“雨能预测雨吗?美国天气数据与今明两天的降雨相关性”
Can rain predict rain? Correlation between US weather data and rainfall in the next two days.
介绍有用的气候数据集并验证全球变暖预测

摘要
在波士顿漫长的六月和七月期间,每当我家人计划做一些有趣的事情时,似乎总是下雨。我们开始怀疑是否被困在一个多雨的模式中,并问:“连续三天下了很多雨,明天下雨的可能性大吗?”我意识到,使用现有的天气数据可以很容易回答这个问题。
本文介绍了我使用的美国天气数据集、我编写的用于分析数据的Python/pandas程序以及结果。简而言之,是的,连续多天的雨天强烈预示着更多的雨水。而且令人惊讶的是,雨水连续的时间越长,第二天下雨的可能性就越大。结果还证明了全球变暖模型的预测——现在比以前下雨的次数更多。
数据
关于美国海洋和大气管理局(NOAA)的降雨有两个关键数据集。我使用了小时降水数据(HPD)。描述页面一般是有帮助的,但是数据集的链接是错误的,并指向了一个旧版本。新的数据集在这里,涵盖了1940年到2022年的时期。(将添加2023年的数据。)HPD具有很好的细粒度,包括来自美国2000多个采集站的每小时降水量。数据文件包含每个CSV文件中一个站点的所有年份。我只使用了每日总量,但将来的分析可能会用到每小时的信息。
那么下雪时怎么办?雪的累积量会融化以找出相等的雨量。因此,HPD中的所有数据都包括液态雨水、融化的雪以及介于两者之间的所有内容,如雪泥和冰雹。
还有另一个有价值的数据集,名为本地气候数据(LCD),可以用于类似的分析。LCD不仅包含降水等更多信息,还包括温度、日出/日落时间、气压、能见度、风速、雾、烟雾、月度摘要等。LCD每天更新,所以包含昨天的数据。要使用它,您需要解码集成表面数据集(ISD)的站点编号。
分析程序
雨水分析程序是用Python/pandas编写的。我编写的代码易读性很好,但值得探索一些特定功能。
程序可以读取完整的HPD站点列表或从文本文件中读取特定的站点列表。这个功能用于使用不同的参数重新运行程序,同时确保使用与之前运行的相同站点。
from rain_helpers import ALL_STATION_FILESSTATION_LIST_INPUT = "/Users/chuck/Desktop/Articles/hpd_stations_used_list_1940-1950.txt"ALL_STATIONS = True # 使用所有站点还是特定的站点列表?# 选择我们所知道的所有站点或特定的站点列表(通常来自此程序的先前运行)if (ALL_STATIONS): station_files = ALL_STATION_FILESelse: with open(STATION_LIST_INPUT, 'r') as fp: data = fp.read() station_files = data.split("\n") fp.close()另一个方便的功能是能够选择站点文件的子集。您可以使用1/100的站点快速运行代码进行调试,或者使用1/3进行准确的结果近似。根据大数定律,我对1/3(约600个站点)的测试产生的结果与完整数据集几乎相同。
SKIP_COUNT = 3 # 1 = 不跳过任何站点.for i in range (0, len(station_files), SKIP_COUNT): station_url = HPD_LOCAL_DIR + station_files[i] stationDF = pd.read_csv(station_url, sep=',', header='infer', dtype=str)另一个加快速度的方法是将所有站点文件下载到本地计算机上,这样您就不必每次都从NOAA获取它们。完整集合约为20GB。如果您没有这个额外的空间,代码在从云中读取时仍然可以正常运行。
HPD_CLOUD_DIR = "https://www.ncei.noaa.gov/data/coop-hourly-precipitation/v2/access/" # 小时降水数据(HPD)HPD_LOCAL_DIR = "/Users/chuck/Desktop/Articles/NOAA/HPD/"station_url = HPD_LOCAL_DIR + station_files[i] # 在本地和云端之间切换代码中最棘手的部分是对每个日期进行回溯,看看是否连续几天都有雨。问题在于要查找的数据在同一个DataFrame中,需要进行自连接。使用循环遍历DataFrame,并在每一行中查找前几天的日期是很诱人的。但是在任何编程语言中,特别是在pandas中,循环遍历大型数据结构都是不推荐的。我的代码通过对DataFrame进行快照,为每一行创建包含九个前一日期(和一个明天)的字段,然后使用这些字段与快照进行连接来解决了这个问题。
# 获取快照以备稍后进行自连接。调整字段名称以避免连接后混淆。
stationCopyDF = stationDF
stationCopyDF = stationCopyDF[["STATION","DATE","DlySumToday"]] # 保留我们需要的内容
stationCopyDF = stationCopyDF.rename({"DlySumToday":"DlySumOther", "DATE":"DATEother"}, axis='columns') # 添加其他日期,我们将从中获取降雨量。
stationDF["DATE_minus9"] = stationDF["DATE"] - pd.offsets.Day(9)
stationDF["DATE_minus8"] = stationDF["DATE"] - pd.offsets.Day(8)
...
stationDF["DATE_minus1"] = stationDF["DATE"] - pd.offsets.Day(1)
stationDF["DATE_plus1"] = stationDF["DATE"] + pd.offsets.Day(1)
# 将其他降雨量合并到基本记录中。调整列名以清楚我们所做的操作。
stationDF = stationDF.merge(stationCopyDF, how='inner', left_on=["STATION","DATE_minus9"], right_on = ["STATION","DATEother"])
stationDF = stationDF.rename({"DlySumOther":"DlySum9DaysAgo"}, axis='columns')
stationDF = stationDF.drop(columns=["DATEother"])
stationDF = stationDF.merge(stationCopyDF, how='inner', left_on=["STATION","DATE_minus8"], right_on = ["STATION","DATEother"])
stationDF = stationDF.rename({"DlySumOther":"DlySum8DaysAgo"}, axis='columns')
stationDF = stationDF.drop(columns=["DATEother"])
....
stationDF = stationDF.merge(stationCopyDF, how='inner', left_on=["STATION","DATE_minus1"], right_on = ["STATION","DATEother"])
stationDF = stationDF.rename({"DlySumOther":"DlySum1DayAgo"}, axis='columns')
stationDF = stationDF.drop(columns=["DATEother"])
stationDF = stationDF.merge(stationCopyDF, how='inner', left_on=["STATION","DATE_plus1"], right_on = ["STATION","DATEother"])
stationDF = stationDF.rename({"DlySumOther":"DlySumTomorrow"}, axis='columns')
stationDF = stationDF.drop(columns=["DATEother"])在每行获取前几天的降雨量后,代码很容易找到每个连续降雨期的长度。请注意,在计算下雨天数时,今天也算作一天。
stationDF["DaysOfRain"] = 0
stationDF.loc[(stationDF["DlySumToday"] >= RAINY), "DaysOfRain"] = 1
stationDF.loc[(stationDF['DlySumToday'] >= RAINY) & (stationDF['DlySum1DayAgo'] >= RAINY), 'DaysOfRain'] = 2
stationDF.loc[(stationDF['DlySumToday'] >= RAINY) & (stationDF['DlySum1DayAgo'] >= RAINY) & (stationDF['DlySum2DaysAgo'] >= RAINY), 'DaysOfRain'] = 3
... 等等结果
使用2000年至2021年的数据,共有1808个拥有有效数据的测站,共有8967394个数据点(日期、位置和降雨量)。
- 所有数据点的平均降雨量为0.0983英寸,约为1/10英寸。
- 下雨天数(降雨量≥0.5英寸)的比例为6.2%。
- 干燥天数(降雨量≤0.05英寸)的比例为78.0%。
回答这个项目的最初问题是:
是的,下雨的天数可以预测明天是否会下雨。下雨的时间越长(最长持续8天),明天下雨的可能性就越大。
与此相关的结果是:
下雨的天数可以预测明天的降雨量。下雨的时间越长(最长持续7天),明天的降雨量越大。
两个图表展示了这个结果。
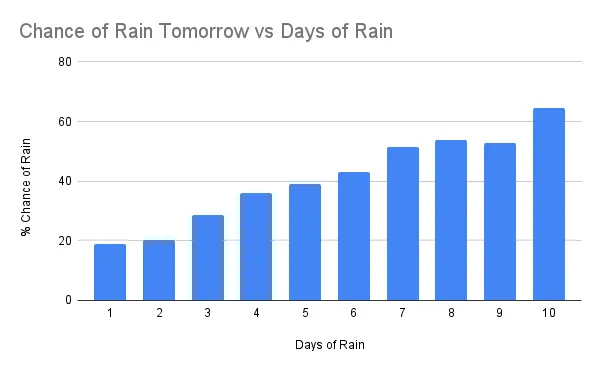

我尝试了不同的“下雨天”的设定,将其从0.5英寸改为0.75英寸和1.0英寸。这些变化显示了相同的一般现象,即下雨天数预测更多的降雨,但在连续八天内没有完美的相关性。将“下雨天”定义为0.5英寸似乎是预测明天降雨的最佳选择。
你可能想知道在哪里会连续下雨10天。在整个美国的22年时间里,几乎有900万个数据点,只有118次出现这样的天气情况。其中一些地方是:佛罗里达州博卡拉顿;波多黎各圣胡安;夏威夷卡胡纳瀑布;夏威夷卡马纳;夏威夷基哈拉尼;夏威夷帕阿克亚;密西西比州帕斯卡古拉;华盛顿州奎纳尔特;和华盛顿州奎尔森。
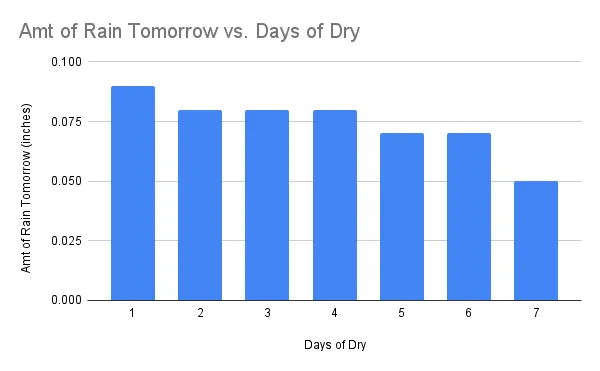
连续干燥的天数(降雨量<0.05英寸)也与次日的干燥情况有很好的相关性,但预测不太强烈,因为明天的干燥天气的机会非常接近。明天的干燥天气的机会总是接近于78%的整体平均水平。

连续干燥天数在预测明天的降雨量方面稍微好一些。
气候变化
一个明显相关的问题是,随着地球气温的上升,这里描述的结果是否发生了变化。我对1940年至1960年、1960年至1980年和1980年至2000年的美国数据进行了相同的分析。
核心结果是相同的——下雨的天数预测更多的降雨。每个时间段的确切数字略有不同,但它们并没有改变强烈的相关性。例如,从1960年到1980年,有1388个具有有效数据的站点和6807917个数据点,结果如下:
下1天下雨后还下雨的比例=17.3%下2天下雨后还下雨的比例=19.6%下3天下雨后还下雨的比例=27.4%下4天下雨后还下雨的比例=37.1%下5天下雨后还下雨的比例=43.8%下6天下雨后还下雨的比例=51.5%下7天下雨后还下雨的比例=52.4%
一个更重要的推论,由气候变化模型预测,是随着地球变暖,降雨量会增加。至少过去80年来,HPD数据集可以验证这一点。
简单的方法是获取所有当前的气候站点(约2000个),并查看每个十年的降雨数据。但这样做存在潜在的偏差。现在的气象站比1940年多,因为在过去80年里逐渐增加了站点。有可能新的站点建在多雨的地方。如果是这样的话,新的数据会显示更多的降雨,但只是因为总体站点集比1940年的集合更湿润。
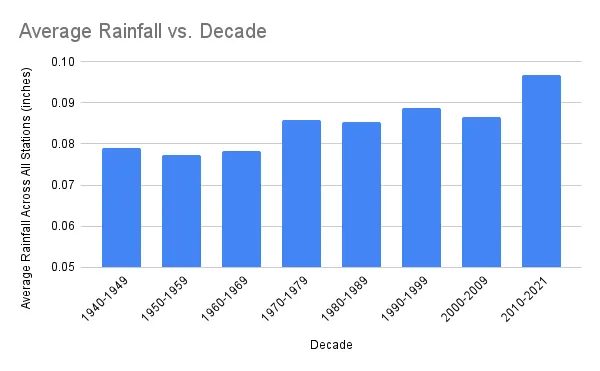
更准确的方法是找到在1940年代有降雨数据的站点集,并在每个十年内使用相同的站点。我的程序可以实现这一点,因为它在每次运行时发布所使用的站点列表。所以首先我找到了1940年到1950年的数据,然后再次使用发出的站点列表来获取1950年到1960年的数据,然后是1960年到1970年,依此类推。这些十年内大约有840个站点,其中各个十年的数据点在40万到250万之间。
每个十年的平均降雨量应该非常接近 — 再次根据大数定律。但下面的图表显示了相同站点集的明显增加的降雨量。这是一个显著的结果,支持全球变暖模型的一个关键预测。
更多信息
https://www.weather.gov/rah/virtualtourlist — 美国国家气象局的天气预报。
https://www.ncdc.noaa.gov/cdo-web/datasets — 美国海洋和大气管理局数据集的概述。
https://www.epa.gov/climate-indicators/climate-change-indicators-us-and-global-precipitation — 美国环境保护局关于气候变化引起的降水增加的报告。





