可视化Sklearn交叉验证:K-Fold、洗牌和分割,以及时间序列分割
Visualizing Sklearn Cross-Validation K-Fold, Shuffle and Split, and Time Series Split.
绘制Sklearn K-Fold、Shuffle & Split和Time Series Split交叉验证过程,并使用Python显示验证结果
什么是交叉验证?
基本上,交叉验证是一种评估学习算法的统计方法。固定数量的折(数据组)被设置为运行分析。这些折将数据分为两组:训练集和测试(验证)集,在循环中交叉,以使每个数据点得到验证。
其主要目的是测试模型对于未在创建模型时使用的独立数据的预测能力。它也有助于应对过拟合或选择偏差等问题。
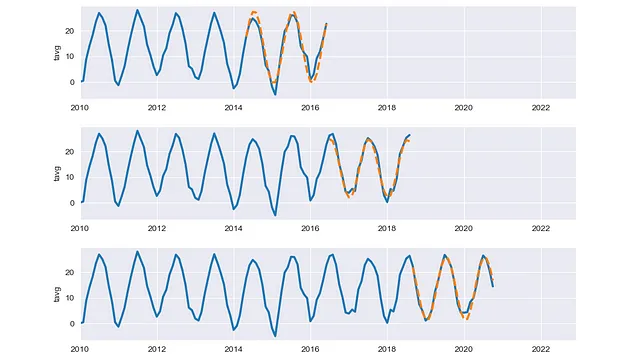
在本文中,我们将使用Python来可视化Scikit Learn库中的3种交叉验证类型的过程:
- K-Fold交叉验证
- Shuffle & Split交叉验证
- Time Series Split交叉验证
此外,还可以绘制验证结果以表示有见地的信息。
让我们开始吧
1. K-Fold交叉验证
K-Fold是一种常见的交叉验证方法。首先,所有数据被划分为折。然后,学习模型是从训练集(k-1折)创建的,测试集(剩下的一折)用于验证。
通常,从K-Fold交叉验证中获得的折会尽可能均匀地划分。接下来,我们将看到K-Fold交叉验证的过程。
导入库并加载数据
例如,本文将使用葡萄酒数据集进行工作,该数据集可以从Sklearn库下载。该数据集是根据CC BY 4.0许可下的UCI ML葡萄酒数据的副本。