深度学习用于深度对象:ZoeDepth是一个用于多领域深度估计的AI模型
ZoeDepth is an AI model for deep object depth estimation in multiple domains using deep learning.


你是否曾经遇到过一种错觉,其中图像中的孩子看起来比成年人更高更大?Ames房间错觉就是其中的一种,它涉及到一个形状像梯形的房间,其中一个房间的角比观察者更靠近,而另一个角则更远。当你从某个角度观察时,房间中的物体看起来正常,但当你移动到不同的位置时,一切都会变化大小和形状,这可能会让人难以理解什么离你近,什么离你远。
然而,这对我们人类来说是一个问题。通常,当我们观察一个场景时,如果没有错觉的干扰,我们可以相当准确地估计物体的深度。然而,计算机在深度估计方面并不那么成功,因为它仍然是计算机视觉中的一个基本问题。
深度估计是确定相机与场景中物体之间距离的过程。深度估计算法将图像或图像序列作为输入,并输出相应的深度图或场景的3D表示。这是一个重要的任务,因为在诸如机器人技术、自动驾驶车辆、虚拟现实、增强现实等众多应用中,我们需要了解场景的深度。例如,如果你想要一辆安全的自动驾驶汽车,了解前方车辆的距离对调整驾驶速度至关重要。
深度估计算法有两个分支,度量深度估计(MDE)和相对深度估计(RDE)。度量深度估计的目标是估计绝对距离,而相对深度估计的目标是估计场景中物体之间的相对距离。

MDE模型对于制图、规划、导航、物体识别、3D重建和图像编辑等方面非常有用。然而,当在多个数据集上训练单个模型时,MDE模型的性能可能会下降,特别是如果图像的深度尺度存在较大差异(例如室内和室外图像)。因此,现有的MDE模型通常会过拟合特定的数据集,并且在其他数据集上的泛化能力较差。
相反,RDE模型使用视差作为监督手段。RDE中的深度预测仅在图像帧之间相对一致,且缺乏尺度因子。这使得RDE方法能够在各种场景和数据集上进行训练,甚至包括3D电影,这有助于提高模型在不同领域的泛化能力。然而,牺牲的是RDE中的深度预测没有度量意义,这限制了其应用。
如果将这两种方法结合起来会怎样呢?我们可以得到一个深度估计模型,它可以在不同领域中具有良好的泛化能力,同时仍然保持准确的度量尺度。这正是ZoeDepth所实现的。
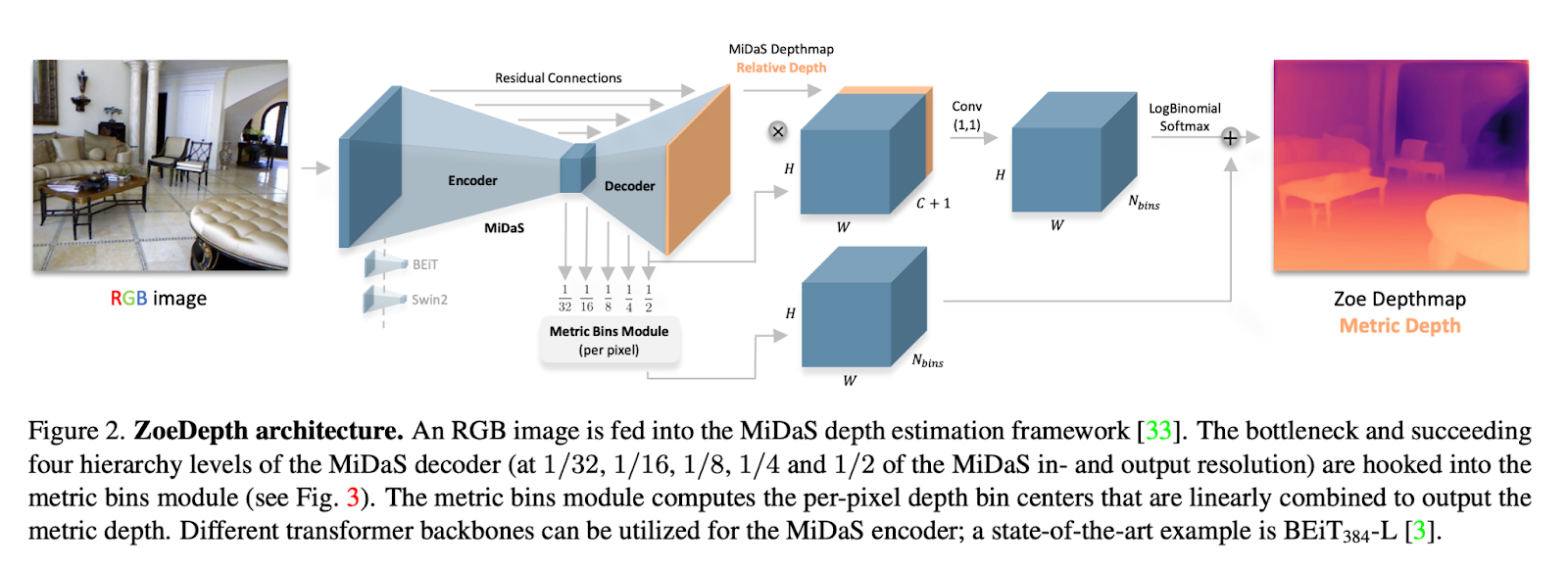
ZoeDepth是一个将MDE和RDE方法结合的两阶段框架。第一阶段包括一个编码器-解码器结构,用于训练估计相对深度。该模型在各种数据集上进行训练,以提高泛化能力。第二阶段添加了负责估计度量深度的组件。
这种方法中使用的度量头设计基于一种称为度量分组模块的方法,它为每个像素估计一组深度值,而不是单个深度值。这使得模型能够捕捉每个像素可能的深度范围,从而提高其准确性和稳健性。这使得模型能够准确地测量场景中物体之间的物理距离。这些头部组件是在度量深度数据集上进行训练的,并且与第一阶段相比较轻量级。
在推理方面,分类器模型使用编码器特征为每个图像选择合适的头部组件。这使得模型可以专门用于估计特定领域或场景类型的深度,同时仍然受益于相对深度的预训练。最终,我们得到了一个灵活的模型,可以在多种配置中使用。






