使用还是不使用机器学习
使用机器学习与否
如何判断使用机器学习是否是一个好主意,以及随着GenAI的进展这个问题是如何改变的

机器学习在解决某些复杂问题方面表现出色,通常涉及到特征和结果之间的复杂关系,这些关系无法简单地编码为启发式规则或if-else语句。然而,在决定是否使用ML解决特定问题时,需要考虑一些限制或事项。在本文中,我们将深入探讨“使用还是不使用ML”这个主题,首先了解对于“传统”ML模型来说如何使用,然后讨论随着生成式AI的进展,这个情况是如何改变的。
为了阐明一些观点,我将以以下倡议为例:“作为一家公司,我想知道我的客户是否满意以及不满意的主要原因”。解决这个问题的“传统”ML方法可能是:
- 获取客户对你的评论(应用程序或应用商店、Twitter或其他社交网络、你的网站…)
- 使用情感分析模型将评论分类为积极/中立/消极。
- 对预测的“消极情感”评论使用主题建模来理解它们的内容。

我的数据质量和数量是否足够?
在监督式ML模型中,训练数据对于模型学习需要预测的内容(在本例中是评论的情感)是必要的。如果数据质量低(大量的拼写错误、缺失数据、错误等),模型的表现将非常困难。
这通常被称为“垃圾进,垃圾出”问题:如果你的数据是垃圾,你的模型和预测也将是垃圾。
同样,你需要有足够的数据量让模型学习影响需要预测的不同情况。在这个例子中,如果你只有一个带有“无用”、“失望”或类似概念的负面评论样本,模型将无法学习到这些词语通常在标签为“消极”时出现。
足够的训练数据量还应该有助于确保你拥有对所需进行预测的数据的良好表示。例如,如果你的训练数据没有特定地理区域或特定人群段的代表性,那么模型在预测时很可能无法良好地执行。
对于某些用例,拥有足够的历史数据也是相关的,以确保我们能够计算相关的滞后特征或标签(例如“客户在下一年是否还款”)。
标签是否清晰定义且易于获得?
同样地,对于传统的监督式ML模型,你需要一个带有标签的数据集:你知道你要预测的最终结果的例子,以便训练你的模型。
标签的定义是关键。在这个例子中,我们的标签将是与评论相关联的情感。我们可能认为我们只能有“积极”或“消极”的评论,然后争论我们可能也有“中立”的评论。在这种情况下,对于给定的评论,是否很容易判断它是“积极”还是“非常积极”?需要避免对标签的定义不明确,因为训练时使用有噪声的标签会使模型更难学习。
现在,标签的定义已经清楚了,我们需要能够获取一组足够且质量良好的示例的标签,这些示例将构成我们的训练数据。在我们的例子中,我们可以考虑手动标记一组评论,无论是在公司或团队内部进行,还是将标记外包给专业注释者(是的,有些人全职为机器学习标记数据集!)。需要考虑与获取这些标签相关的成本和可行性。
解决方案的部署是否可行?
为了达到最终的影响,机器学习模型的预测结果需要可用。根据使用情况,使用预测结果可能需要特定的基础设施(例如机器学习平台)和专家(例如机器学习工程师)。
在我们的例子中,由于我们希望将模型用于分析目的,我们可以离线运行它,并且利用预测结果将会相当简单。然而,如果我们希望在下一5分钟内自动回复一条负面评论,这就是另外一回事了:模型需要被部署和集成以实现这一点。总的来说,清楚地了解使用预测结果所需的要求非常重要,以确保与团队和可用工具的可行性。
这其中有什么风险?
机器学习模型的预测结果总会存在一定的误差。事实上,在机器学习中,经典的说法是:
如果模型没有错误,那么数据或模型肯定出了问题
这一点很重要,因为如果使用情况不允许出现这些错误,那么使用机器学习可能不是一个好主意。在我们的例子中,想象一下,如果我们使用模型将客户的电子邮件分类为“提起诉讼”或“不提起诉讼”,那么拥有一个可能会错误分类对公司产生严重后果的模型就不是一个好主意。
使用机器学习是否符合道德要求?
已经有许多证实的预测模型基于性别、种族和其他敏感个人属性进行歧视。因此,机器学习团队在他们的项目中需要注意使用的数据和特征,并质疑从伦理角度来看是否有必要自动化某些类型的决策。您可以查看我之前的博客文章,了解更多详细信息。
我是否需要解释能力?
机器学习模型有点像黑匣子:你输入一些信息,它们就会神奇地输出预测结果。模型背后的复杂性就是这个黑匣子的原因,尤其是与统计学中的简单算法相比。在我们的例子中,我们可能无法准确理解为什么一个评论被预测为“积极”或“消极”,这可能没关系。
在其他用例中,解释能力可能是必需的。例如,在像保险或银行这样受严格监管的行业中,银行需要能够解释为什么会(或不会)向某个人授予信贷,即使这个决策是基于一个评分预测模型。
这个话题与伦理问题有着密切的关系:如果我们无法完全理解模型的决策,就很难知道模型是否学会了歧视性行为。
随着生成式人工智能的发展,所有这些都在发生变化吗?
随着生成式人工智能的进展,许多公司正在提供网页和API来使用强大的模型。这是否改变了我之前提到的关于机器学习的限制和考虑?
- 与数据相关的主题(质量、数量和标签):对于可以利用现有的生成式人工智能模型的用例来说,这肯定是在改变的。巨大的数据量已经被用于训练生成式人工智能模型。这些模型中大部分数据的质量尚未得到控制,但这似乎通过使用大量的数据来弥补。由于这些模型,也许(再次强调,针对非常特定的用例),我们不再需要训练数据。这被称为零样本学习(例如,“询问ChatGPT给定评论的情感是什么”)和少样本学习(例如,“提供一些正面、中性和负面评论的示例给ChatGPT,然后要求它为一条新评论提供情感)”。关于这个问题,在deeplearning.ai的新闻通讯中有一个很好的解释。
- 部署的可行性:对于可以利用现有的生成式人工智能模型的用例来说,部署变得更加容易,因为许多公司和工具提供了易于使用的API来访问这些强大的模型。如果这些模型需要进行微调或因隐私原因而引入公司内部,那么部署当然会变得更加困难。
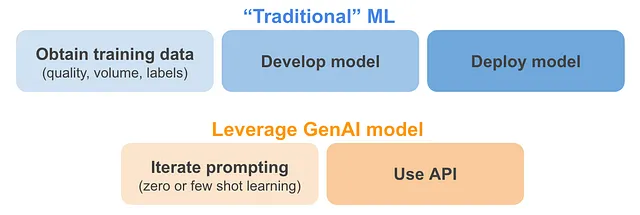
无论是否利用GenAI,其他限制或考虑因素都不会改变:
- 高风险:这仍然是一个问题,因为GenAI模型在其预测中也存在一定的误差。谁没有见过GhatGPT产生幻觉或提供毫无意义的答案?更糟糕的是,评估这些模型更加困难,因为无论准确度如何,回答总是听起来自信,并且评估变得主观化(例如“这个回答对我来说有意义吗?”)。
- 伦理:仍然和以前一样重要。有证据表明,由于输入数据的原因,GenAI模型可能存在偏见(链接)。随着越来越多的公司和功能开始使用这些类型的模型,明确这可能带来的风险非常重要。
- 可解释性:由于GenAI模型比“传统”机器学习模型更大且更复杂,对其预测的可解释性变得更加困难。目前正在进行研究,以了解如何实现这种可解释性,但目前仍处于非常初级的阶段(链接)。
总结
在本博客文章中,我们看到了在决定是否使用机器学习以及随着生成式AI模型的进展而发生的变化时需要考虑的主要因素。讨论的主要话题包括数据的质量和数量、标签获取、部署、风险、伦理和可解释性。希望这个总结在考虑下一个机器学习(或非机器学习)的计划时对您有所帮助!
参考资料
[1] 机器学习偏见:介绍、风险和解决有歧视性的预测模型,作者自己的文章
[2] 超越测试集:提示如何改变机器学习开发,deeplearning.ai
[3] 大型语言模型存在偏见,逻辑能帮助拯救它们吗?MIT新闻
[4] OpenAI试图解释语言模型的行为,TechCrunch




