使用LLMs提升电子商务产品搜索
LLMs提升电商搜索
应用LLM使电子商务搜索引擎对口语查询具有鲁棒性
近年来,网络搜索引擎迅速采用大型语言模型(LLMs)来提高其搜索能力。其中最成功的例子之一是由BERT [1]驱动的Google搜索。相比之下,许多电子商务平台在其产品搜索中相对保守地应用了这种新兴技术。本文将演示如何应用LLMs来增强电子商务产品搜索的理解能力,以应对口语化和隐含性的搜索查询。
问题陈述
尽管像亚马逊[2]这样的先驱者已经出现,但许多电子商务平台仍然严重依赖传统的检索技术,如TFIDF和BM25进行产品搜索。这些稀疏的方法通常要求客户输入与产品信息匹配的明确查询,并且在处理口语化和隐含性查询时往往难以实现良好的相关性。结果,搜索引擎要么返回无结果,要么返回相关性较低的结果,忽略了相关结果的存在,从而损害了客户体验和业务指标。
例如,eBay对查询“男孩5岁以下的最佳礼物是什么?”返回“未找到完全匹配项”。虽然“匹配较少单词的结果”解决方案避免了“无结果”的情况,但其搜索相关性明显有改进的潜力。
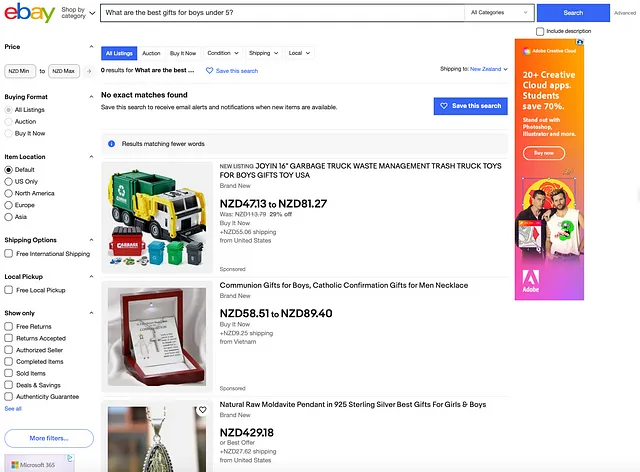
有人可能会认为这种查询很少发生。然而,很多机会和进步实际上是由一开始被低估的用例推动的,这并不罕见。
基于LLM的解决方案
如今,由于LLM的快速发展,人们可以快速构建原型,而不必担心从头开始构建内部解决方案所需的工作量。这使得我能够快速发现解决问题的方法。
如下图所示,这个想法非常直观。利用LLM将原始查询转化为增强查询,旨在包含用于搜索的明确产品信息。可能,增强查询所涵盖的产品范围对于隐含且模糊的原始查询而言可能很广泛。结果,直接将增强查询发送到基于关键词的搜索引擎可能会导致结果不佳,因为其模糊性和不确定性。作为解决方案,采用LLM嵌入来解决语义复杂性。具体而言,将增强查询投影到包含预处理产品嵌入的嵌入空间中。接下来,通过比较查询嵌入和产品嵌入之间的相似性来进行产品检索,然后生成前k个产品作为搜索结果。
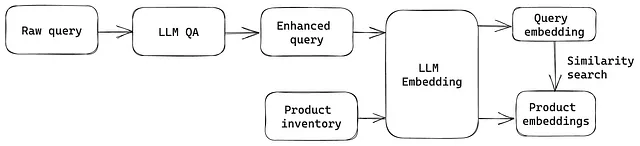
有很多技术可以实现这个想法,因为每个步骤都有许多选项。在这里,我提供了一个基于Hugging Face和LangChain的示例实现。实际代码托管在下面的Github存储库中,并在下面的详细说明中进行了解释。
ML_experiments/LLM_search_exp.ipynb at main · simon19891101/ML_experiments
通过在GitHub上创建一个帐户,为simon19891101/ML_experiments做贡献。
github.com
生成增强查询
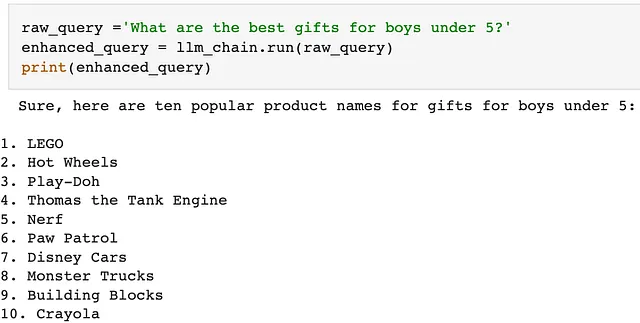
首先,采用最近宣布的Llama 2作为LLM,为给定的原始查询生成增强查询。如下所示,使用Hugging Face pipeline,考虑到其简单性。值得注意的是,pipeline本身足以完成任务,因此使用LangChain是完全可选的。这里采用的提示模板旨在生成相关和多样化的产品名称,以解决原始查询的模糊性。
from transformers import AutoTokenizerimport transformersimport torchmodel = "meta-llama/Llama-2-7b-chat-hf"tokenizer = AutoTokenizer.from_pretrained(model, use_auth_token=True)pipeline = transformers.pipeline( "text-generation", model=model, torch_dtype=torch.float16, device_map="auto", do_sample=False, top_k=1, num_return_sequences=1, eos_token_id=tokenizer.eos_token_id, max_length=200)from langchain.llms import HuggingFacePipelinefrom langchain import PromptTemplate, LLMChaintemplate='''[INST] <>只告诉我产品名称。答案应该只包括十个名称。<>{prompt}[/INST]'''prompt_template = PromptTemplate(template=template, input_variables=["prompt"])llm = HuggingFacePipeline(pipeline=pipeline)llm_chain = LLMChain(prompt=prompt_template, llm=llm)创建产品嵌入
接下来,使用LangChain中的句子转换器和FAISS来基于库存中的产品标题创建和存储产品嵌入。在这里,由于无法访问实际的搜索引擎,将离线Ebay产品数据集“products.csv”采用为电子商务产品库存的模拟。该数据集包含大约3000个涵盖各种类别的产品。
Ebay UK产品数据集-由opensnippets提供的数据集
Ebay UK电子商务产品免费数据集
data.world
import pandas as pdproducts = pd.read_csv('products.csv', usecols=['name'])from langchain.vectorstores import FAISSfrom langchain.embeddings import HuggingFaceEmbeddingsembeddings = HuggingFaceEmbeddings(model_name='sentence-transformers/all-MiniLM-L6-v2', model_kwargs={'device': 'cpu'})product_names = products['name'].values.astype(str)product_embeddings = FAISS.from_texts(product_names, embeddings)产品检索
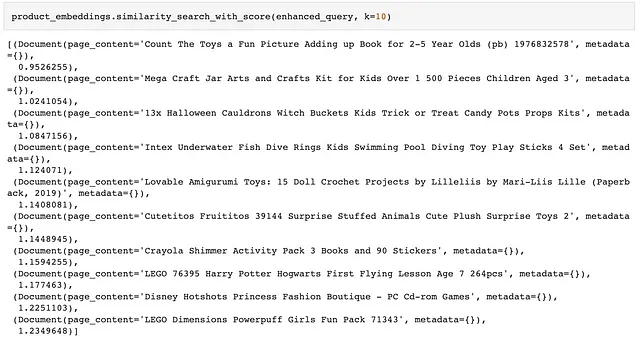
当涉及检索时,再次使用编码产品的相同句子转换器模型为增强查询生成查询嵌入。最后,基于查询嵌入和产品嵌入之间的相似度检索前10个产品。
raw_query = 'example query'enhanced_query = llm_chain.run(raw_query)product_embeddings.similarity_search_with_score(enhanced_query, k=10)展示
为了展示这种方法的有效性,让我们看一下上述查询“What are the best gifts for boys under 5?”并将LLM增强与图1中呈现的原始Ebay搜索结果进行比较。
首先,收到原始查询后,Llama 2按照提示模板的指示生成了10个产品。对于男孩的礼物想法,它们看起来非常出色,尽管期望有更好的产品级细化。
接下来,让我们看一下嵌入空间中的相似匹配。与真实世界的Ebay搜索引擎结果相比,从产品库存模拟中检索到的结果并不差。由于库存模拟的产品范围有限,比较有些不公平,但我们仍然能够观察到应用LLM之前和之后的显著差异。总体而言,嵌入空间的检索实现了相关性和多样性。
最后的想法
在进行初步的探索后,显然LLMs是增强电子商务平台产品搜索的强大工具。对于这个任务,有许多未来的探索可以进行,包括用于生成查询的提示工程、具有丰富属性的产品嵌入、LLM查询增强的在线延迟优化等。希望这篇博客能够激发那些需要改进产品搜索的电子商务平台。
参考资料
[1] Nayak, P. (2019) Understanding searches better than ever before, Google. 可在:https://blog.google/products/search/search-language-understanding-bert/ (访问日期:2023年8月9日)。[2] Muhamed, A. et al. (无日期) Web-scale semantic product search with large language models, Amazon Science. 可在:https://www.amazon.science/publications/web-scale-semantic-product-search-with-large-language-models (访问日期:2023年8月9日)。






