Perceiver IO:一种可扩展的、完全注意力模型,适用于任何模态
Perceiver IO an extensible, fully attention-based model for any modality.
简介
我们在Transformer中添加了Perceiver IO,这是第一个基于Transformer的神经网络,可以处理各种模态(文本、图像、音频、视频、点云等)及其组合。请查看以下部分以查看一些示例:
- 预测图像之间的光流
- 对图像进行分类
我们还提供了几个笔记本。下面是该模型的技术解释。
介绍
Transformer最初由Vaswani等人于2017年提出,在AI社区引起了一场革命,最初在机器翻译的最新成果上取得了突破。2018年,BERT发布,它是一个仅包含Transformer编码器的模型,击败了自然语言处理(NLP)领域的基准测试,最著名的是GLUE基准测试。
不久之后,AI研究人员开始将BERT的思想应用到其他领域。以下是一些例子:
- Facebook AI的Wav2Vec2表明该架构可以扩展到音频领域
- Google AI的Vision Transformer(ViT)表明该架构在图像领域表现非常出色
- 最近,Google AI的Video Vision Transformer(ViViT)将该架构应用到了视频领域
在所有这些领域中,由于这种强大架构与大规模预训练的结合,最新的成果得到了显著提升。
然而,Transformer的架构存在一个重要的限制:由于其自注意机制,它在计算和内存方面的扩展性非常差。在每一层中,所有输入被用来生成查询和键,然后计算它们的点积。因此,如果没有某种形式的预处理,就无法对高维数据应用自注意机制。例如,Wav2Vec2通过使用特征编码器将原始波形转换为基于时间的特征序列来解决这个问题。Vision Transformer(ViT)将图像划分为一系列不重叠的补丁,这些补丁作为“标记”使用。Video Vision Transformer(ViViT)从视频中提取不重叠的时空“管道”,这些管道作为“标记”使用。为了使Transformer适用于特定的模态,通常将其离散化为一系列标记。
Perceiver
Perceiver通过在一组潜变量上使用自注意机制来解决这个限制,而不是在输入上使用自注意机制。输入(可以是文本、图像、音频、视频)只用于与潜变量进行交叉注意力。这样做的好处是大部分计算发生在潜变量空间中,其中计算是廉价的(通常使用256或512个潜变量)。结果架构对输入大小没有二次依赖性:Transformer编码器仅对输入大小线性依赖,而潜变量的注意力与之无关。在后续的一篇名为Perceiver IO的论文中,作者将这个想法扩展到让Perceiver也处理任意输出。思想类似:只有用输出与潜变量进行交叉注意力。请注意,我将在本博文中交替使用“Perceiver”和“Perceiver IO”这两个术语来指代Perceiver IO模型。
在下一部分中,我们将更详细地介绍Perceiver IO的工作原理,通过介绍其在HuggingFace Transformers中的实现,这是一个流行的库,最初用于实现基于Transformer的NLP模型,但现在也开始为其他领域实现这些模型。在下面的部分中,我们将详细解释Perceiver如何预处理和后处理任何类型的模态,以张量形状为单位。
HuggingFace Transformers中的所有Perceiver变体都基于PerceiverModel类。要初始化PerceiverModel,可以为模型提供3个额外的实例:
- 预处理器
- 解码器
- 后处理器
请注意,每个都是可选的。只有在没有对输入(如文本、图像、音频、视频)进行嵌入时才需要预处理器。只有在想要将Perceiver编码器的输出(即潜变量的最后隐藏状态)解码为更有用的内容(如分类logits或光流)时,才需要解码器。只有在将解码器的输出转换为特定特征时才需要后处理器(这只在进行自编码时需要,后面我们会进一步介绍)。下图显示了该架构的概览。

感知器架构。
换句话说,inputs(可以是任何模态或其组合)首先可以选择性地使用preprocessor进行预处理。接下来,经过预处理的输入与感知器编码器的潜在变量进行交叉注意力操作。在此操作中,潜在变量产生查询(Q),而经过预处理的输入产生键和值(KV)。完成此操作后,感知器编码器使用一组可重复的自注意力层块来更新潜在变量的嵌入。编码器最终将生成一个形状为(batch_size, num_latents, d_latents)的张量,其中包含潜在变量的最后隐藏状态。接下来,有一个可选的decoder,可以用于将潜在变量的最终隐藏状态解码为更有用的内容,例如分类logits。这是通过执行交叉注意力操作来实现的,其中可训练的嵌入用于产生查询(Q),而潜在变量用于产生键和值(KV)。最后,有一个可选的postprocessor,可以用于将解码器输出后处理为特定特征。
让我们首先展示如何实现适用于文本的感知器。
适用于文本的感知器
假设有人想要将感知器应用于文本分类。由于感知器的自注意力机制的内存和时间要求不依赖于输入的大小,因此可以直接将原始的UTF-8字节提供给模型。这是有益的,因为熟悉的基于Transformer的模型(如BERT和RoBERTa)都使用某种形式的显式标记化,例如WordPiece、BPE或SentencePiece,这可能会有害。为了与BERT进行公平比较(BERT使用512个子词标记的序列长度),作者使用了2048个字节的输入序列。假设还添加一个批次维度,那么模型的inputs的形状为(batch_size, 2048)。inputs包含了一个文本片段的字节ID(类似于BERT的input_ids)。可以使用PerceiverTokenizer将文本转换为长度为2048的字节ID序列,并进行填充:
from transformers import PerceiverTokenizer
tokenizer = PerceiverTokenizer.from_pretrained("deepmind/language-perceiver")
text = "你好 世界"
inputs = tokenizer(text, padding="max_length", return_tensors="pt").input_ids在这种情况下,将PerceiverTextPreprocessor作为预处理器提供给模型,它将负责嵌入inputs(即将每个字节ID转换为相应的向量),并添加绝对位置嵌入。作为解码器,将PerceiverClassificationDecoder提供给模型(它将最后的潜在变量的隐藏状态转换为分类logits)。不需要后处理器。换句话说,文本分类的感知器模型(在HuggingFace Transformers中称为PerceiverForSequenceClassification)的实现如下:
from torch import nn
from transformers import PerceiverModel
from transformers.models.perceiver.modeling_perceiver import PerceiverTextPreprocessor, PerceiverClassificationDecoder
class PerceiverForSequenceClassification(nn.Module):
def __init__(self, config):
super().__init__(config)
self.perceiver = PerceiverModel(
config,
input_preprocessor=PerceiverTextPreprocessor(config),
decoder=PerceiverClassificationDecoder(
config,
num_channels=config.d_latents,
trainable_position_encoding_kwargs=dict(num_channels=config.d_latents, index_dims=1),
use_query_residual=True,
),
)可以在这里看到解码器已使用可训练的位置编码参数进行初始化。为什么这样做?让我们详细看看感知器IO是如何工作的。在初始化时,PerceiverModel内部定义了一组潜在变量,如下所示:
from torch import nn
self.latents = nn.Parameter(torch.randn(config.num_latents, config.d_latents))在感知器IO论文中,使用256个潜在变量,并将潜在变量的维度设置为1280。如果还添加一个批次维度,则感知器的潜在变量的形状为(batch_size, 256, 1280)。首先,预处理器(在初始化时提供)将负责将UTF-8字节ID嵌入到嵌入向量中。因此,PerceiverTextPreprocessor将将形状为(batch_size, 2048)的inputs转换为形状为(batch_size, 2048, 768)的张量,假设每个字节ID被转换为大小为768的向量(这由PerceiverConfig的d_model属性决定)。
在这之后,Perceiver IO在形状为(batch_size,256,1280)的潜变量(产生查询)和形状为(batch_size,2048,768)的预处理输入(产生键和值)之间应用交叉注意力。此初始交叉注意力操作的输出是一个与查询(在本例中为潜变量)具有相同形状的张量。换句话说,交叉注意力操作的输出形状为(batch_size,256,1280)。
接下来,对潜变量的表示应用(可重复)的自注意力层块以更新。请注意,这些表示不依赖于输入(即字节)的长度,因为这些仅在交叉注意力操作期间使用。在Perceiver IO论文中,使用了一块包含26个自注意力层(每个层有8个注意力头)的块来更新文本模型的潜变量的表示。请注意,这26个自注意力层之后的输出仍然具有与最初提供给编码器的输入相同的形状:(batch_size,256,1280)。这些也称为潜变量的“最后隐藏状态”。这与提供给BERT的令牌的“最后隐藏状态”非常相似。
好了,现在我们有了形状为(batch_size,256,1280)的最终隐藏状态。很棒,但实际上我们想要将其转换为形状为(batch_size,num_labels)的分类概率。我们如何让Perceiver输出这些呢?
这是由PerceiverClassificationDecoder处理的。其思想与将输入映射到潜空间时所做的工作非常相似:使用交叉注意力。但现在,潜变量将产生键和值,并且我们提供一个任意形状的张量 – 在这种情况下,我们将提供一个形状为(batch_size,1,num_labels)的张量,它将充当查询(作者将其称为“解码器查询”,因为它们在解码器中使用)。此张量将在训练开始时随机初始化,并进行端到端训练。正如您可以看到的,我们只是提供了一个虚拟的序列长度维度为1。请注意,QKV注意力层的输出形状始终与查询的形状相同 – 因此,解码器将输出一个形状为(batch_size,1,num_labels)的张量。然后,解码器只需将此张量压缩为形状为(batch_size,num_labels)的张量,一切就完成了,我们就有了分类概率。
很棒,是吗?Perceiver的作者还表明,对于类似BERT的掩码语言建模,对Perceiver进行预训练也是直截了当的。此模型还可在HuggingFace Transformers中使用,并称为PerceiverForMaskedLM。与PerceiverForSequenceClassification唯一的区别是它不使用PerceiverClassificationDecoder作为解码器,而是使用PerceiverBasicDecoder将潜变量解码为形状为(batch_size,2048,1280)的张量。在此之后,添加了一个语言建模头,将其转换为形状为(batch_size,2048,vocab_size)的张量。Perceiver的词汇量仅为262,即256个UTF-8字节ID和6个特殊符号。通过在英文维基百科和C4上对Perceiver进行预训练,作者表明,在微调后可以在GLUE上获得81.8的综合得分。
图像Perceiver
现在我们已经看到了如何将Perceiver应用于文本分类,将Perceiver应用于图像分类也很简单。唯一的区别是我们将为模型提供不同的preprocessor,该preprocessor将嵌入图像inputs。Perceiver的作者实际上尝试了3种不同的预处理方式:
- 将像素值展平,应用卷积层(卷积核大小为1)并添加学习得到的绝对1D位置嵌入。
- 将像素值展平并添加固定的2D傅立叶位置嵌入。
- 应用2D卷积+最大池化层并添加固定的2D傅立叶位置嵌入。
这些方式都在Transformers库中实现,并分别称为PerceiverForImageClassificationLearned、PerceiverForImageClassificationFourier和PerceiverForImageClassificationConvProcessing。它们之间唯一的区别是PerceiverImagePreprocessor的配置。让我们更详细地看一下PerceiverForImageClassificationLearned。它初始化了一个PerceiverModel如下:
from torch import nn
from transformers import PerceiverModel
from transformers.models.perceiver.modeling_perceiver import PerceiverImagePreprocessor, PerceiverClassificationDecoder
class PerceiverForImageClassificationLearned(nn.Module):
def __init__(self, config):
super().__init__(config)
self.perceiver = PerceiverModel(
config,
input_preprocessor=PerceiverImagePreprocessor(
config,
prep_type="conv1x1",
spatial_downsample=1,
out_channels=256,
position_encoding_type="trainable",
concat_or_add_pos="concat",
project_pos_dim=256,
trainable_position_encoding_kwargs=dict(num_channels=256, index_dims=config.image_size ** 2),
),
decoder=PerceiverClassificationDecoder(
config,
num_channels=config.d_latents,
trainable_position_encoding_kwargs=dict(num_channels=config.d_latents, index_dims=1),
use_query_residual=True,
),
)可以看到PerceiverImagePreprocessor被初始化为prep_type = "conv1x1",并添加了可训练的位置编码参数。那么这个预处理器是如何工作的呢?假设我们给模型提供了一批图像。首先,我们对图像进行中心裁剪,将分辨率裁剪为224,并将颜色通道进行归一化,使得inputs的形状为(batch_size, num_channels, height, width) = (batch_size, 3, 224, 224)。我们可以使用PerceiverFeatureExtractor来实现:
from transformers import PerceiverFeatureExtractor
import requests
from PIL import Image
feature_extractor = PerceiverFeatureExtractor.from_pretrained("deepmind/vision-perceiver")
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
inputs = feature_extractor(image, return_tensors="pt").pixel_valuesPerceiverImagePreprocessor(使用上述设置)首先应用一个卷积层,卷积核大小为(1, 1),将inputs转换为形状为(batch_size, 256, 224, 224)的张量,从而增加了通道维度。然后,它将通道维度放在最后,现在我们有一个形状为(batch_size, 224, 224, 256)的张量。接下来,它将空间(高度+宽度)维度展平,得到形状为(batch_size, 50176, 256)的张量。然后,它将其与可训练的一维位置嵌入进行拼接。由于位置嵌入的维度被定义为256(参见上面的num_channels参数),所以最终得到了一个形状为(batch_size, 50176, 512)的张量。这个张量将用于与潜在特征进行交叉注意力操作。
作者对所有图像模型使用512个潜在特征,并将潜在特征的维度设置为1024。因此,潜在特征是一个形状为(batch_size, 512, 1024)的张量(假设我们添加了一个批次维度)。交叉注意力层以形状为(batch_size, 512, 1024)的查询和形状为(batch_size, 50176, 512)的键和值作为输入,并产生一个形状与查询相同的张量,因此输出一个形状为(batch_size, 512, 1024)的新张量。接下来,重复应用6个自注意力层的块(共8次),得到形状为(batch_size, 512, 1024)的最终隐藏状态。为了将其转换为分类logits,使用PerceiverClassificationDecoder,它的工作方式与文本分类的类似:使用潜在特征作为键+值,并使用形状为(batch_size, 1, num_labels)的可训练位置嵌入作为查询。交叉注意力操作的输出是一个形状为(batch_size, 1, num_labels)的张量,将其压缩为形状为(batch_size, num_labels)的分类logits。
Perceiver的作者表明,与主要用于图像分类的模型(如ResNet或ViT)相比,该模型能够取得强大的结果。在JFT上进行大规模预训练后,使用卷积+最大池预处理(PerceiverForImageClassificationConvProcessing)在ImageNet上达到了84.5的top-1准确率。值得注意的是,PerceiverForImageClassificationLearned只使用了一维完全可学习的位置编码,在没有关于图像二维结构的特权信息的情况下,准确率达到了72.7。
Perceiver光流
作者展示了Perceiver在光流上的应用也是很直接的,光流是计算机视觉中一个几十年历史的问题,具有广泛的应用。关于光流的介绍,可以参考这篇博文。给定同一场景的两幅图像(例如连续的视频帧),任务是估计第一幅图像中每个像素的2D位移。现有的算法相当于手工设计和复杂,然而使用Perceiver,这个问题变得相对简单。这个模型在Transformers库中实现,并且以PerceiverForOpticalFlow的形式提供。它的实现如下:
from torch import nn
from transformers import PerceiverModel
from transformers.models.perceiver.modeling_perceiver import PerceiverImagePreprocessor, PerceiverOpticalFlowDecoder
class PerceiverForOpticalFlow(nn.Module):
def __init__(self, config):
super().__init__(config)
fourier_position_encoding_kwargs_preprocessor = dict(
num_bands=64,
max_resolution=config.train_size,
sine_only=False,
concat_pos=True,
)
fourier_position_encoding_kwargs_decoder = dict(
concat_pos=True, max_resolution=config.train_size, num_bands=64, sine_only=False
)
image_preprocessor = PerceiverImagePreprocessor(
config,
prep_type="patches",
spatial_downsample=1,
conv_after_patching=True,
conv_after_patching_in_channels=54,
temporal_downsample=2,
position_encoding_type="fourier",
# position_encoding_kwargs
fourier_position_encoding_kwargs=fourier_position_encoding_kwargs_preprocessor,
)
self.perceiver = PerceiverModel(
config,
input_preprocessor=image_preprocessor,
decoder=PerceiverOpticalFlowDecoder(
config,
num_channels=image_preprocessor.num_channels,
output_image_shape=config.train_size,
rescale_factor=100.0,
use_query_residual=False,
output_num_channels=2,
position_encoding_type="fourier",
fourier_position_encoding_kwargs=fourier_position_encoding_kwargs_decoder,
),
)可以看到,PerceiverImagePreprocessor被用作预处理器(即为交叉注意力操作与潜在特征进行交互准备两幅图像),PerceiverOpticalFlowDecoder被用作解码器(即将潜在特征的最终隐藏状态解码为实际的预测光流)。对于每个帧,作者提取每个像素周围的3 x 3补丁,导致每个像素有3 x 3 x 3 = 27个值(因为每个像素还有3个颜色通道)。作者使用(368, 496)的训练分辨率。如果将每个训练样本的两个尺寸为(368, 496)的帧叠加在一起,则模型的输入形状为(batch_size, 2, 27, 368, 496)。
预处理器(使用上述设置)将首先沿着通道维度连接帧,得到形状为(batch_size, 368, 496, 54)的张量,假设通道维度也被移动到最后。作者在论文中解释了为什么沿着通道维度进行连接是有意义的(第8页)。接下来,空间维度被展平,得到形状为(batch_size, 368*496, 54) = (batch_size, 182528, 54)的张量。然后,位置嵌入(每个嵌入的维度为258)被连接,得到最终的预处理输入,形状为(batch_size, 182528, 322)。这些将用于与潜在特征进行交叉注意力。
作者在光流模型中使用2048个潜在特征(是的,2048个!),每个潜在特征的维度为512。因此,潜在特征的形状为(batch_size, 2048, 512)。在交叉注意力之后,又得到了一个相同形状的张量(因为潜在特征作为查询)。接下来,将应用24个自注意力层的单个块(每个层都有16个注意力头)来更新潜在特征的嵌入。
为了将潜在特征的最终隐藏状态解码为实际的预测光流,PerceiverOpticalFlowDecoder简单地使用形状为(batch_size, 182528, 322)的预处理输入作为交叉注意力操作的查询。接下来,这些被投影到形状为(batch_size, 182528, 2)的张量。最后,将其重新调整和重塑回原始图像的尺寸,得到形状为(batch_size, 368, 496, 2)的预测光流。作者声称在包括Sintel和KITTI在内的重要基准测试中取得了最先进的结果,当使用AutoFlow进行训练时,AutoFlow是一个包含40万个带有注释的图像对的大型合成数据集。
下面的视频展示了两个示例上的预测流量。

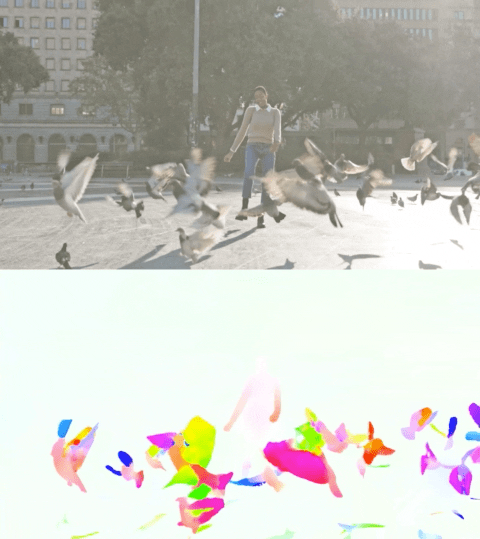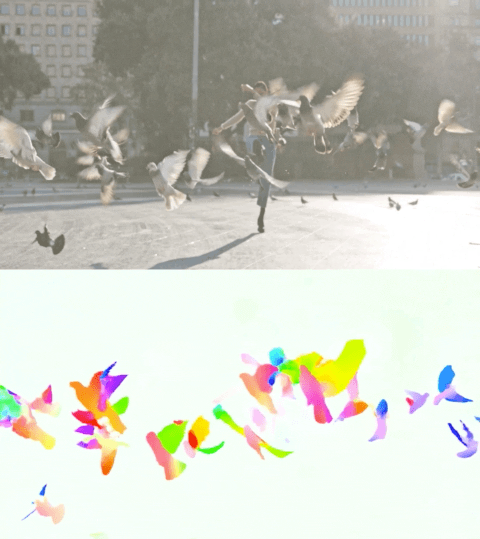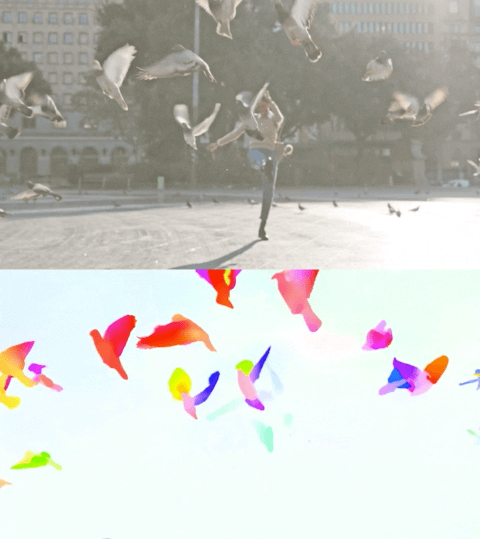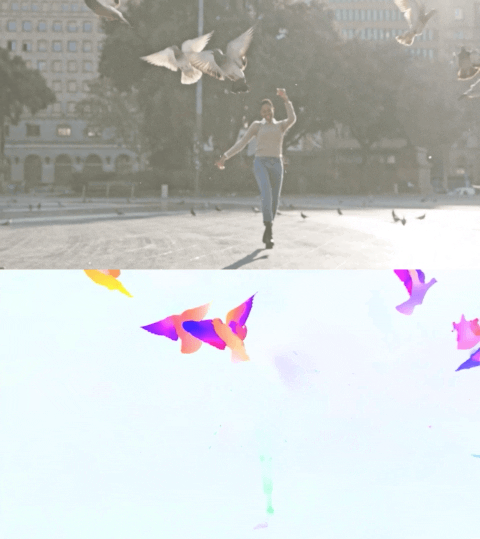

使用Perceiver IO进行光流估计。每个像素的颜色显示了模型估计的运动方向和速度,如右侧图例所示。
用于多模态自编码的Perceiver
作者还使用Perceiver进行多模态自编码。多模态自编码的目标是学习一个能够在架构引入瓶颈的情况下准确重构多模态输入的模型。作者在Kinetics-700数据集上训练了该模型,其中每个示例包含一系列图像(即帧)、音频和一个类别标签(700个可能的标签之一)。该模型也在HuggingFace Transformers中实现,并作为PerceiverForMultimodalAutoencoding可用。为了简洁起见,我将省略定义此模型的代码,但需要注意的是,它使用PerceiverMultimodalPreprocessor来为模型准备输入。该预处理器首先分别使用各个模态性的预处理器(图像、音频、标签)。
假设有一个分辨率为224×224的16帧视频和30720个音频样本,则各模态性的预处理如下:
- 图像-实际上是一系列帧-形状为(batch_size, 16, 3, 224, 224),使用PerceiverImagePreprocessor将其转换为形状为(batch_size, 50176, 243)的张量。这是一种“空间到深度”的转换,之后会将固定的二维傅里叶位置嵌入进行连接。
- 音频的形状为(batch_size, 30720, 1),使用PerceiverAudioPreprocessor将其转换为形状为(batch_size, 1920, 401)的张量(该预处理器将固定的傅里叶位置嵌入与原始音频进行连接)。
- 形状为(batch_size, 700)的类别标签使用PerceiverOneHotPreprocessor转换为形状为(batch_size, 1, 700)的张量。换句话说,该预处理器只是添加了一个虚拟的时间(索引)维度。需要注意的是,在评估过程中,将类别标签初始化为零张量,以使模型充当视频分类器。
接下来,PerceiverMultimodalPreprocessor将使用模态性特定的可训练嵌入来填充预处理后的模态性,以便在时间维度上进行连接。在本例中,通道维度最高的模态性是类别标签(具有700个通道)。作者强制要求最小填充大小为4,因此每个模态性将被填充为具有704个通道。然后它们可以进行连接,因此最终的预处理输入是形状为(batch_size, 50176 + 1920 + 1, 704) = (batch_size, 52097, 704)的张量。
作者使用了784个潜在特征,每个特征的维度为512。因此,潜在特征的形状为(batch_size, 784, 512)。在交叉注意力之后,又得到了与潜在特征形状相同的张量(因为潜在特征充当查询)。接下来,将对潜在特征的嵌入应用8个自注意力层的单个块(每个块具有8个注意力头)来更新嵌入。
接下来,有PerceiverMultimodalDecoder,它将首先为每个模态性单独创建输出查询。然而,由于不可能在单个前向传递中解码整个视频,因此作者选择以块为单位自动编码。每个块将为每个模态性的某些索引维度进行子采样。假设我们以128个块处理视频,那么解码器查询将如下产生:
- 对于图像模态,解码器查询的总大小为16x3x224x224 = 802,816。然而,在自动编码第一个块时,会对前802,816/128 = 6272个值进行子采样。图像输出查询的形状为(batch_size, 6272, 195),其中195来自于使用固定的傅里叶位置嵌入。
- 对于音频模态,输入的总大小为30,720个值。然而,只对前30720/128/16 = 15个值进行子采样。因此,音频查询的形状为(batch_size, 15, 385)。这里,385来自于使用固定的傅里叶位置嵌入。
- 对于类别标签模态,不需要进行子采样。因此,子采样索引设置为1。标签输出查询的形状为(batch_size, 1, 1024)。查询使用可训练的位置嵌入(大小为1024)。
与预处理器类似,PerceiverMultimodalDecoder 将不同的模态填充到相同数量的通道中,以便在时间维度上实现模态特定查询的连接。在这里,类别标签再次具有最高数量的通道(1024),作者强制设置最小填充大小为2,因此每个模态都将填充为具有1026个通道。在连接之后,最终的解码器查询形状为(batch_size, 6272 + 15 + 1, 1026) = (batch_size, 6288, 1026)。该张量在交叉注意力操作中产生查询,而潜变量充当键和值。因此,交叉注意力操作的输出是形状为(batch_size, 6288, 1026)的张量。接下来,PerceiverMultimodalDecoder 使用线性层将输出通道减少,得到形状为(batch_size, 6288, 512)的张量。
最后,还有PerceiverMultimodalPostprocessor。该类将解码器的输出后处理,以产生每个模态的实际重构。它首先根据不同的模态拆分解码器输出的时间维度:(batch_size, 6272, 512)用于图像,(batch_size, 15, 512)用于音频,(batch_size, 1, 512)用于类别标签。接下来,分别应用每个模态的后处理器:
- 图像后处理器(在Transformers中称为
PerceiverProjectionPostprocessor)将(batch_size, 6272, 512)的张量转换为形状为(batch_size, 6272, 3)的张量 – 即将最后一个维度投影到RGB值。 PerceiverAudioPostprocessor将(batch_size, 15, 512)的张量转换为形状为(batch_size, 240)的张量。PerceiverClassificationPostprocessor简单地获取第一个(唯一的索引),得到形状为(batch_size, 700)的张量。
因此,现在得到了包含图像、音频和类别标签模态的重构的张量。由于以块的形式自动编码整个视频,需要将每个块的重构连接起来,以得到整个视频的最终重构。下图展示了一个例子:



上面:原始视频(左),前16帧的重构(右)。视频取自UCF101数据集。下面:重构的音频(取自论文)。

上面的视频的前五个预测标签。通过掩盖类别标签,Perceiver可以成为一个视频分类器。
通过这种方法,模型学习了跨3个模态的联合分布。作者指出,由于潜变量在模态之间是共享的,而不是明确分配给它们,每个模态的重构质量对其损失项的权重和其他训练超参数敏感。通过更强调分类准确性,他们能够在保持20.7 PSNR(峰值信噪比)的同时达到45%的top-1准确率。
Perceiver 的其他应用
值得注意的是,Perceiver 的应用没有限制!在原始的 Perceiver 论文中,作者展示了该架构可以用来处理 3D 点云,这是自动驾驶汽车配备激光雷达传感器的一个常见问题。他们在 ModelNet40 数据集上对模型进行了训练,该数据集是由涵盖 40 个物体类别的 3D 三角网格生成的点云数据。该模型在测试集上达到了 85.7% 的 top-1 准确率,与 PointNet++ 相竞争,PointNet++ 是一种使用额外几何特征并执行更高级增强的高度专业化模型。
作者还使用 Perceiver 替换了 AlphaStar 中的原始 Transformer,AlphaStar 是复杂游戏 StarCraft II 中最先进的强化学习系统。作者观察到,在不调整任何额外参数的情况下,由此产生的代理与原始的 AlphaStar 代理达到了相同的性能水平,在对人类数据进行行为克隆后,在与 Elite 机器人的比赛中达到了 87% 的胜率。
重要的是,当前实现的模型(如PerceiverForImageClassificationLearned ,PerceiverForOpticalFlow)只是使用 Perceiver 的示例。每个示例都是 PerceiverModel 的不同实例,只是具有不同的预处理器和/或解码器(以及可选的后处理器,如多模态自编码的情况)。人们可以提出新的预处理器、解码器和后处理器来解决不同的问题。例如,可以扩展 Perceiver 以执行类似于 BERT 的命名实体识别(NER)或问答,类似于 Wav2Vec2 的音频分类或类似于 DETR 的目标检测。
结论
在本博文中,我们介绍了 Google Deepmind 的 Perceiver IO 架构,并展示了它处理各种模态的普适性。Perceiver 的重大优势在于自注意机制的计算和内存需求不依赖于输入和输出的大小,因为大部分计算发生在一个潜在空间中(一个不太大的向量集合)。尽管其任务无关的架构,该模型能够在语言、视觉、多模态数据和点云等模态上取得出色的结果。在未来,将在同一时间训练一个单一(共享的)Perceiver 编码器,用于多种模态,并使用模态特定的预处理器和后处理器,这可能是有趣的。正如 Karpathy 所说,这种架构可能会将所有模态统一到一个共享空间中,并提供一组编码器/解码器的库。
说到库,该模型已经作为 HuggingFace Transformers 的一部分提供。随着人们对其进行各种构建,它的应用似乎是无限的!
附录
HuggingFace Transformers 中的实现基于原始的 JAX/Haiku 实现,可以在此处找到。
HuggingFace Transformers 中的 Perceiver IO 模型的文档可以在此处找到。
关于 Perceiver 的几种模态的教程笔记本可以在此处找到。
脚注
1 值得注意的是,在官方论文中,作者使用了一个两层 MLP 来生成输出的逻辑回归结果,在这里为了简洁起见省略了。 ↩︎