为什么你需要一个知识图谱,以及如何构建它
为什么需要知识图谱及如何构建
从关系数据库迁移到图数据库的指南
简而言之:知识图谱将事件、人物、资源和文档组织在图数据库中进行高级分析。本文将解释知识图谱的目的,并向您展示如何将关系数据模型转换为图模型,将数据加载到图数据库中,并编写一些示例图查询。
为什么需要知识图谱?
关系数据库非常适合创建列表,但在管理多样性实体网络方面效果不佳。您是否曾尝试使用关系数据库完成以下任务之一?
- 分析一个患者与数十个人员、地点和程序进行交互的医疗照护阶段
- 在与供应商、客户和交易类型相关的网络中找到金融欺诈的模式
- 优化供应链的依赖关系和相互连接的要素
这些都是事件、人员和资源的网络示例,会给使用关系数据库的SQL分析师带来巨大的麻烦。随着网络规模的增加,关系数据库的速度呈指数级下降,而图数据库具有相对线性的关系。如果您正在管理一组活动和事物的网络或网络,那么图数据库是正确的选择。未来,我们应该预计企业数据组将采用一种组合,即在一个业务功能上使用关系数据库进行孤立分析,并使用知识图谱处理跨功能的复杂网络流程。
基于图数据库技术的知识图谱是用于处理多样性过程和实体网络的。在知识图谱中,您有表示人员、事件、地点、资源、文档等的节点。您还有表示节点之间关系的边。这些关系以名称和方向的形式在数据库中物理存储。并非每个图数据库都是知识图谱。要被认为是知识图谱,设计必须在跨多个业务功能的各种节点中嵌入业务语义模型,节点和关系的业务名称清晰可见。您实际上正在创建一个由所有相互作用的业务部分组成的无缝网络,并使用业务语义将数据紧密与所代表的过程联系起来。这可以作为未来生成式LLM模型使用的基础。
为了在知识图谱中展示多样的数据集,让我们以供应链物流的简单示例为例。业务流程可能如下所示:
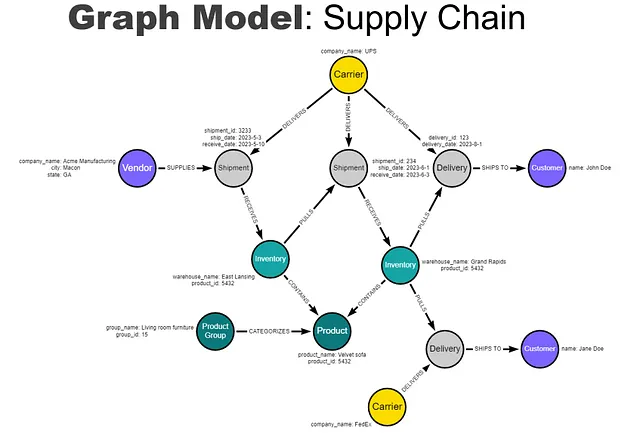
该模型可以扩展以包括业务流程的任何相关部分:客户退货、发票、原材料、制造过程、员工,甚至客户评价。没有预定义的模式,因此模型可以在任何方向或深度上扩展。
从关系模型到维度模型到图模型
现在让我们通过使用电子商务供应商的场景将典型的关系数据库模型转换为图模型的过程来进行说明。假设该供应商在其网站上运行一系列数字营销活动,接收订单并向客户发货。关系模型可能如下所示:
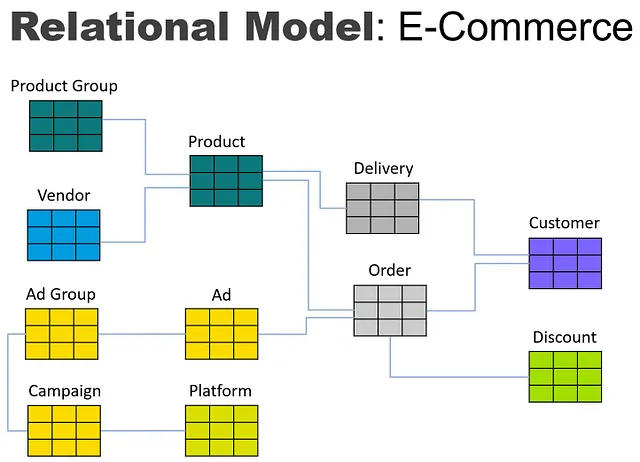
如果我们将其转换为用于数据仓库的维度模型,模型可能如下所示:
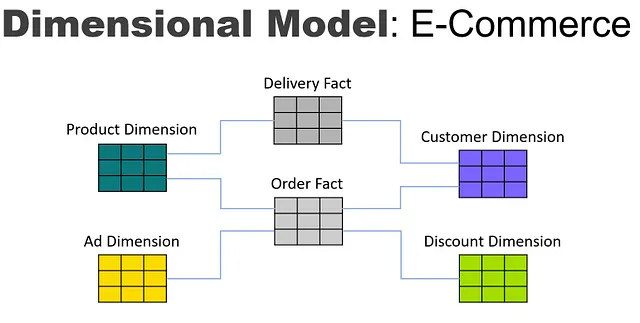
请注意,事实表专注于事件,而维度表则将业务实体的所有属性合并到一张表中。这种以事件为中心的设计可以提供更快的查询时间,但也会带来其他问题。每个事件都是一个独立的事实表,很难看出一个事件与相关事件之间的连接。当这些关系分布在多个事实表之间时,很难理解维度实体(如产品)与在另一个维度(如承运人)中与其共享的所有事件之间的关系。维度模型一次只关注一个事件,但会隐藏不同事件之间的连接。
图模型通过以这种方式建模来解决显示实体之间关联性的问题:

乍一看,这个图模型与关系模型更相似,而不是维度模型,但它可以用于与数据仓库相同的分析目的。请注意,每个关系都有名称和方向。可以在任何节点之间创建关系,例如事件与事件、人员与人员、文档与事件等。 图查询还允许您以SQL不可能的方式遍历图形。
例如,您可以收集与关键事件相关的任何节点,并研究其出现的模式。层次结构得以保留,每个级别都可以单独引用,不像非规范化的维度表。最重要的是,图形在不遵循严格的模式约束集的情况下,更灵活地建模任何业务中的事件或实体。该图形的设计与业务的语义模型相匹配。
提取、转换和加载(ETL)
现在让我们来看一个示例关系数据库表,并创建一些示例脚本将数据提取、转换和加载到图数据库中。对于本文,我将使用Cypher语言,该语言是最流行的商业图数据库Neo4j使用的语言。但这些概念也适用于其他变种的图查询语言(GQL)。我们将使用以下示例产品表:
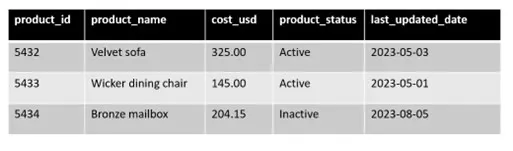
使用以下查询,我们可以提取过去24小时内更新的新产品:
SELECT product_id, product_name, cost_usd, product_statusFROM ProductWHERE last_updated_date > current_date -1;我们可以将这些结果提取到一个名为“df”的Python Pandas数据框中,打开一个图数据库连接,然后使用以下脚本将数据框合并到图中:
UNWIND $df as rowMERGE INTO (p:Product {product_id: row.product_id})SET p.product_name = row.product_name, p.cost_usd = row.cost_usd, p.product_status= row.product_status, p.last_updated_date = datetime();第一行引用了一个名为“df”的参数,该参数是来自Pandas的数据框。我们将合并到节点类型“Product”,它由别名“P”引用。然后,“product_id”部分用于绑定到节点中的唯一标识符。之后,Merge语句看起来类似于SQL中的合并。
在使用类似上述脚本的合并语句创建了每个节点之后,我们可以创建关系。关系可以在同一个脚本中创建,也可以在后处理脚本中使用如下的合并命令创建:
MATCH (p:Product), (o:Order)WHERE p.product_id = o.order_idMERGE (o)-[:CONTAINS]->(p);Match语句类似于Oracle中的旧联接用法,Match之后声明了两个节点类型,然后在Where子句中进行联接。
图模型上的查询
假设我们已经构建了图形,并且现在想要查询它。我们可以使用以下查询来查看来自亚利桑那州的广告组驱动的订单:
MATCH (ag:AdGroup)<-[:BELONGS_TO]-(a:Ad)-[:DRIVES]->(o:Order)<-[:PLACES]-(c:Customer)WHERE c.state = 'AZ'RETURN ag.group_name, COUNT(o) as order_count此查询将返回广告组名称和订单数量,过滤条件为亚利桑那州的状态。请注意,Cypher语言中不需要使用Group By子句,与SQL不同。从该查询中,我们将得到以下示例输出:

这个例子可能看起来很简单,因为你可以很容易地在关系型数据库或数据仓库中使用订单事实表创建类似的查询。但是让我们考虑一个更复杂的查询。假设您想要查看从广告活动启动到可归因交付完全接收所需的时间。在数据仓库中,这个查询将涉及到事实表的交叉(不是一个简单的任务),并且需要相当多的资源。在关系型数据库中,这个查询将涉及到一系列的连接操作。在图数据库中,该查询将如下所示:
MATCH (cp:Campaign) )<-[:BELONGS_TO]-(ag:AdGroup)<-[:BELONGS_TO]-(a:Ad)MATCH (a)-[:DRIVES]->(o:Order)<-[:FULFILLS]-(d:Delivery)RETURN cp.campaign_name, cp.start_date as campaign_launch_date, MAX(d.receive_date) as last_delivery_date我使用了一个样本查询路径,但用户可以采用各种路径来回答不同的业务问题。在这个查询中,请注意从广告活动到交付的路径是通过订单和交付之间的关系进行连接的。另外,请注意为了可读性,我将路径分为了两部分,从第二行开始使用了Ad的别名。该查询的输出结果如下:

结论
我们已经介绍了将电子商务业务流程从关系型模型转换为图模型的一些示例步骤,但在这篇文章中无法涵盖所有设计原则。希望您已经意识到图数据库与关系型数据库需要大致相同的技术技能,并且迁移并不是一个巨大的障碍。
最大的挑战是将大脑从传统的关系建模技术转变为语义建模或业务建模。如果您看到了图技术的潜在应用,请尝试进行一个概念验证项目。知识图谱在分析方面的可能性远远超出了二维表的能力!
所有图片由作者提供





