如何使用大型语言模型与任何PDF和图像文件进行聊天 — 附带代码
使用大型语言模型与PDF和图像文件进行聊天的方法 — 附代码
构建能回答关于任何文件问题的AI助手的完整指南
介绍
很多有价值的信息都被困在PDF和图像文件中。幸运的是,我们拥有这些能够处理这些文件以查找特定信息的强大大脑,这实际上是很棒的。
但是,我们内心有多少人不希望拥有一个可以回答任何给定文档问题的工具呢?
这就是本文的整个目的。我将逐步解释如何构建一个可以与PDF和图像文件进行交互的系统。
如果您更喜欢观看视频,请查看下面的链接:
项目的总体工作流程
了解正在构建的系统的主要组件是很好的。让我们开始吧。
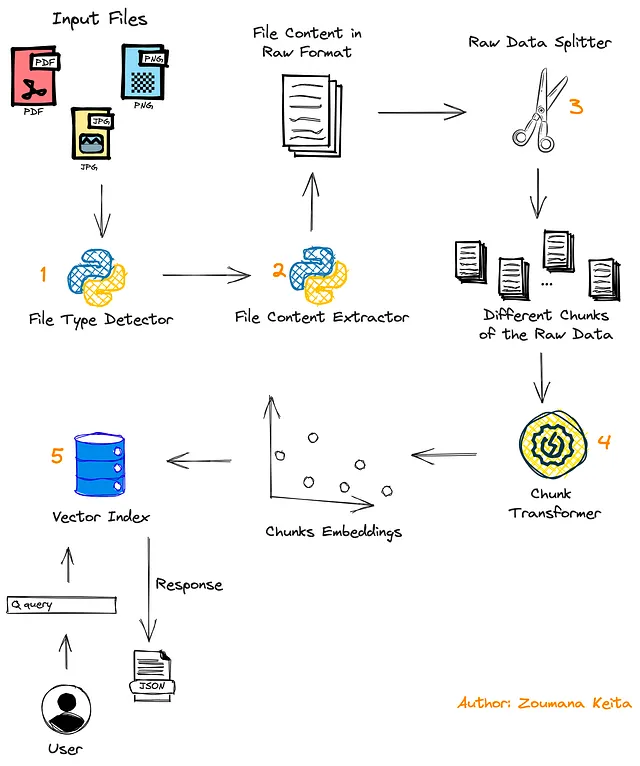
- 首先,用户提交要处理的文档,可以是PDF或图像格式。
- 然后使用第二个模块检测文件的格式,以应用相关的内容提取功能。
- 然后使用
数据拆分器模块将文档的内容拆分成多个块。 - 最后,将这些块转换为嵌入向量,并存储在向量存储中之前。
- 在流程的最后,用户的查询用于查找包含该查询答案的相关块,并将结果作为JSON返回给用户。
1. 检测文档类型
对于每个输入文档,根据其类型应用特定的处理,无论是PDF还是图像。