。在这种设置下,代理每秒接收大约4次新的观测。对于每个观测,它产生一系列开环移动动作,并可选择发出一系列语言动作。除了行为克隆外,我们还使用一种形式的自我监督学习,这种学习任务要求代理对某些视觉和语言输入进行分类,判断它们是否属于相同的情节还是不同的情节。
为了评估代理的性能,我们要求人类参与者与代理进行互动,并提供二进制反馈,指示代理是否成功执行了指令。MIA在人类评级的在线互动中实现了超过70%的成功率,相当于人类自己作为解决者时的成功率的75%。为了更好地理解MIA中各个组件的作用,我们进行了一系列消融实验,例如删除视觉或语言输入、自我监督损失或分层控制。
当代机器学习研究揭示了在不同规模参数方面的性能的显著规律;特别是,模型性能随着数据集大小、模型大小和计算能力呈幂律关系。这些效应在语言领域最为明显,该领域的特点是具有大规模的数据集和高度进化的架构和训练协议。然而,在这项工作中,我们处于一个完全不同的领域——具有相对较小的数据集和多模态、多任务目标函数训练的异构架构。尽管如此,我们证明了缩放效应的明显影响:随着数据集和模型大小的增加,性能显著提高。
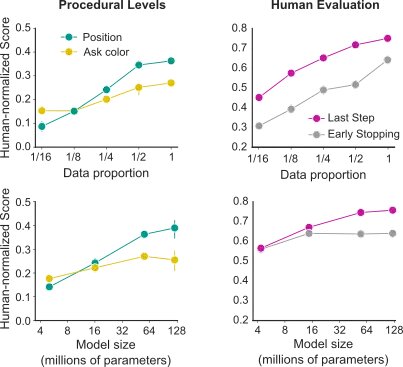
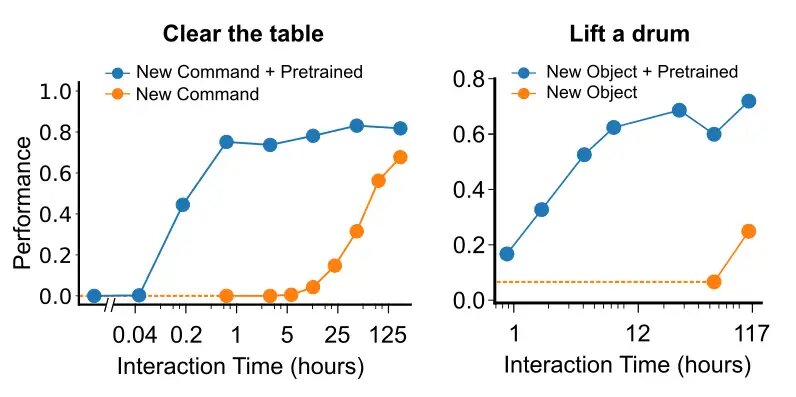
在理想情况下,通过一个相当大的数据集,训练变得更加高效,因为知识在经验之间得以传递。为了探究我们的情况有多理想,我们研究了学习与一个新的、以前未见过的物体进行交互以及学习如何遵循一个新的、以前未听过的指令/动词所需的数据量。我们将数据分成了背景数据和涉及对物体或动词的语言指令的数据。当我们重新引入涉及新物体的数据时,我们发现少于12小时的人类交互就足以达到顶尖表现。类似地,当我们引入新的指令或动词“清除”(即从表面上清除所有物体)时,我们发现只需要1小时的人类示范就足以在涉及这个词的任务中达到顶尖表现。
MIA表现出令人惊讶的丰富行为,包括研究人员之前没有预设的多样行为,例如整理房间、找到多个指定的物体以及在指令模糊时提出澄清问题。这些互动不断地激发我们的灵感。然而,MIA行为的开放性对于定量评估来说存在巨大的挑战。开发全面的方法来捕捉和分析人-代理之间的开放性行为将成为我们未来工作的重要焦点。
要获取我们工作的更详细描述,请参阅我们的论文。






