广阔的视野:NVIDIA主题演讲指引进一步的人工智能进展
NVIDIA主题演讲指引人工智能进展
硬件性能的显著提升催生了生成式人工智能,并为未来加速机器学习的丰富想法提供了支持,NVIDIA首席科学家兼研究高级副总裁比尔·达利(Bill Dally)在今天的主题演讲中表示。
达利在Hot Chips会议上的演讲中描述了一系列正在进行中的技术 – 其中一些已经显示出令人印象深刻的结果。
“人工智能的进步是巨大的,它得益于硬件的支持,但仍然受到深度学习硬件的限制,”达利表示。他是世界上最杰出的计算机科学家之一,曾担任斯坦福大学计算机科学系主任。
他举例说明了如何通过过去十年中GPU在人工智能推理性能方面的进步,使得ChatGPT(一种广泛使用的大型语言模型)能够为他的演讲提供大纲。他说,这些能力在很大程度上归功于GPU在AI推理性能方面的增益。
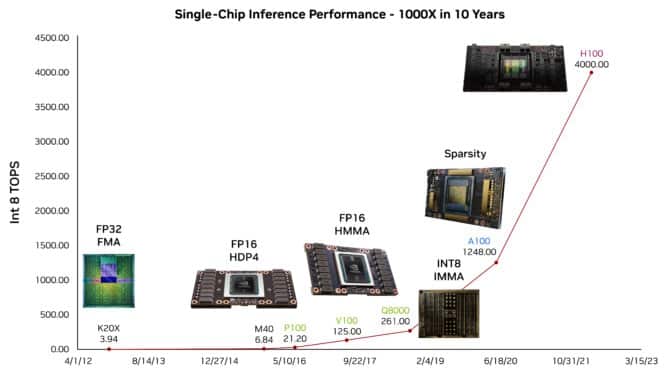
研究实现了每瓦100 TOPS
研究人员正在准备下一波进展。达利描述了一款测试芯片,该芯片在LLM上实现了近100太操作每瓦。
该实验展示了一种节能的方法,以进一步加速生成式人工智能中使用的Transformer模型。它应用了四位数算术,这是几种简化的数值方法之一,有望带来未来的增益。

在展望未来时,达利讨论了使用对数数学加速计算和节省能源的方法,这是NVIDIA在2021年的一项专利中详细介绍的方法。
为人工智能定制硬件
他探讨了一些针对特定AI任务定制硬件的技术,通常是通过定义新的数据类型或操作。
达利描述了简化神经网络的方法,通过剪枝突触和神经元,采用了称为结构稀疏性的方法,该方法首次在NVIDIA A100 Tensor Core GPU中采用。
“我们在稀疏性方面还没有完成。”他说。“我们需要对激活进行处理,并且在权重方面也可以有更大的稀疏性。”
研究人员需要同时设计硬件和软件,仔细决定在哪里花费宝贵的能源,他说。例如,内存和通信电路需要最小化数据移动。
“对于计算机工程师来说,这是一个有趣的时代,因为我们正在推动人工智能的巨大革命,而我们甚至还没有完全意识到这场革命的规模有多大,”达利说。
更灵活的网络
在另一个演讲中,NVIDIA的网络副总裁凯文·迪尔林(Kevin Deierling)描述了NVIDIA BlueField DPU和NVIDIA Spectrum网络交换机的独特灵活性,可以根据网络流量或用户规则的变化分配资源。
芯片能够在几秒钟内动态转移硬件加速管道,实现最大吞吐量的负载平衡,并为核心网络提供了新的适应性水平。这对于抵御网络安全威胁尤为有用。
“在生成式人工智能工作负载和网络安全方面,今天一切都是动态的,事物不断变化,”迪尔林说。“因此,我们正朝着运行时可编程和可以动态更改的资源转变。”
此外,NVIDIA和莱斯大学的研究人员正在开发利用流行的P4编程语言来利用运行时灵活性的方法。
Grace引领服务器CPU
Arm关于其Neoverse V2核心的演讲中,包括了实施NVIDIA Grace CPU Superchip的首个处理器的性能更新。
测试显示,在相同功率下,Grace系统在各种CPU工作负载下的吞吐量比当前x86服务器高出最多2倍。此外,Arm的SystemReady计划认证了Grace系统将能够运行现有的Arm操作系统、容器和应用程序而无需修改。
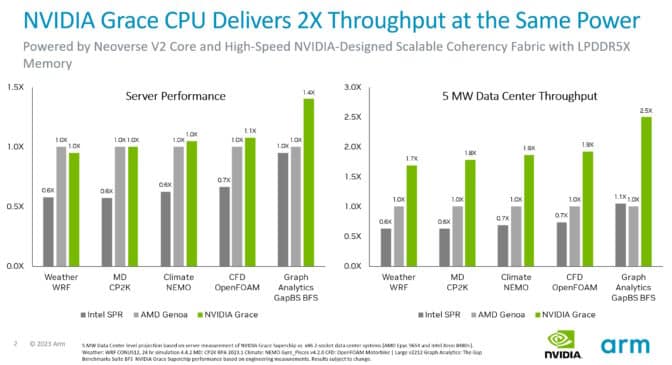
Grace使用超快速的互联结构将72个Arm Neoverse V2核心连接在单个芯片上,然后使用NVLink连接两个芯片,提供900 GB/s的带宽。它是第一个使用服务器级LPDDR5X内存的数据中心CPU,提供了50%更高的内存带宽,成本相似,但功耗是典型服务器内存的八分之一。
Hot Chips于8月27日开始,全天进行了一系列的教程,包括NVIDIA专家就AI推理和芯片间互联协议的讲座,并一直持续到今天。




