狂野的野生布料…(第一部分)
Wild fabric in the wild... (Part 1)
让我们从了解什么是RAG应用程序开始,这个术语在最近几个月引起了相当大的关注。
RAG(Retrieval-Augmented Generation)是一种人工智能框架,通过整合外部知识源来提高语言模型生成的响应质量。它弥合了语言模型和现实世界信息之间的差距,从而产生更具上下文信息和可靠性的文本生成。为了说明这一点,让我们看一下下面的图像,它提供了一个引人注目的示例。
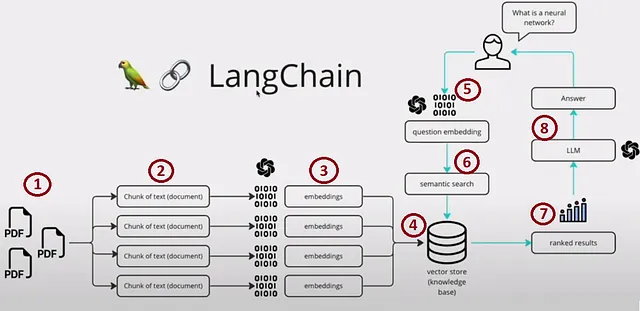
我们可以将这个过程分为四个主要部分:
- 第1、2、3和4步 – 索引
- 第5步 – 提示
- 第6和7步 – 搜索和检索
- 第8步 – 生成
嗯,为RAG应用程序创建一个原型是很简单的,但是在处理庞大的知识数据库时,要将其优化为高性能、耐久性和可扩展性,这是一个重大的挑战。
本博客将深入探讨将RAG应用程序与基本的语言模型(LLM)应用程序区分开的独特特点,重点关注这种情况下嵌入和向量存储选择的重要性。基本上,就是索引和搜索和检索部分。
- 这项AI研究揭示了ComCLIP:一种无需训练的图像和文本组合对齐方法
- 这篇人工智能论文提出了一种递归记忆生成方法,以增强大型语言模型中的长期对话一致性
- 自动零售结账台如何识别未标记的农产品?了解伪增强计算机视觉方法
让我们开始吧。

为了构建与您的提示和查询相关的“上下文”,我们必须首先从分段的数据块生成嵌入。这些嵌入被存储为向量索引,为基于用户查询的近似最近邻(ANN)搜索奠定了基础。虽然这个概念似乎很简单,但是深入研究将这个过程转化为生产环境中的细节揭示了一系列值得探索的挑战。
向量索引、搜索和检索的成本
现在,让我们深入探讨一个核心考虑因素之一 – 索引的成本。重要的是要了解,当构建一个可投入生产的应用程序时,仅依靠免费的内存选项是不可取的。
让我们来进行一个保守估计,从一个包含350万页或100万个PDF的内部知识库中构建嵌入,每个PDF平均有3.5页。为了简单起见,让我们假设每页只包含文本内容,没有图像。因此,每页大致相当于1000个标记。如果我们将其分解为每个1000个标记的块,我们将得到350万个块,随后转换为350万个嵌入。
对于成本计算,让我们考虑这个领域中的两个主要选择 – Weaviate和Pinecone。我们将简单地评估这三个关键部分的每月费用:
- 一次性嵌入转换成本:处理350万个嵌入的近似成本为350美元,转换率为每次转换0.0001美元。
- Pinecone性能优化的向量数据库(标准版):对于单个副本,这个选项的成本大约为650美元。这包括索引和检索成本。重要的是要注意,随着需求的增长,成本是线性增长的。另一个可行的选择Weaviate可能具有类似的定价结构。
- 查询嵌入转换的费用:假设有1000个用户每天平均进行25个查询,每个查询和提示总计100个标记,这一部分的成本约为10美元。
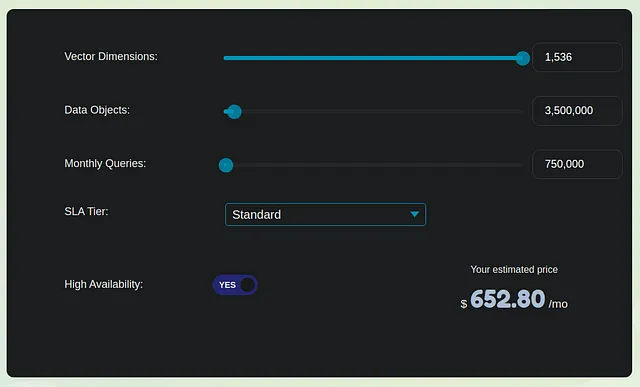
中等程度的索引每月总费用约为1,000美元。请注意,此费用不包括与OpenAI LLM响应生成和应用托管相关的费用,后者可能大约是前述费用的5到7倍甚至更多。因此,向量存储成本占据了整体支出的大部分,约占总支出的15到20%。
为了降低成本,您可以考虑托管顶级嵌入模型,通过选择小于1536的嵌入大小来减少向量存储费用。
但您仍然需要支付向量存储费用。

在选择100多个选项中的向量存储时,在功能(如相似性搜索度量和索引)保持一致的情况下,还应考虑哪些因素?
平衡延迟、规模和召回率
从规模和成本的角度来看,让我们考虑客户端-服务器架构作为我们的向量存储。您可以根据数据量、隐私和资金等因素选择将其托管在云端还是本地。
在考虑向量存储时,有两种重要的延迟需要考虑:索引延迟和检索延迟。在许多用例中,检索延迟优先于索引延迟。这种偏好源于索引操作通常是零散或一次性任务,而与用户查询相似的块的检索更频繁,通常以实时和大规模的方式通过用户界面进行。另一方面,召回率是衡量找到的真实最近邻居的比例,以所有查询的平均值计算。该领域的大多数供应商采用混合向量搜索方法,以各种方式结合了关键字和向量搜索技术。值得注意的是,不同的数据库供应商在优化召回率或延迟方面做出不同的选择和妥协。
让我们在余弦度量的标准数据集上查看召回率与查询/秒ANN基准:
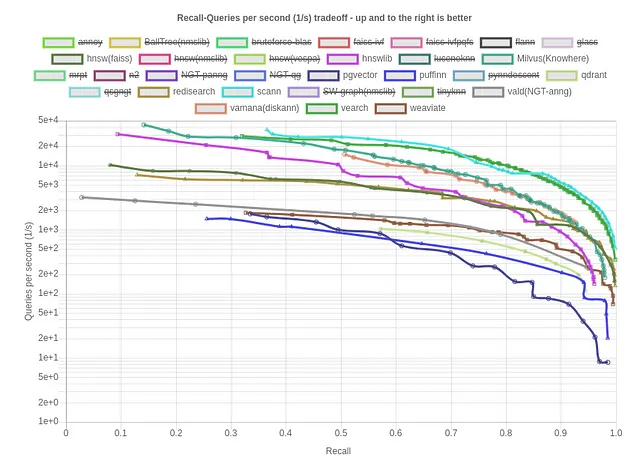
Scann、Vamana(DiskANN)和HNSW成为一些最佳的索引选项。现在让我们查看相同指标下的召回率与索引大小(kB)/每秒查询次数,这是评估向量数据库的效率和资源消耗的有价值的度量。较低的值表示更高的内存效率,优化向量数据库的性能和可扩展性。

在这个背景下,Qdrant、Weviate和Redisearch成为一些最佳的内存效率选项。
然而,您可以参考下面的图像,了解每个数据库使用的基础向量索引。

显然,许多数据库供应商选择开发自己的基于图的HNSW专有实现。这些定制实现通常包含旨在减少内存消耗的优化,例如将Product Quantization(PQ)与HNSW结合。然而,值得注意的是,只有少数几个数据库供应商采用了DiskANN,它似乎提供了与HNSW相当的性能,同时具有纯粹存储在磁盘上的大于内存的索引的可扩展性的独特优势。
在我们的评估中,我们不依赖供应商提供的基准测试,因为它们可能会对评估过程引入偏见。
刚性和无持续学习
在一个未来的情景中,您可能需要通过微调来更新您的大型语言模型(LLM)或嵌入模型,订阅升级模型,扩展嵌入维度或适应数据的变化,重新索引和相关的成本可能成为一场噩梦。这种刚性可能会严重阻碍系统演进的灵活性和成本效益。
除了这些挑战之外,让我们深入探讨一些矢量搜索和检索过程中固有的复杂性。
索引错误处理和维度诅咒
当遇到文本查询失败无法检索到相关上下文,而是提供无关或荒谬的信息时,此失败的根本原因通常可以归因于以下三个因素之一:
a) 缺乏相关文本:在某些情况下,数据库中根本不存在相关的文本块。这种结果是可以接受的,因为它表明查询可能与数据集的内容无关。
b) 嵌入质量差:另一个可能的原因是嵌入本身的质量不佳。在这种情况下,嵌入无法使用余弦相似度有效匹配两个相关文本。
c) 嵌入的分布:或者,嵌入本身可能具有良好的质量,但由于这些嵌入在索引中的分布,近似最近邻算法难以检索到正确的嵌入。
尽管通常可以将原因(a)视为查询与数据集不相关的原因,但区分原因(b)和(c)可能是一个复杂且耗时的调试过程。在处理大量高维向量的ANN算法的情况下,这种行为变得越来越明显,这种现象通常被称为“维度诅咒”。
重新评估矢量搜索和检索方法
如果矢量搜索生态系统的主要目标是根据查询获取“相关文本”,为什么要维护两个单独的过程呢?相反,为什么不建立一个统一的、学习的系统,当提供一个问题文本时,直接输出“最相关”的文本呢?
支撑整个生态系统的基本假设是依赖于向量嵌入之间的相似度度量来检索相关文本。然而,重要的是要认识到,可能存在比这种方法更优越的替代方案。大型语言模型(LLMs)本身并不是为相似性检索而进行微调的,完全有可能其他检索方法能够产生更有效的结果。
来源:Twitter
深度学习革命给我们带来了宝贵的教训:一个联合优化的检索系统往往比嵌入和近似最近邻(ANN)操作相互独立的断开过程表现更好。在优化的检索系统中,嵌入过程和ANN组件紧密相连,彼此了解对方的复杂性,从而实现更一致和高效的信息检索。 这凸显了在设计信息检索和上下文匹配系统时整体和综合方法的重要性。
结论
在生产就绪的检索增强生成(RAG)应用和矢量搜索领域,我们揭示了在将语言模型与现实世界知识相结合中的挑战和机遇。从索引的成本考虑到延迟、规模和召回率的微妙平衡,很明显,为了生产优化这些系统需要深思熟虑的规划。模型的僵化性强调了在面对变化时适应性的重要性。当我们重新评估用于生产环境的矢量搜索和检索时,我们发现一个统一的、联合优化的系统是有希望的。在这个不断演变的领域中,我们正处于创造更加上下文感知的AI系统的前沿,重新定义文本生成和信息检索的边界。
旅程还在继续…
感谢阅读。请在LinkedIn上与我联系。