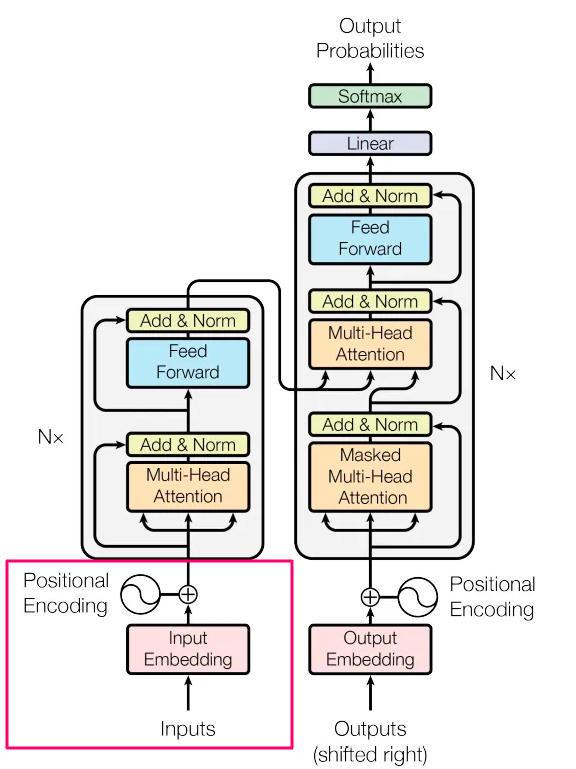
Metas新的文本到图像模型——CM3leon论文解释
Metas新模型CM3leon解释
全新的最先进和高效的文本到图像(到文本!)模型。
![来源:构图:作者,图片:[1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*8uAXSsuPcTE8-K1TBS_ZLw.png)
Meta最近发布了其全新的最先进文本到图像模型,名为CM3Leon [1],该模型不是基于扩散(如Stable-Diffusion [2],Midjourney或DALLE [3])。
它是一个检索增强的、自回归的、仅解码器模型!
听起来很高大上,但在这篇文章中,我们将了解这一切的含义。到目前为止,我们已经知道当前的图像生成模型可以生成令人惊叹的图像,但仍然存在一定的局限性。例如,这些模型的效率和成本。或者生成手部!但是CM3Leon不同,作者们似乎对此非常自豪!
生成本身很酷,但是这种自回归、仅解码器的方法还可以实现图像到文本的能力!
结果
但是,首先,让我们更仔细地看一下结果,以及CM3Leon为何如此特殊!
![FID分数的对数尺度图表,显示各种模型与等效A100 GPU小时的对应关系。来源:[1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*pZ8E5XsgQzKl2Qrt-gpevA.png)
我们已经看过生成的漂亮图像,但当我们看一下上图中的数字时,我们真的可以看到CM3leon比其他模型(如DALLE和Parti)好多少。现在,人们可能会对FID分数真正捕捉到生成图像的逼真程度有多好进行争论,但无论如何,CM3Leon在MS COCO数据集上创造了新的最先进的FID分数。不过,我必须说,选择DALLE模型的自回归版本对比可能有点不公平。
DALLE是如何工作的?
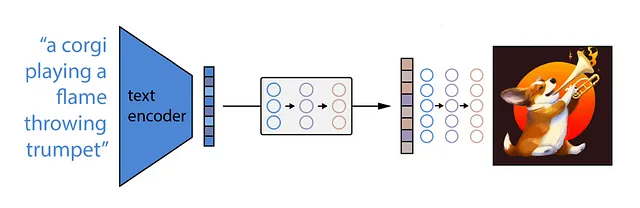
稍微离题一下,DALLE有一个中间模型,称为先验模型,它将CLIP生成的文本嵌入映射为相应的图像编码,然后使用扩散过程生成最终的图像。这个先验模型可以是扩散过程或自回归过程。两者似乎都能产生类似的结果,但扩散过程更高效,因此DALLE的作者选择了这个。所以,对于这里的比较来说,选择效率较低的版本对DALLE可能有点不公平。
回到图像生成结果
![各种零样本MS-COCO任务上各种文本到图像模型的FID摘要。对于我们的所有模型,我们为每个输入查询生成8个样本,并使用CLIP模型选择最佳生成。来源:[1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*coRfNm3CN8DmmXrylC_-5w.png)
好的,单独的FID分数很棒,但更好的是,CM3Leon在保持性能的同时更加高效!在其最大的70亿参数模型中,它比最大的Parti模型要小得多,并且使用了更少的训练数据和时间!此外,作者还引入了一种“负责任”训练的新指标。用于训练CM3Leon的图像全部来自Shutterstock许可,所以(希望)不再担心诉讼!然后还有“检索到的文档数量”这一栏,这是CM3Leon模型的主要特点之一,使其变得如此出色,我们将在下面详细了解更多。简单来说,给定一个文本提示,该模型可以以某种方式从内存库中检索相关图像甚至文本,并将其用作图像生成过程的进一步上下文。
什么是零-shot生成?
现在,让我感到疑惑的是,如果模型在生成过程中获取了更多的图像,那么它真的算是零-shot生成吗?我猜想模型本身获取了额外的图像,而这些图像并不是由提示模型的人提供的,但是在这里并不百分之百确定。
在摘要中,作者提到他们的最佳模型实现了“零-shot MS-COCO FID [分数]为4.88”的成绩
CM3Leon在文本到图像生成方面取得了与可比方法相比使用5倍较少的训练计算的最先进性能(零-shot MS-COCO FID为4.88)。—来源:[1]
但是这个分数是在使用两个检索图像的情况下实现的,也就是说他们将检索称为零-shot。但是在他们的图1的标题中,他们说了以下的话:
CM3Leon零-shot生成的展示(无检索增强)。—来源:[1]
那么,什么是零-shot生成?有检索还是没有?
多模态基准
好的,到目前为止,一切都是关于图像生成的,但由于这个模型是一个自回归、仅解码器模型,就像所有大型LLMs一样,它也可以将图像解释为普通的标记,并将它们用作文本生成的上下文!换句话说,在应用监督微调(或简称为SFT)之后,我们的模型还可以执行更复杂的多模态任务。
![使用广泛的组合图像和文本任务对CM3Leon模型进行微调后的定量示例。来源:[1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*tDZ23diYuDA0n2CmNpMjRg.png)
它在交错的文本和图像任务上表现非常出色,例如“文本引导编辑”和“图像到图像的基于语义的生成”,您可以提供分割图、仅包含轮廓的草图,甚至是深度图,并基于这些和一个文本提示生成新的图像。或者,通过“基于空间的图像生成”,您甚至可以提供文本提示中对象的坐标,并且生成的图像将在这些坐标处放置该对象。除此之外,该模型在实际生成图像中生成文本也非常出色,这在一段时间内并不常见。我是指不到一两年前:))最后,通过正确的监督微调,CM3Leon还可以将图像作为输入并执行诸如图像字幕生成、视觉问答和推理等任务。它仍然不如专门的图像字幕生成模型(如Flamingo [4])好,但由于这几乎只是模型设计的副产品,结果仍然非常令人印象深刻!
CM3Leon是如何工作的?
好的,很棒,但是CM3Leon是如何工作的,而“retrieval-augmented, auto-regressive, decoder-only model”是什么意思!?
这时候,我们都或多或少都知道扩散是如何工作的。一个模型被训练来预测图像中的噪声,以便当我们从完全随机的噪声开始时,我们可以应用这个模型并逐步去除噪声。现在,这个去噪过程也可以依赖于文本,这样我们就可以通过我们的提示来引导生成过程。
自回归模型的工作方式有些不同。让我们看看Parti是如何实现自回归图像生成模型的思想的。
什么是自回归?
还记得自动编码器是如何工作的吗?我们有一个编码器网络,它将图像映射到某个嵌入中,以便解码器可以根据潜在向量表示仅生成相同的图像。在下面的图像中,这个思想由绿色模块进行了说明。
![Parti提出的图像生成的自回归、编码器-解码器架构(Yu等,2022年)。来源:[5]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*aw7AU-ZmRPk7WD9q0ta77g.png)
现在,如果解码器(在Parti中称为解标记器)用于生成图像的嵌入是由语言模型预测的令牌形式呢?想象一下,GPT模型是如何从一个简单的序列起始令牌开始,预测给定词汇表中的下一个令牌或者说令牌嵌入,以知识自回归的方式。视觉变换器还为图像的每个补丁令牌生成嵌入,这些嵌入也可以限制为来自某个特定的词汇表。这意味着我们的自回归文本解码器(蓝色模块)也可以生成每个图像嵌入令牌,然后让图像生成器(或者在这里再次称为解标记器)生成图像。现在,为了使图像令牌生成过程具有条件性,Parti决定采用编码器-解码器方法。它使用完整的Transformer架构,原本是为了翻译文本而设计的。在这种情况下,简单地将文本的语言转化为图像的语言,或者说文本令牌转化为图像令牌。换句话说,他们使用交叉注意力,其中文本编码器(黄色模块)嵌入被用作对预测一个接一个的图像令牌的文本解码器的条件。
这种自回归方法解决了扩散模型存在的一些问题。例如,自回归模型可以更好地处理长文本提示,并且可以很好地在图像中生成文本!但它只能通过规模来实现。在这里,”简单地扩大规模就能解决问题”的情况非常极端。我们可以看一下这个例子,其中包括袋鼠和文本“欢迎朋友!”。
![使用相同的提示但不同的模型尺寸生成的图像。来源:[5]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*m5Q-OZR5FEwBeVusMgHG6w.png)
什么是仅解码器(decoder-only)?
好的,我们现在知道自回归图像生成的工作原理,但CM3Leon是一个仅解码器的自回归模型,而不是像Parti那样的编码器-解码器模型。这基本上意味着,生成过程中的文本条件化不是通过编码器和交叉注意力来实现的,而是通过解码器上下文中的简单文本令牌来实现的。这意味着词汇表现在必须包括图像令牌词汇表(作者使用已存在的标记器)和文本令牌词汇表(作者自己训练一个新的标记器)。此外,作者还引入了一个新的<break>令牌,表示模态转换。
![多模态文档的示意图。一个包含文本和图像令牌的单个序列。来源:[1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*XVKMg9_xFHHF60rAYH5TFw.png)
现在,我们的解码器输入和输出可以看起来像这样,我们从提示“A Photo of a cat shown on a dslr”开始,后面是<break>令牌,然后解码器逐个预测下一个图像令牌。一旦我们到达另一个<break>或<EOS>令牌,图像解码器就可以接管并生成图像!
当涉及训练数据时,模型可以处理多模态案例,例如“Image of a chameleon:”后面是图像令牌,其中模型只是简单地在标准的下一个令牌预测损失上进行训练。
“Image of a chameleon:” → “<Img233>”, “<Img44>”, …
但这也意味着该模型可以通过简单地重新格式化相同的示例来处理图像字幕任务,以屏蔽样本的某个部分,并期望模型在<infill>请求之后预测被屏蔽的部分。
“Image of a <mask>: <Img233>, … <infill> →”chameleon”
换句话说,模型看到图像并且必须预测该图像包含的内容。
我们的模型现在可以生成文本和图像。
自回归,对。仅解码器,对。最后,这个“检索增强”是如何工作的呢?
什么是检索增强?
我已经提到了,这基本上意味着,在给定初始提示的情况下,模型可以检索图像或文本,或者两者都可以,并将其添加到其上下文中。由于我们现在知道了解码器模型的输入如何工作,我们可以很容易地理解如何简单地将更多图像和文本添加到上下文中。
![完整数据样本的插图,其中包含多个交错的图像和文本元素。来源:[1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*sSkA2eGMMaXxDYg3whPPYw.png)
我们只需在最大上下文长度允许的范围内添加尽可能多的文本和图像,可以通过<break>标记来分隔。而且,通过设置序列长度为4096,我们应该可以添加一个或两个检索到的文档。此处的文档指的是可以是单个图像或文本,或者是图像和标题对。
CM3Leon在RA-CM3论文[6]的基础上进行了很多构建,该论文提出了将检索增强功能添加到CM3论文[7]中提出的方法中。这才是真正的研究,一篇论文建立在另一篇论文的基础上!
在RA-CM3论文中,我们可以非常清楚地看到为给定文本提示检索图像的效果。
![从存储库中检索一张图像对图像生成过程的影响。来源:[6]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*lihnjpu0CpKIt-SmcyL7aw.png)
例如,我们可以看到针对提示“法国国旗在月球表面上飘扬”的一些输出,普通的CM3模型在没有检索和稳定扩散的情况下只会在月球上放置美国国旗,但是如果我们现在将一张法国国旗的检索图像添加到上下文中,RA-CM3将生成一个正确的结果。当检索两个图像时也会产生类似的效果,以此类推。
![手动指定图像对图像生成/修复过程的影响。来源:[6]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*6-pKivvIa4X2rBSFxJoVxA.png)
当然,这也允许您手动指定图像以控制生成图像的风格,正如我们在这个例子中所看到的那样。提供一张穿着红夹克的人的图像也将导致模型修复一张穿着红夹克的人的图像。
那么,这个检索是如何工作的呢?其实这个想法非常简单。作者使用一个现成的、冻结的CLIP模型对输入查询进行编码,例如一个简单的文本提示,并根据相关性得分对相似的候选项进行排序。存储库中的各个文本和图像示例只需通过CLIP模型一次,但对于图像和标题文档,作者将文本和图像分开编码,然后将两者平均为整个文档的向量表示。
作者不仅仅选择最相似的文档,而是使用不同的启发式方法使检索更具信息性。例如,由图像和文本组成的文档比仅有文本或仅有图像的文档更具信息性。或者,如果候选文档与查询太相似,或者已经检索到几乎相同的文档,他们会跳过候选文档。还有一些其他技巧。
还有其他一些细节(但很重要!),可以使模型的输出效果更好,但这些不是根本上的新想法,只是通常会提高性能的附加技巧。例如,随机采样不同的温度值,或者使用一种称为TopP采样的方法,在推理过程中应用无分类器的指导,或者他们自己对对比解码进行了适应。
因此,最终,我们现在知道了检索增强的自回归解码器CM3Leon模型的工作原理以及它能做什么。这种检索思想是该模型如此参数和数据高效的一个关键因素!
![从内存库中检索两个图像对图像生成过程的影响。来源:[6]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*yHR0SJSwE13YVHt-obxTtg.png)
模型不必记住整个世界的信息,比如樱花树或拉什莫尔山是什么样子以及它们的样子。而且,使用仅解码器架构使得训练和对新任务的微调变得更加容易!
在可能认为扩散模型是图像生成的最佳方法之后,这篇论文再次展示了著名的Transformer模型等自回归模型在广泛的文本和图像任务中的强大能力。
如果您喜欢阅读本文,请不要忘记点赞并关注我,以获取更多令人兴奋的AI论文解读帖子!
P.S.:如果您喜欢这个内容和视觉效果,您也可以查看我的YouTube频道,那里有类似的内容,但有更多整洁的动画!
参考文献
[1] Scaling Autoregressive Multi-Modal Models: Pretraining and Instruction Tuning,L. Yu, B Shi, R Pasunuru等,2023,论文链接
[2] High-Resolution Image Synthesis with Latent Diffusion Models,R. Rombach, A. Blattmann, D. Lorenz, P. Esser, B.等,2021,https://arxiv.org/abs/2112.10752
[3] Zero-Shot Text-to-Image Generation,Ramesh等,2021,https://arxiv.org/abs/2102.12092
[4] Flamingo: a Visual Language Model for Few-Shot Learning,B. Alayrac, J. Donahue, P. Luc, A. Miech等,2022,https://arxiv.org/abs/2204.14198
[5] Scaling Autoregressive Models for Content-Rich Text-to-Image Generation,Yu等,2022,https://arxiv.org/abs/2206.10789
[6] Retrieval-Augmented Multimodal Language Modeling,Yasunaga等,2022,https://arxiv.org/abs/2211.12561
[7] CM3: A Causal Masked Multimodal Model of the Internet,A. Aghajanyan等,2022,https://arxiv.org/abs/2201.07520