堆叠我们的方式来实现更通用的机器人
Stacking our way to achieve more versatile robots.
引入RGB堆叠作为基于视觉的机器人操纵的新基准
对于一个人来说,捡起一根棍子并将其平衡地放在原木上或将小石头叠在石头上似乎是简单且相似的动作。然而,大多数机器人在处理超过一项此类任务时都很困难。操纵一根棍子需要一组不同的行为,而不是堆砌石头,更不用说将各种碟子叠在一起或组装家具了。在我们教导机器人执行这些任务之前,它们首先需要学会如何与更广泛范围的物体进行交互。作为DeepMind使命的一部分,也是使机器人更具一般化和实用性的一步,我们正在探索如何使机器人更好地理解与不同几何形状物体的相互作用。
在即将在CoRL 2021(机器人学习会议)上展示的一篇论文中,并且现在可以在OpenReview的预印版中获得,我们将RGB堆叠引入作为基于视觉的机器人操纵的新基准。在这个基准中,机器人必须学会如何抓取不同的物体并将它们平衡地叠放在一起。我们的研究与以往的工作的不同之处在于所使用的物体的多样性以及为验证我们的发现进行的大量经验评估。我们的结果表明,模拟和现实世界数据的组合可以用于学习复杂的多物体操纵,并为将问题推广到新物体的开放问题提供了一个强大的基线。为了支持其他研究人员,我们正在开源我们的模拟环境的一个版本,并发布用于构建我们的真实机器人RGB堆叠环境的设计,以及RGB物体模型的信息和用于3D打印它们的设计。我们还在更广泛的机器人学研究中开源了一系列库和工具。
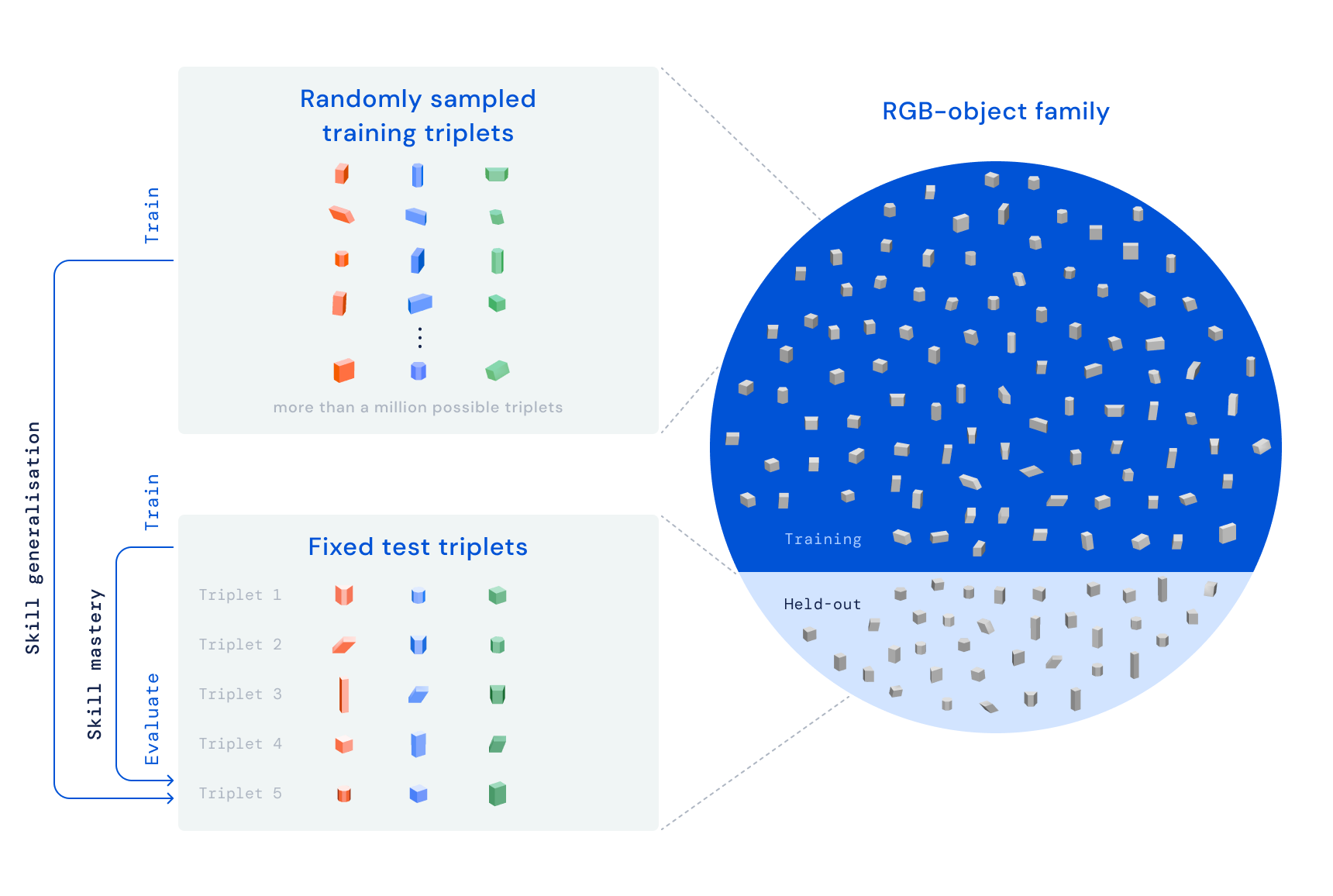
通过RGB堆叠,我们的目标是通过强化学习训练一个机械臂来叠放不同形状的物体。我们在篮子上方放置了一个连接到机械臂的并排夹具,并在篮子中放置了三个物体,一个红色、一个绿色和一个蓝色,因此命名为RGB。任务很简单:在20秒内将红色物体叠放在蓝色物体上方,而绿色物体则作为障碍和干扰。学习过程确保代理通过对多个物体集进行训练获取广义技能。我们有意地变化了抓取和叠放的能力,即定义代理如何抓取和叠放每个物体的特性。这种设计原则迫使代理展示超出简单拾取和放置策略的行为。

我们的RGB堆叠基准包括两个不同难度级别的任务版本。在“技能掌握”中,我们的目标是训练一个能够熟练叠放预定义的五个三元组的单个代理人。在“技能泛化”中,我们对相同的三元组进行评估,但是在训练时使用了大量的训练物体集,总计超过一百万个可能的三元组。为了测试泛化能力,这些训练物体不包括从中选择测试三元组的物体系列。在两个版本中,我们将学习流程分解为三个阶段:
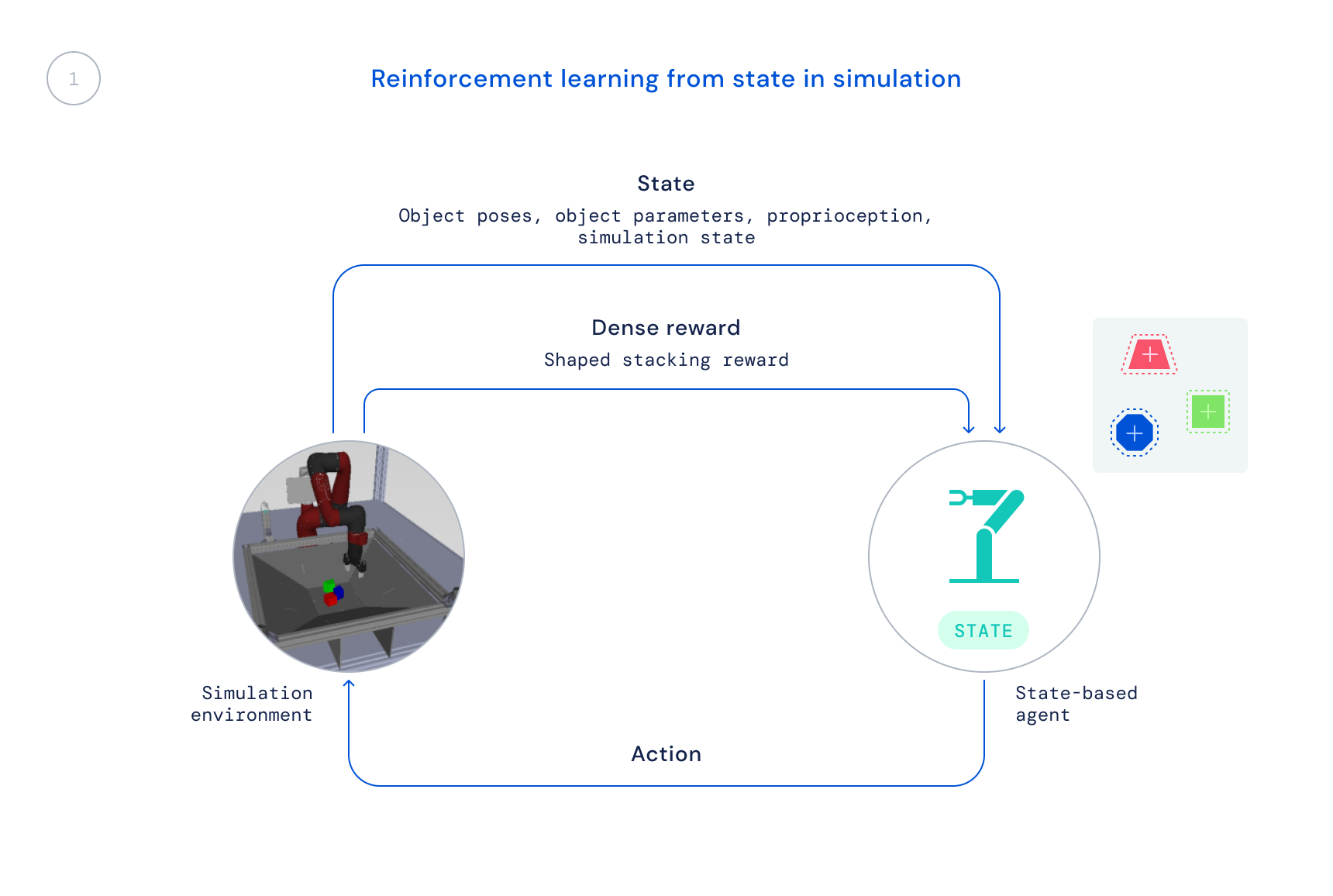
- 首先,我们使用现成的强化学习算法在仿真环境中进行训练:最大后验策略优化(MPO)。在这个阶段,我们使用模拟器的状态进行训练,因为物体的位置直接提供给智能体,而不需要智能体学习如何在图像中找到物体,从而实现快速训练。由于这些信息在真实世界中不可用,所以得到的策略不能直接应用于真实机器人。
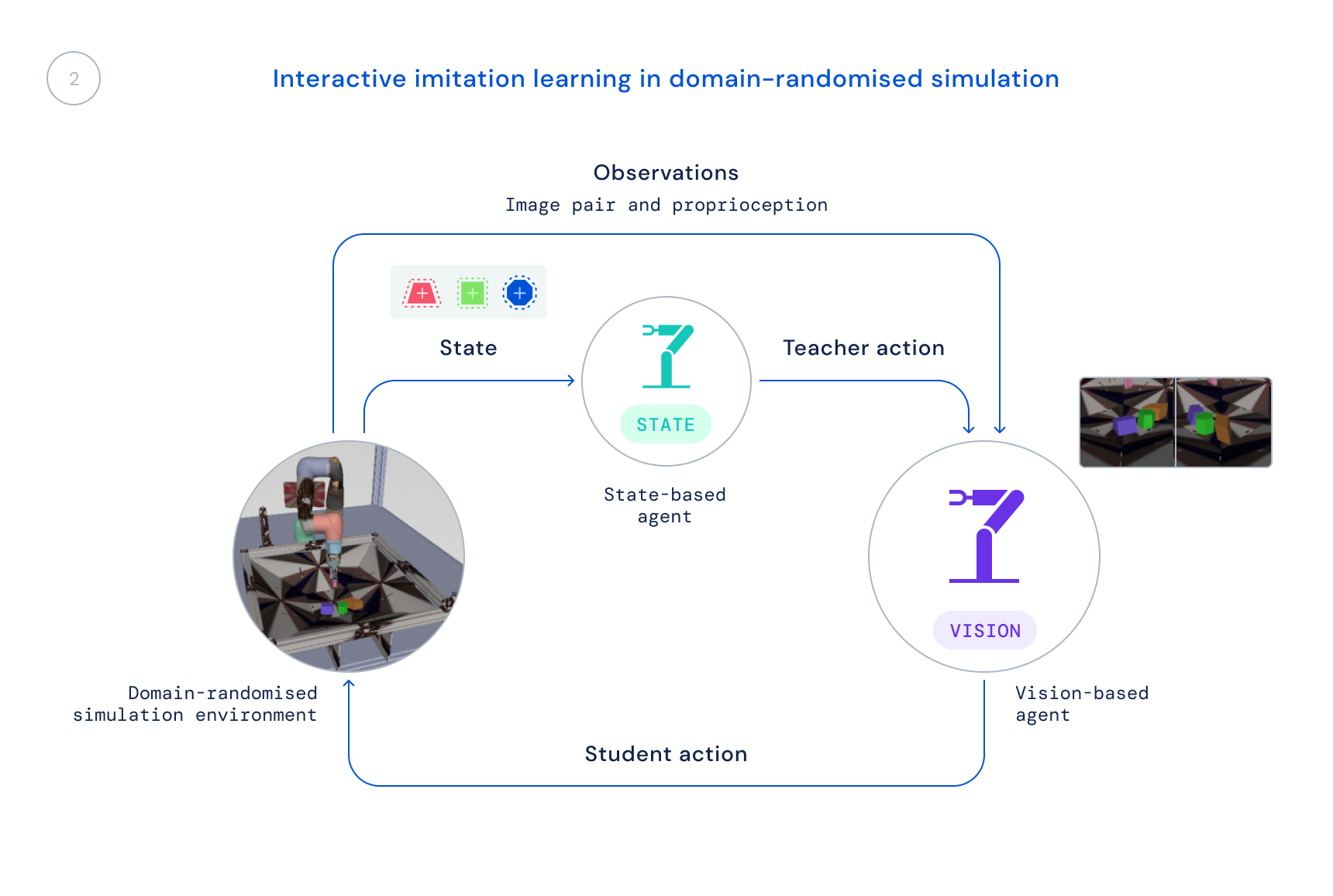
- 接下来,我们在仿真环境中训练一个新的策略,只使用真实观测数据:图像和机器人的本体感知状态。我们使用领域随机化的仿真来提高对真实世界图像和动力学的迁移能力。状态策略充当教师的角色,向学习智能体提供行为的修正,这些修正被融合到新的策略中。
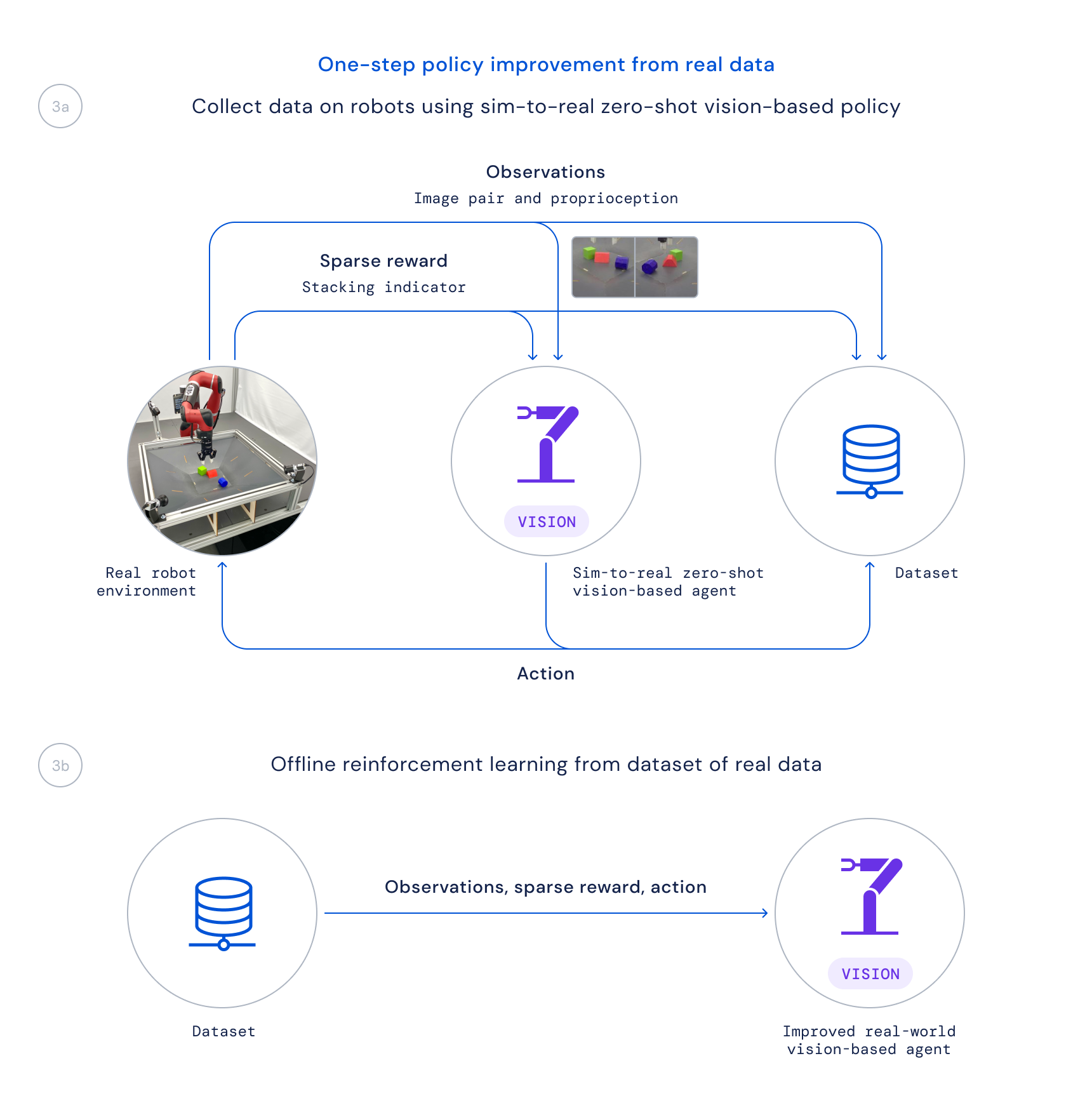
- 最后,我们使用这个策略在真实机器人上收集数据,并通过基于学习的Q函数对好的转换进行加权,以离线训练改进的策略,类似于批评者正则化回归(CRR)。这样我们可以利用在项目期间被动收集的数据,而不是在真实机器人上运行耗时的在线训练算法。
将我们的学习流程解耦成这样对于两个主要原因都至关重要。首先,它使我们能够解决这个问题,因为如果我们直接从零开始在机器人上进行训练,所需的时间将会非常长。其次,它提高了我们的研究速度,因为团队中的不同成员可以在流程的不同部分上进行工作,然后将这些更改结合起来以实现整体改进。

近年来,已经有很多关于将学习算法应用于解决大规模实际机器人操作问题的工作,但这些工作的重点主要是在抓取、推动或其他形式的操作单个物体等任务上。我们在论文中描述的RGB-堆叠方法,以及我们现在在GitHub上提供的机器人资源,能够产生令人惊讶的堆叠策略和对部分物体的掌握。然而,这只是探索可能性的初步阶段,泛化挑战仍未完全解决。随着研究人员不断努力解决机器人真正泛化的挑战,我们希望这个新的基准测试,以及我们发布的环境、设计和工具,能够为新的想法和方法做出贡献,使机器人的操作更加容易,能力更强大。






