PageRank的大规模图分析
PageRank的图分析
了解谷歌搜索引擎如何根据链接结构对文档进行排名
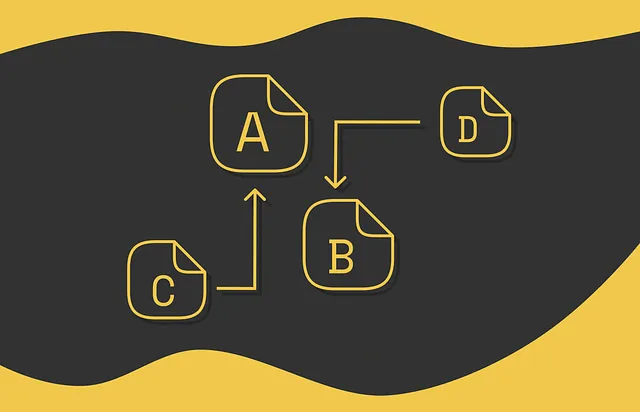
在机器学习中,排名是一个重要的问题。给定一组文档,目标是根据特定的标准对它们进行排序。排名在信息检索系统中被广泛用于对搜索结果进行排序,或者在推荐系统中用于过滤对特定用户可能感兴趣的内容。
根据给定的问题和目标,存在大量的排名算法。本文要研究的算法是名为PageRank的算法。它的主要目标是通过使用有关链接结构的信息对一组文档(网页)进行排名。分配给每个网页的排名表示其重要性:排名越高,重要性越高。该算法基于我们将在下一节中讨论的两个假设。
假设
我们可以通过做两个假设来定义一个网页的“重要性”。
如果有很多其他网页指向一个网页,那么该网页的重要性就很高。
想象一下我们有一篇受欢迎的研究论文,有许多其他文章通过引用或使用其结果与之相关联。主要来说,给这篇文章赋予很高的重要性是有意义的。另一方面,如果有一个未知的网页没有其他资源对其进行链接,那么给该网页赋予低重要性似乎是合乎逻辑的。
在现实中,我们还应该关注传入链接的质量。
一个网页的重要性与指向它的网页的重要性成比例。
如果一个页面最初是由维基百科上一篇高质量的文章引用的,那么这样的链接应该具有更大的权重。相反,当一个完全不知名的资源指向另一个网页时,它通常不应该具有很高的重要性。

形式定义
假设一个节点的重要性等于传入链接的权重之和。
想象一个重要性为rᵢ的节点i有k个传出链接。我们如何确定每个链接的权重?最直接的方法是将节点的重要性平均分配给所有传出链接。这样,每个传出链接将获得rᵢ / k的权重。
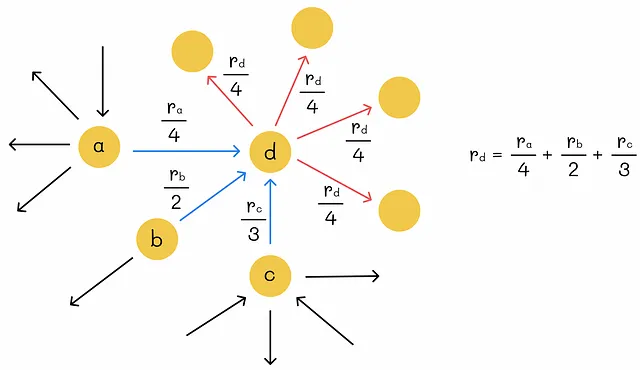
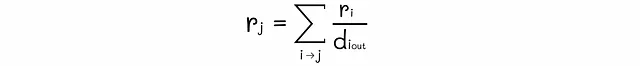
给定一个由n个网页组成的图,我们可以创建一个由n个线性方程组成的系统来找到图的权重。然而,这样的系统可能有无限多个解。这就是为什么我们应该添加另一个约束条件来强制唯一解的原因。顺便说一下,PageRank添加了归一化条件,即所有节点重要性的总和等于1。
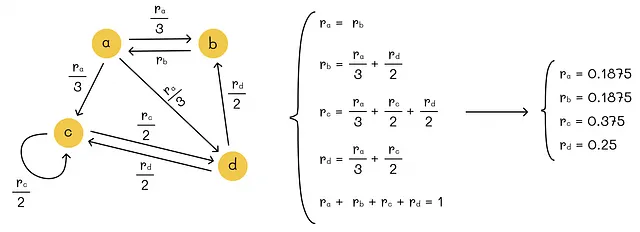
我们已经提出了一个解决方案,但它不具有可扩展性。即使使用高斯消元,我们最终得到的复杂度也是O(n³)。考虑到分析的网页数量n可能达到数十亿,我们需要提出一个更高效的方法。
首先,让我们简化表示法。为此,我们引入邻接矩阵G,其中包含每对链接的网页的链接权重(如果两个网页未链接,则在相应的矩阵元素中放置0)。更正式地说:
![矩阵元素G[j][i]的定义](https://miro.medium.com/v2/resize:fit:640/format:webp/1*xB7oRh5508uhOkBiRjSjlg.png)
矩阵G被称为随机矩阵,因为它的每列之和为1。
接下来,我们定义秩向量r,其中第i个元素等于页面i的秩(重要性)。该向量的所有元素之和也等于1。我们的最终目标是找到该向量r的值。
PageRank方程
让我们看看如果我们将矩阵G乘以向量r会发生什么。根据上一节中的图的示例,我们可以看到结果仍然是相同的向量r!
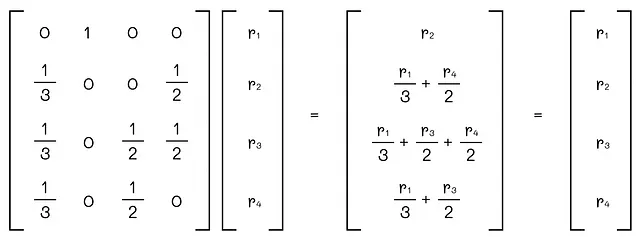
为什么会这样呢?这只是巧合吗?记住,矩阵G的第i行包含页面i的所有输入链接的权重。当我们将第i行的第j个元素乘以r[j]时,实际上我们得到的是组件rj / d[j]out – 从节点j到i流动的重要性。如果节点i和j之间没有链接,则相应的组件设置为0。从逻辑上讲,将向量r乘以矩阵G的最终结果将等于从图的任何连接节点流向节点i的所有重要性的总和。根据定义,该值等于节点i的秩。一般来说,我们可以写出以下方程:
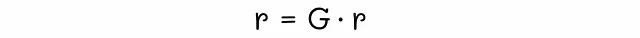
因此,我们的目标是找到这样一个向量r,使得与输入矩阵G相乘后仍然保持不变。
特征向量
我们可以通过修订线性代数中特征向量的理论来找到上述方程的解。给定一个矩阵A,如果存在一个数α满足以下方程,那么向量v被称为特征向量:
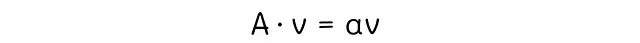
数α被称为特征值。我们可以注意到,PageRank方程对应于特征值方程,其中A = G,v = r,α = 1。通常,任何方阵都有多个特征值和特征向量,但由于我们的矩阵G是随机的,该理论声称其最大特征值等于1。
幂迭代
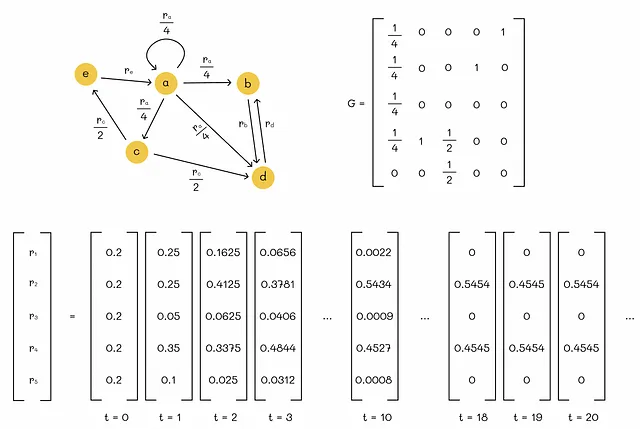
寻找矩阵特征向量的最流行方法之一是幂迭代方法。它的步骤是用一些值(我们将使用 1 / n,其中 n 是网页数量)初始化初始向量 r,然后不断计算 G * r 的值,并将该值再次赋给 r。如果在任何迭代中向量 r 和 G * r 之间的距离小于某个阈值 ε,则停止算法,因为它已经成功收敛。

在上面的示例中,我们可以看到通过将 ε 设置为 0.0005,算法在只经过 9 次迭代后成功收敛:

显然,这只是一个玩具示例,但在实践中,这种方法对于更多的变量也效果非常好。
随机游走
想象一个冲浪者(行走者)在时间 t 时位于图的任何节点上。我们用 p(t) 表示向量,其第 i 个分量等于在时间 t 冲浪者出现在节点 i 上的概率。然后冲浪者随机地(等概率)选择另一个与当前节点连接的节点,并在时间 t + 1 移动到该节点。最终,我们要找到在 t + 1 时刻的分布向量 p(t + 1)。
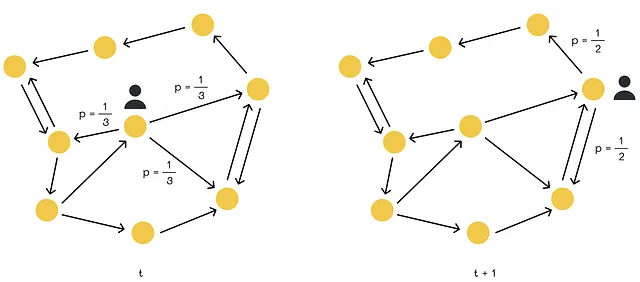
我们可以注意到,冲浪者在 t + 1 时刻出现在节点 i 的概率是(所有与 i 相连的节点的概率之和)乘以从节点 j 移动到节点 i 的概率。
- 我们已经知道冲浪者在时刻 t 出现在节点 j 的概率:p(t)[j]。
- 从节点 j 移动到节点 i 的概率等于 G[j][i]。
通过对这些概率求和,我们得到 p(t + 1)[i] 的值。为了找到所有图节点的 p(t + 1) 的值,我们可以用矩阵形式表示相同的方程:

这个方程与我们之前得到的 PageRank 完全相同!这意味着这两个问题有相同的解决方案和解释。
在某个时刻,分布向量 p(t) 将收敛:p(t + 1) = M * p(t) = p(t)。在这种情况下,收敛的向量 p(t) 被称为稳态分布。在随后的所有时间点,停留在任何给定节点的概率都不会改变。
节点的 PageRank 分数等于冲浪者通过图的随机游走未来出现在该节点的概率。
收敛性
在图中行走的描述过程通常称为“马尔可夫链”。在马尔可夫链理论中存在一个定理,规定:
在图结构满足一定条件的情况下,稳态分布是唯一的,并且可以在 t = 0 时刻用任何初始概率分布达到。
在接下来的部分中,我们将更加深入地探讨需要满足的唯一收敛条件。事实证明,并非所有的图都能达到唯一收敛。
主要地,存在两种情况我们要尽量避免。
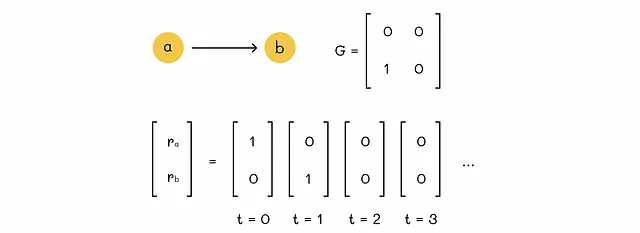
死胡同
没有出链的节点称为死胡同。这种节点的问题在于它们导致网络中的总重要性流失。下面是一个例子:
蜘蛛陷阱
如果一组节点没有指向此组节点外的其他节点的出链,那么它们形成了一个蜘蛛陷阱。基本上,一旦进入这组节点,就无法离开这组节点。蜘蛛陷阱导致以下两个问题:
- 算法永远不会收敛。
- 形成蜘蛛陷阱的节点组吸收了全部图的重要性。因此,这些节点具有很高的重要性,而其他节点的重要性为0。
第一个问题在下面的图中有所说明:
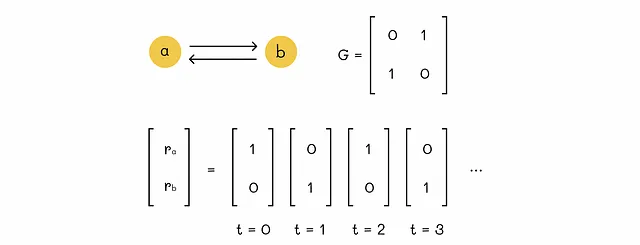
重要性的吸收在下一个图中得到了证明。虽然在下面的示例中可能看起来不是一个严重的问题,但想象一下一个具有数百万个网页的网络,其中几个网页形成蜘蛛陷阱。结果,这几个页面将分配所有可用的重要性,而其他所有网页的重要性将被设置为0。显然,这不是我们在现实生活中通常希望的。
传送
Google 提出的解决方案之一是在冒险者每次移动之前添加以下条件:
- 以概率 β 移动到另一个链接的节点。
- 以概率 (1 — β) 移动到一个随机节点(通过传送)。
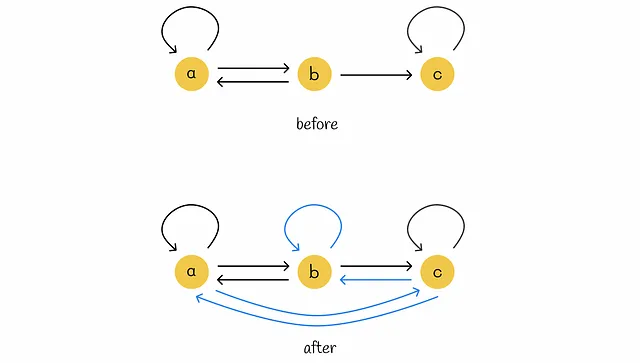
参数 β 被称为阻尼因子。原始的 PageRank 算法的作者建议选择 β = 0.85 的值,这意味着平均经过 5 次转移后,冒险者将随机跳到另一个节点。其想法是,如果冒险者陷入蜘蛛陷阱,那么经过一段时间,它最终将通过传送离开。
下图显示了传送如何帮助解决蜘蛛陷阱问题。如果冒险者走进节点 c,那么它将永远停留在那里。引入传送(蓝色线)有助于消除此问题,保证在一段时间后冒险者必须走向另一个随机节点。
然而,对于死胡同节点,我们需要稍微修改方法。从上面的一个示例中,我们知道死胡同会导致图中的重要性泄漏。在幂迭代方法中,当初始矩阵 G 中存在相应的零列时,这种现象可以观察到,导致排名向量中充满了零。最终,我们可以采取以下措施:
每当冲浪者到达一个死胡同节点时,它应立即跳转到图中的一个随机节点(等概率)。
事实上,我们可以修改初始矩阵 G,以满足这个条件:我们只需要将矩阵 G 中所有死胡同节点的列的所有元素替换为 1 / n。下面的例子演示了这个原理。
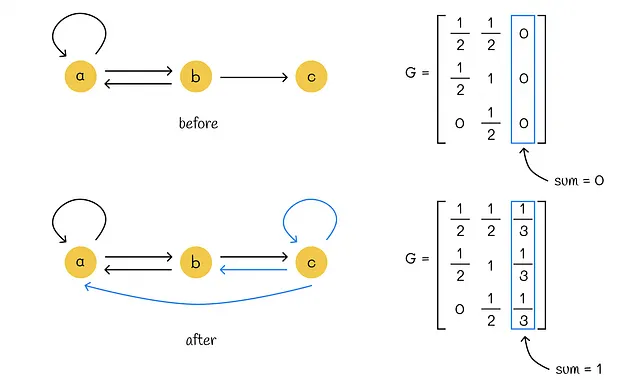
节点 c 是一个死胡同节点,在矩阵 G 中对应的列为零。从 c 到图中的所有节点添加 n = 3 个传送点,使从 c 移动到任何节点的概率 p = 1 / 3 相等。为了满足这个条件,我们将矩阵 G 中对应节点 c 的列填充为 1 / 3。
我们可以注意到,在添加传送点之后,所有矩阵列的总和现在等于 1。换句话说,矩阵 G 变成了随机矩阵。这是一个后面将要使用的重要属性。
收敛条件
从马尔可夫链理论中存在一个关键定理,定义了收敛条件。
对于任何初始向量,转移矩阵 G 如果是随机的、非周期的和不可约的,则收敛到唯一的正定态分布向量 r。
让我们在这个定理中回顾一下最后三个属性,并检查引入的传送点是否解决了上述问题。
如果一个链 G 的每一列的和等于 1,则称其为随机链。
正如我们上面观察到的,向死胡同节点添加传送点消除了矩阵中的零列,并使所有列的总和等于 1。这个条件已经满足。
如果存在一个大于 1 的数字 k,使得任意一对节点之间的路径长度始终是 k 的倍数,则称链 G 为周期性链。否则,链称为非周期性链。
这个条件意味着返回到相同状态的次数必须是 k 的倍数。在非周期性链的情况下,返回发生在不规则的时间。基本上,这个条件涉及到蜘蛛陷阱问题。由于我们通过添加传送点已经解决了蜘蛛陷阱问题,所以链 G 是非周期性的。
如果从一个节点到另一个节点的转移概率始终大于 0,则称链 G 为不可约的。
这个条件意味着任意两个节点之间都存在链接,因此不可能卡在任何节点上。换句话说,矩阵 G 需要由所有非零元素组成。我们将在下面的下一节中看到如何通过连接图中的所有节点来满足这个条件。
修改算法
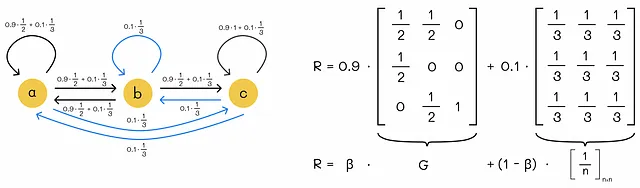
Google 提出的 PageRank 算法将初始矩阵 G 并通过向死胡同添加传送点进行调整,以确保随机性。为了保证非周期性和不可约性,它还对每个节点添加了前面描述的条件:
- 以概率 β 移动到另一个链接节点。
- 以概率 (1 — β) 移动到一个随机节点。
数学上,这导致每个节点的以下等级方程:
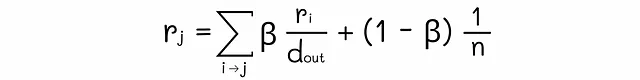
我们可以将这个方程转换成矩阵形式:
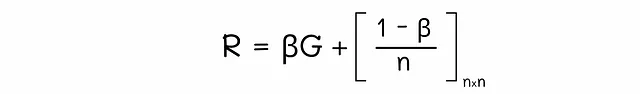
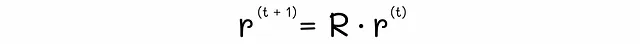
让我们从上面的一个示例中绘制修改后的图形和相应的转移矩阵R:
提高效率
我们唯一剩下的问题是如何存储转移矩阵R。记住,R是一个大小为n x n的方阵,其中n是网页的数量。目前,Google拥有超过250亿个网页!矩阵R没有任何零元素,因此它是稠密的,这意味着我们需要完全存储它。假设每个矩阵元素需要4个字节来存储,存储矩阵R所需的总内存大小为(25 * 10⁹)² * 4(字节)约为3 * 10²¹(字节)。这是一个巨大的内存大小!我们需要想出另一种方法,至少减少几个数量级。
首先,我们可以简单地注意到添加跳转等效于将初始矩阵G的元素减少(1-β)%,并将它们均匀分布到每个节点上。记住这一点,我们可以将PageRank的矩阵方程转换为另一种格式:

让我们看看最后获得的方程式。G是初始链接矩阵,其中大部分元素都等于0。为什么会这样呢?实际上,如果你查看任何一个网页,它可能最多含有几十个链接到其他网页的链接。考虑到有超过250亿个网页,我们可以得出相对于网页数量的总链接数的相对比例非常小。因此,G中有很多零元素,所以G是稀疏的。
存储稀疏矩阵所需的内存比稠密矩阵要少得多。假设每个网页平均链接到其他40个页面,现在存储矩阵G所需的总字节数变为25 * 10⁹ * 40(字节)= 10¹²(字节)= 1(TB)。事实证明,我们只需要1 TB来存储G。与之前相比,这是一个巨大的改进!
实际上,在每次迭代中,我们只需要计算矩阵G乘以向量r的乘积,将其乘以β,并将常数(1-β)/ n添加到结果向量的每个元素。
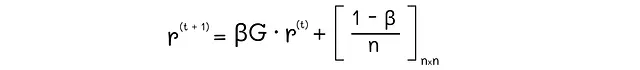
还要记住,如果初始链G包含死胡同节点,则每次迭代时向量r的总和将小于1。为了处理这个问题,只需要对其进行重新归一化,使所有向量分量的总和为1。
完整算法
在下面的图中,我们可以看到完整版本的PageRank算法。在每次迭代中,排名的更新分为2个阶段。第一阶段仅根据初始矩阵G进行更新。然后,我们将排名向量的分量求和到变量s中。这样,(1-s)的值就是单个节点总输入排名减少的值。为了补偿这一点,在第二阶段中,我们考虑了跳转,并将它们从一个节点添加到所有具有相等的(1-s)/ n值的节点。

结论
在本文中,我们已经查看了不同形式的PageRank算法,最终得出了其优化版本。尽管存在和发展了其他用于排名搜索结果的方法,PageRank仍然是谷歌搜索引擎中最高效的算法之一。
参考资料
本文的逻辑结构基于斯坦福大学关于大型图的讲座。
- 大型图的分析:链接分析,PageRank
- 海量数据集的挖掘 | Jure Leskovec, Anand Rajaraman, Jeff Ullman
- PageRank:站在巨人的肩膀上
除非另有说明,所有图片均由作者提供





