介绍 Optimum:大规模变压器的优化工具包
Optimum是一个用于大规模变压器优化的工具包
这篇文章是Hugging Face实现最先进的机器学习生产性能的第一步。为了实现这一目标,我们将与我们的硬件合作伙伴紧密合作,就像我们与Intel一样。加入我们的旅程,并关注我们的新开源库Optimum!
为什么选择🤗 Optimum?
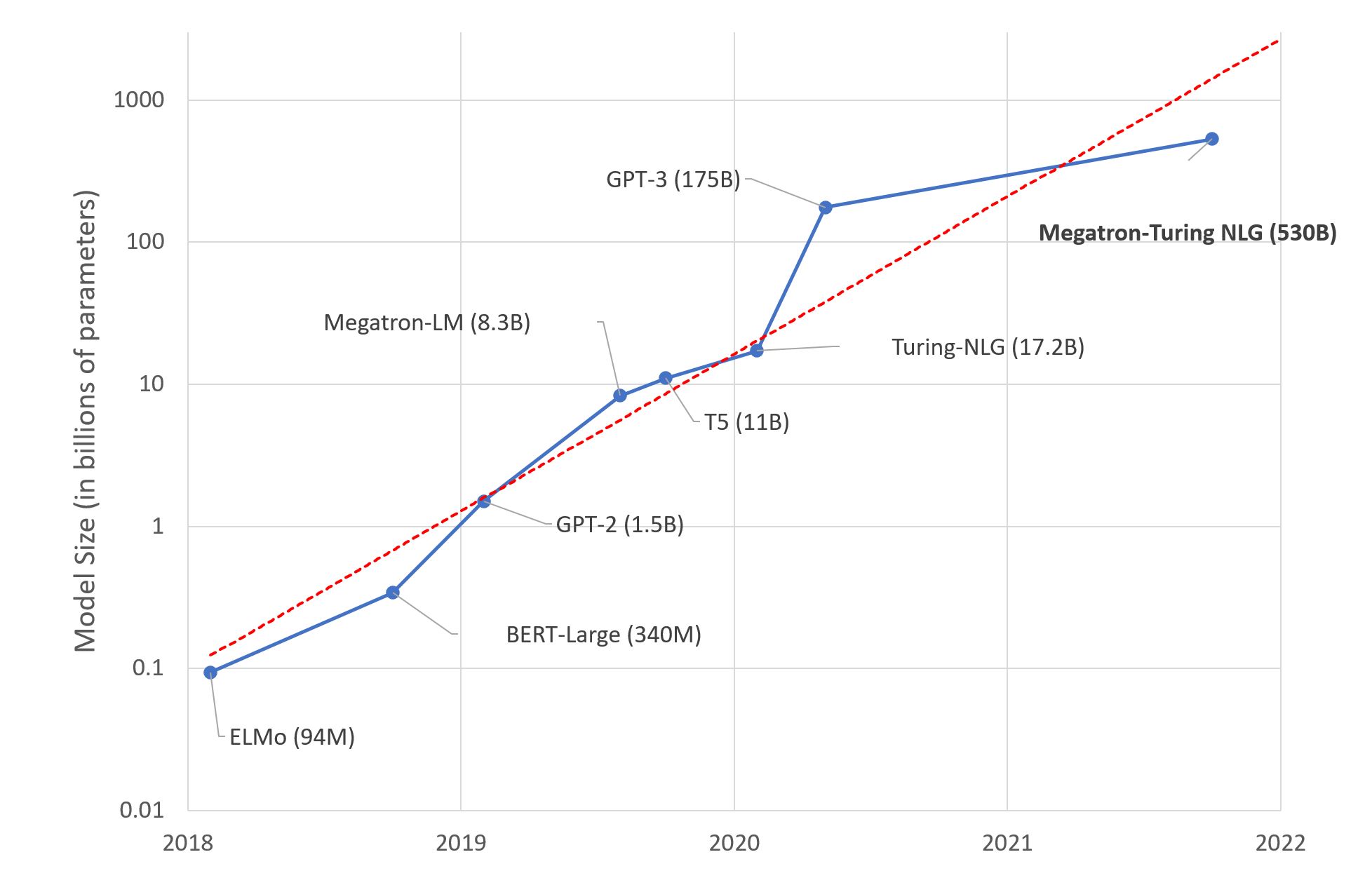
🤯 扩展Transformer很困难
特斯拉、谷歌、微软和Facebook有什么共同之处?有很多,其中之一就是它们每天都运行数十亿个Transformer模型的预测。Transformer用于特斯拉自动驾驶(真幸运!)、Gmail自动完成句子、Facebook实时翻译帖子以及Bing回答自然语言问题。
Transformer在提高机器学习模型准确性方面取得了重大突破,征服了自然语言处理,并正在扩展到以语音和视觉为起点的其他模态。但是,将这些庞大的模型投入生产,并使它们在大规模运行时运行得快是任何机器学习工程团队面临的巨大挑战。
如果您没有像上述公司那样拥有数百名高技能的机器学习工程师,通过我们的新开源库Optimum,我们旨在构建用于Transformer生产性能的权威工具包,并实现在特定硬件上训练和运行模型的最高效率。
- Hugging Face 和 Graphcore 合作,为 IPU 优化的 Transformer 提供支持
- 使用Streamlit在Hugging Face Spaces上托管您的模型和数据集
- 使用遥感(卫星)图像和标题对CLIP进行微调
🏭 Optimum让Transformer投入工作
为了获得最佳性能的训练和服务模型,模型加速技术需要与目标硬件特别兼容。每个硬件平台都提供特定的软件工具、功能和调节,对性能有巨大影响。同样,为了利用稀疏和量化等先进的模型加速技术,优化的内核需要与硅上的运算符兼容,并且特定于从模型架构派生的神经网络图。深入研究这个三维兼容矩阵以及如何使用模型加速库是令人望而却步的工作,很少有机器学习工程师有经验。
Optimum旨在简化这项工作,提供针对高效AI硬件的性能优化工具,与我们的硬件合作伙伴共同构建,并将机器学习工程师转变为ML优化专家。
通过Transformer库,我们使研究人员和工程师能够轻松使用最先进的模型,摒弃了框架、架构和流程的复杂性。
通过Optimum库,我们使工程师能够轻松利用所有可用的硬件功能,摒弃了在硬件平台上加速模型的复杂性。
🤗 Optimum实践:如何将模型量化为Intel Xeon CPU
🤔 为什么量化很重要但难以正确实现
BERT等预训练语言模型在各种自然语言处理任务上取得了最先进的结果,基于Transformer的其他模型,如ViT和Speech2Text,在计算机视觉和语音任务上也取得了最先进的结果:Transformer无处不在,且将会持续存在于机器学习领域。
然而,将基于Transformer的模型投入生产可能会很棘手且昂贵,因为它们需要大量的计算资源才能运行。为了解决这个问题,存在许多技术,其中最流行的是量化。不幸的是,在大多数情况下,量化模型需要大量的工作,原因有很多:
- 需要对模型进行编辑:一些操作需要替换为它们的量化对应操作,需要插入新的操作(量化和反量化节点),并且需要根据将量化权重和激活。
这部分可能非常耗时,因为PyTorch等框架工作在急切模式下,意味着上述更改需要添加到模型实现本身。PyTorch现在提供了一个名为torch.fx的工具,可以在不实际更改模型实现的情况下跟踪和转换模型,但是当跟踪不支持您的模型时,使用起来很棘手。
除了实际的编辑之外,还需要找出哪些部分的模型需要进行编辑,哪些操作有可用的量化内核对应操作,哪些操作没有对应操作等等。
-
模型编辑完成后,还有许多参数可以调整,以找到最佳的量化设置:
- 哪种观察器应该用于范围校准?
- 应该使用哪种量化方案?
- 我的目标设备支持哪种量化相关的数据类型(int8、uint8、int16)?
-
在量化和可接受的精度损失之间权衡。
-
将量化模型导出到目标设备。
尽管PyTorch和TensorFlow在使量化变得容易方面取得了巨大进展,但基于Transformer的模型的复杂性使得难以直接使用提供的工具并在不费太多精力的情况下获得可行的结果。
💡 Intel如何通过神经压缩解决量化问题以及其他问题
Intel® Neural Compressor(以前称为低精度优化工具或LPOT)是一个开源的Python库,旨在帮助用户部署低精度推理解决方案。后者将低精度的深度学习模型应用于实现预期的性能指标,如推理性能和内存使用量等产品目标。神经压缩支持后训练量化、量化感知训练和动态量化。为了指定量化方法、目标和性能指标,用户必须提供一个配置yaml文件来指定调整参数。配置文件可以托管在Hugging Face的模型仓库上,也可以通过本地目录路径给出。
🔥 如何使用Optimum轻松量化Intel Xeon CPU上的Transformers

关注 🤗 Optimum:民主化机器学习生产性能之旅
⚡️最先进的硬件
Optimum将专注于在专用硬件上实现最佳生产性能,可以应用软件和硬件加速技术以实现最大效率。我们将与硬件合作伙伴携手合作,以实现、测试和维护加速,并通过Optimum以一种简单易用的方式进行交付,就像我们与Intel和Neural Compressor一样。我们很快将宣布新加入我们的机器学习效率之旅的硬件合作伙伴。
🔮最先进的模型
与硬件合作伙伴的合作将产生硬件特定的优化模型配置和工件,我们将通过Hugging Face模型仓库向AI社区提供这些模型。我们希望Optimum和经过优化的硬件模型能够加速生产工作负载的效率采用,这些工作负载占到了机器学习的绝大部分能源。最重要的是,我们希望Optimum能够推动Transformers在规模上的应用,不仅适用于最大的科技公司,而且适用于我们所有人。
🌟合作之旅:加入我们,关注我们的进展
每个旅程都始于第一步,我们的第一步是公开发布Optimum。加入我们,通过给这个库点亮一颗星,跟随我们的步伐,以便我们介绍新的支持硬件、加速技术和优化模型。
如果您希望看到Optimum支持新的硬件和功能,或者您有兴趣加入我们在软件和硬件交叉领域的工作,请通过[email protected]与我们联系。