使用Python进行数据探索性分析(EDA)的实用指南
Python数据探索性分析(EDA)指南
在本文中,我将逐步使用代码解释数据科学项目生命周期中最重要的部分之一,即探索性数据分析(EDA)的步骤。
我们将使用Kaggle Spaceship Titanic数据集来演示探索性数据分析(EDA)。
机器学习项目的第一步是探索数据。让我们开始吧。
导入一些基本库。
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsimport warningswarnings.filterwarnings('ignore')读取训练数据
要读取数据,我们将使用Pandas的read_csv函数。read_csv函数将CSV文件的路径作为第一个参数。
training_data = pd.read_csv('/kaggle/input/spaceship-titanic/train.csv')train = training_data.copy()train.head()
移除不必要的特征(PassengerId和Name)
根据我们的直觉,我们可以确定一个人的生存结果与他/她的姓名或乘客ID无关,因此我们将从数据中移除这两个特征。
## 删除不重要的特征(PassengerId和Name)train.drop(columns=['PassengerId','Name'], axis=1, inplace=True)查找关于数据的基本信息
train.info()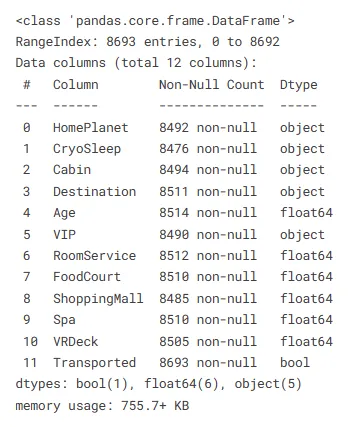
将数据分为两部分:一部分用于独立特征,另一部分用于依赖特征
## 将数据分为独立特征和依赖特征X = train.drop(['Transported'],axis=1)y = train['Transported']获取数据中数值和分类特征的名称
## 获取数据中数值和分类特征的名称num_feat = [feature for feature in X.columns if X[feature].dtypes != 'O' ]cat_feat = [feature for feature in X.columns if feature not in num_feat]print(f"数据中的数值特征为:{num_feat}。\n")print(f"数据中的分类特征为:{cat_feat}。")
将’Cabin’特征转换为三个不同的特征,然后移除原始的’Cabin’特征
‘Cabin’特征由三个部分信息组成:Cabin desk(船舱桌子)、Cabin number(船舱号码)和Cabin side(船舱侧面)。我们将删除正斜杠并将这三个信息部分分开,并创建包含这三个Cabin特征部分的三个新特征。创建了三个新特征后,我们将删除原始的Cabin特征。
## 从Cabin特征值中删除'/'X['Cabin'] = X['Cabin'].str.replace('/','')## 通过拆分原始的Cabin特征创建三个新特征X['Cabin_deck'] = X['Cabin'].str[0]X['Cabin_num'] = X['Cabin'].str[1].apply(pd.to_numeric)X['Cabin_side'] = X['Cabin'].str[2]## 删除原始的Cabin特征X.drop(['Cabin'], axis=1,inplace=True)在船舱特征转换后检查新的数值和分类特征的名称
一些新特征被创建,一些旧特征被移除。因此,让我们再次找出转换后的新分类和数值特征的名称。
## 再次获取数值和分类特征的名称num_feat = [feature for feature in X.columns if X[feature].dtypes != 'O' ]cat_feat = [feature for feature in X.columns if feature not in num_feat]print(f"数据中的数值特征为 {num_feat}。\n")print(f"数据中的分类特征为 {cat_feat}。")
请注意,如果我们有一个布尔数据类型的特征,使用此方法查找数值特征将会给出错误的结果。由于我们的数据集中没有这样的特征,所以我们可以安全地使用此方法。
检查是否存在方差为零的特征
由于数据的方差越高,对因变量的预测的贡献也越高,我们将删除不对预测有贡献的特征,即方差为零的特征。
## 查找方差为零的特征(数值特征)for feature in num_feat: if X[feature].var() == 0: print(feature)这不会输出任何结果,即数据中没有方差为零的数值特征。
## 查找方差为零的特征(分类特征)for feature in cat_feat: if X[feature].nunique() == 1: print(feature)这个代码块也不会输出任何结果,即数据中没有方差为零的分类特征。
检查分类特征中的唯一值
检查分类特征数据中的唯一值及其计数。如果任何分类特征具有非常多的唯一值,那么我们将删除该列。这是因为这样的列更不可能对我们的模型训练有很大贡献。
## 检查每个分类特征中的唯一值for feature in cat_feat: print(f"{feature}中的唯一值为 {X[feature].unique()}(共 {X[feature].nunique()} 个)。\n")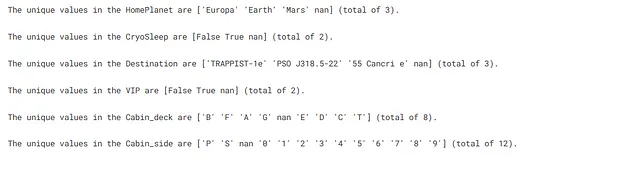
在这里,我们似乎没有一个具有非常多唯一值的分类特征。
检查独立特征与因变量之间的相关性
让我们检查数据特征之间的相关性。这将告诉我们很多信息。其中一些是:
- 独立特征与因变量之间的相关性。如果任何独立特征与我们的因变量之间的相关性非常低,那么该独立特征将对我们的模型训练贡献非常小。因此,我们可以删除该特征。这将使我们只保留与模型训练相关的特征,从而减少模型在数据上的过拟合。
- 独立特征之间的相关性。这将告诉我们哪些独立特征高度相关。假设我们有两个高度相关的特征,那么在这种情况下,我们可以轻松地从数据中删除其中一个特征。这将使我们的模型更加稳健,也可以防止过拟合。
找到数值独立特征与因变量之间的相关性。
## 检查数值独立特征与因变量之间的相关性from sklearn.preprocessing import OrdinalEncoderimport matplotlib.pyplot as pltimport seaborn as snsdf1 = pd.DataFrame(X[num_feat], columns=num_feat) # 包含数值特征的数据框df2 = pd.DataFrame(y, columns=['Transported']) # 包含因变量的数据框df_num = pd.concat([df1, df2], axis=1) # 包含所有数值特征和一个因变量的数据框plt.figure(figsize=(12,8))corr = df_num.corr()mask = np.triu(np.ones_like(corr, dtype=bool))sns.heatmap(corr, annot=True, cmap='coolwarm',mask=mask)plt.tight_layout()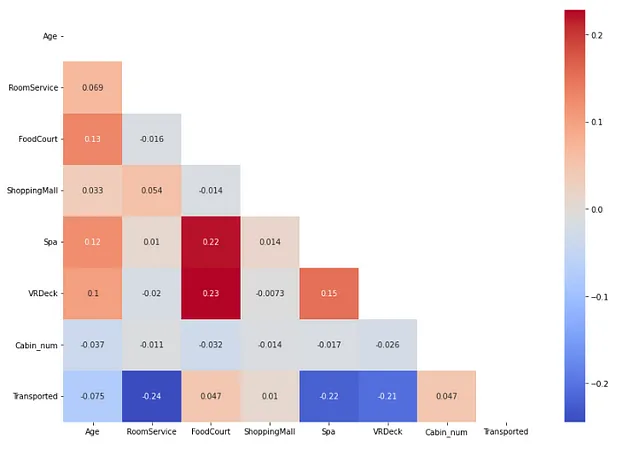
在这里,我们没有找到任何两个高度相关的数字独立特征。
查找分类独立特征与依赖特征之间的相关性。
## 检查分类独立特征与依赖特征之间的相关性from sklearn.preprocessing import OrdinalEncoderdf1 = pd.DataFrame(OrdinalEncoder().fit_transform(X[cat_feat]), columns=cat_feat) # 包含编码后分类特征的数据框df2 = pd.DataFrame(y, columns=['Transported']) # 包含依赖特征的数据框df_cat = pd.concat([df1, df2], axis=1) # 包含所有编码后的分类特征和一个依赖特征的数据框plt.figure(figsize=(12,8))corr = df_cat.corr()mask = np.triu(np.ones_like(corr, dtype=bool))sns.heatmap(corr, annot=True, cmap='coolwarm',mask=mask)plt.tight_layout()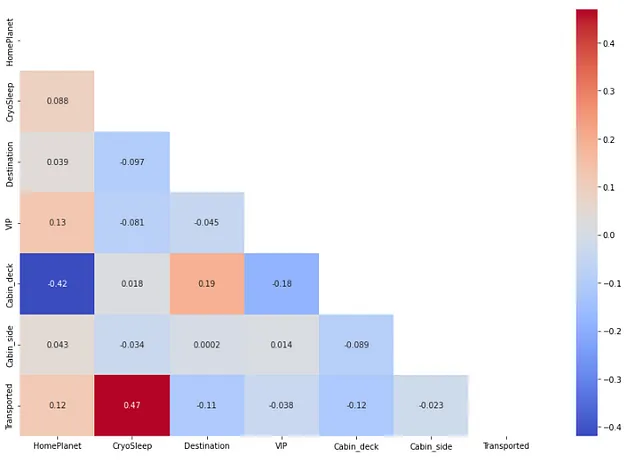
在这里,我们也没有找到任何高度相关的两个分类特征。请注意,在这里我们对分类特征进行了编码以使相关函数工作。
检查数据中的缺失值
## 检查每个特征中缺失值的数量missing_values_df = pd.DataFrame()missing_values_df['特征'] = X.columnsmissing_values_df['缺失值数量'] = X.isnull().sum().to_numpy()missing_values_df['缺失值百分比 (%)'] = missing_values_df['缺失值数量'].apply(lambda x: np.round((x/X.shape[0])*100),2)missing_values_df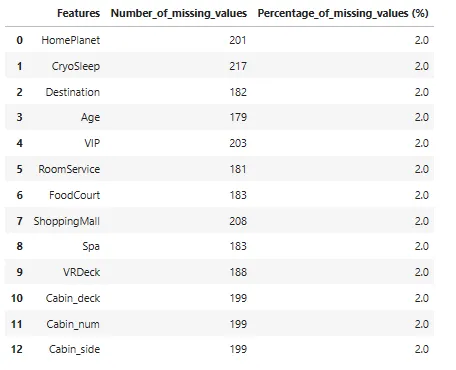
让我们为了好玩可视化一下缺失值。
import missingno as msgnmsgn.matrix(X)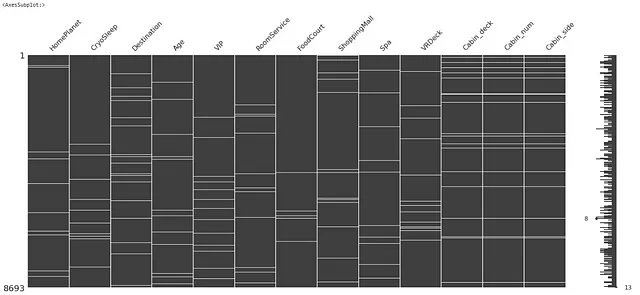
在上图中,数据的每个特征的缺失值用白色线表示。
数据似乎只有非常少的缺失值(约占整个数据大小的2%)
处理缺失值是数据预处理步骤中最重要的任务之一。经常使用删除或填补缺失数据的方法来处理缺失值。但并不总是处理缺失数据的最佳选择。在某些情况下,缺失数据可能是由于收集数据时的特定条件,或者可能存在数据缺失的某种特定模式。
为了澄清这一点,让我们举个例子。假设我们正在进行大学生调查。调查中的一个问题询问一个人的体重。在这种情况下,一些女学生可能不愿在调查中写下自己的体重(这是因为女大学生对自己的体重意识更强。我不知道这是否正确,但让我们为了例子的完整性假设它是正确的)。因此,在女生的情况下,我们将得到很多年龄的缺失值。这是由于某种模式导致的缺失值的例子。
让我们考虑调查的另一种情况。假设我们调查中的另一个问题是关于肌肉力量的。对于这类问题,很多大学男生可能不愿意写下他们的回答(这同样是因为男大学生对自己的体格或力量非常在意)。因此,在男生的情况下,我们将得到很多缺失值。
我们需要根据类似上述标准的标准来决定如何处理缺失值。一种在替换缺失值时保持缺失值模式的方法是使用Scikit-Learn的SimpleImputer,其中的参数名为add_indicator。
使用分布图和箱线图检查数据中离群值的存在
- 使用分布图
如果数据中特征的分布是偏斜的,我们可以确认数据中存在离群值。
## 使用分布图检查数值特征中的离群值sns.set_style('darkgrid')plt.figure(figsize=(22,13))for index, feature in enumerate(num_feat): plt.subplot(3,3,index+1) sns.distplot(X[feature],kde=True, color='b') plt.xlabel(feature) plt.ylabel('distribution') plt.title(f"{feature}分布")plt.tight_layout()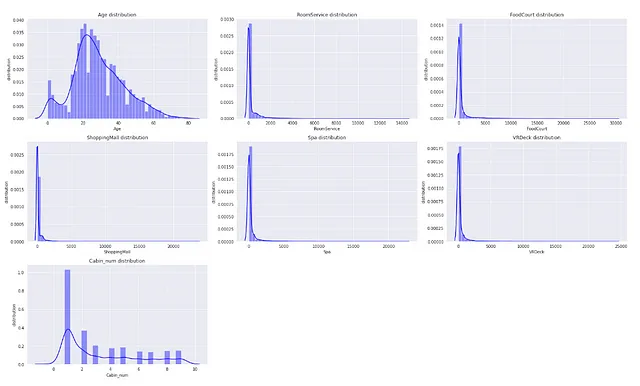
2. 使用箱线图
箱线图是一种更直观的可视化数据中离群值的方法。
如果值>(四分位值3+常数*四分位差)==>值是离群值
如果值<(四分位值1-常数*四分位差)==>值是离群值
通常,常数值使用1.5。在箱线图中,离群值通常用空心圆表示。
## 使用箱线图清楚地可视化离群值X[num_feat].plot(kind='box',figsize=(15,10))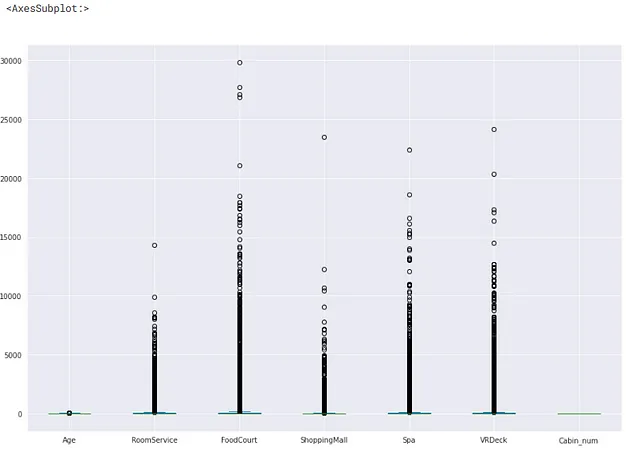
请注意,此分布是在处理数据中的缺失值之前。如果我们填补了缺失值,分布可能会发生变化。因此,在处理数据中的缺失值之后,检查数据的分布是一个好的做法。
对于当前的问题,我们应该在完全从数据中删除离群值之前分析离群值,因为有时离群值的存在可能有助于我们的目的。例如,如果我们正在进行信用卡欺诈检测,则在这种情况下,我们正在寻找数据中的离群值以检测欺诈。因此,删除离群值是没有意义的。但是另一方面,离群值也可能使我们的模型不太准确。下图显示了如何分析问题中的离群值。
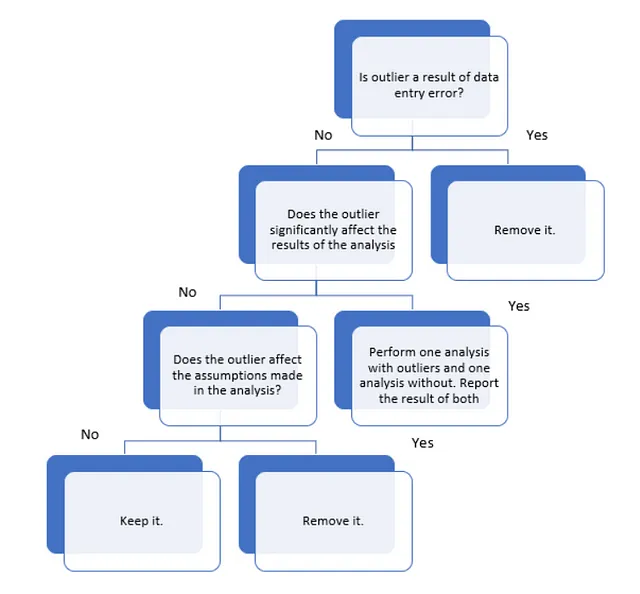
我们的目的是根据乘客的信息(如年龄,他在客房服务上花费了多少等)来预测乘客是否幸存。因此,对于我们的问题,离群值将是年龄非常大或非常小的人,花费在客房服务、美食广场、购物中心、温泉、VRDeck等方面非常高或非常低的人。
按照上面的图表来分析离群值。在我们的问题陈述中,年龄非常高的人等离群值不能被视为任何数据输入的结果。此外,这些离群值很可能会影响我们的模型,因为这些离群值只占我们整个数据的一小部分,因此不能代表我们整个数据。因此,从我们的数据中删除离群值是明智的。
使用pairplot和VIF值检查自变量之间的多重共线性
在我们的分析中,当两个或多个自变量之间高度相关时,多重共线性就会发生,这样它们就无法为我们的机器学习模型训练过程提供独特的信息。我们可以使用三种方法来检查这一点:使用相关图(就像我们上面创建的那个),使用pairplot和使用VIF值。在这三种方法中,VIF是一种确定多重共线性的可靠方法。
在这里,我们将检查数值特征之间的多重共线性。
- 使用pairplot
如果两个特征的图表显示出某种模式,我们可以确定它们之间存在多重共线性。
sns.pairplot(X[num_feat], corner=True,diag_kind='kde')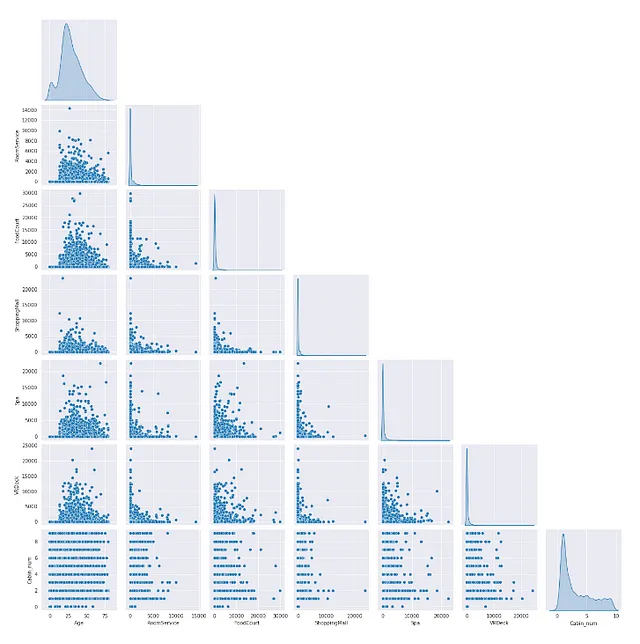
我们在数据的数值特征之间没有看到太多模式。
2. 使用VIF值
解释VIF值:
VIF = 1:给定的预测变量与模型中的其他预测变量之间没有相关性。VIF在1和5之间:给定的预测变量与模型中的其他预测变量之间存在中等相关性。VIF > 5:给定的预测变量与模型中的其他预测变量之间存在严重相关性。
## 在数值独立特征中查找多重共线性# 我们使用以下经验法则来解释VIF值:from patsy import dmatricesfrom statsmodels.stats.outliers_influence import variance_inflation_factorfrom sklearn.impute import SimpleImputer#create DataFrame to hold VIF valuesvif_df = pd.DataFrame()vif_df['Variable'] = num_feat #计算每个预测变量的VIF值#将数据中的缺失值用数据的均值填充后,再将其输入到函数中进行计算num_df = pd.DataFrame(SimpleImputer(strategy='mean').fit_transform(X[num_feat]), columns=num_feat)vif_df['VIF'] = [variance_inflation_factor(num_df.values, i) for i in range(num_df.shape[1])]def mc_check(x): if x == 1: return '低' elif (x > 1 and x = 5): return '严重'vif_df['多重共线性存在'] = vif_df['VIF'].apply(mc_check)#查看每个预测变量的VIF值 print(vif_df)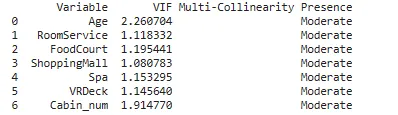
检查分类特征的分布
## 检查分类特征的分布sns.set_style('darkgrid')plt.figure(figsize=(22,7))for index, feature in enumerate(cat_feat): plt.subplot(2,3,index+1) sns.countplot(x=feature,data=X,palette='coolwarm') plt.xlabel(feature) plt.ylabel('分布') plt.title(f"{feature} 分布") plt.tight_layout()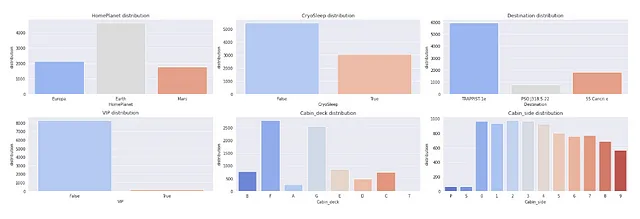
检查数据集是否不平衡
如果依赖特征中每个唯一值的数据点数相差很大,那么数据集被称为不平衡。不平衡的数据集在将数据集分割为训练数据和验证数据时会产生问题。并且在这样的数据上训练的机器学习模型在新数据上的泛化能力不好。
## 检查数据集是否不平衡train['Transported'].value_counts()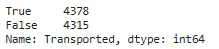
在这里,我们可以看到“True”和“False”的计数并没有相差太多。因此,我们可以得出结论,我们的数据不是不平衡的。
这是一个通常如何进行探索性数据分析(EDA)的非常基本的解释。在EDA中可能涉及许多其他步骤,但这些步骤来自于实践。此外,还有许多其他方法可以创建不同类型的有趣和直观的图形,以可视化数据、异常值、缺失值等等。我强烈推荐探索这些内容。在Kaggle上可以找到很多有趣的想法。
资源
进行EDA的步骤之一是查找具有零方差的特征。要了解方差与特征所包含的信息量之间的关系,请查看Casey Cheng撰写的以下文章。
用零数学概念直观解释主成分分析(PCA)
主成分分析(PCA)是可视化和降维数据的不可或缺的工具…
towardsdatascience.com
在维基百科上了解更多关于箱线图的内容。
本文中使用的代码来自我的Kaggle笔记本。使用以下链接查看完整的代码。
飞船泰坦尼克号-4
使用来自Spaceship Titanic的数据,探索和运行机器学习代码 | Kaggle笔记本
www.kaggle.com
结尾
希望您喜欢这篇文章。在VoAGI上关注我以阅读更多类似的文章。
通过LinkedIn与我联系。
在网站上了解更多关于我的信息。
发送邮件至[email protected]






