面向对象数据科学:重构代码
Object-oriented Data Science Code Refactoring
通过高效的代码和Python类提升机器学习模型和数据科学产品。
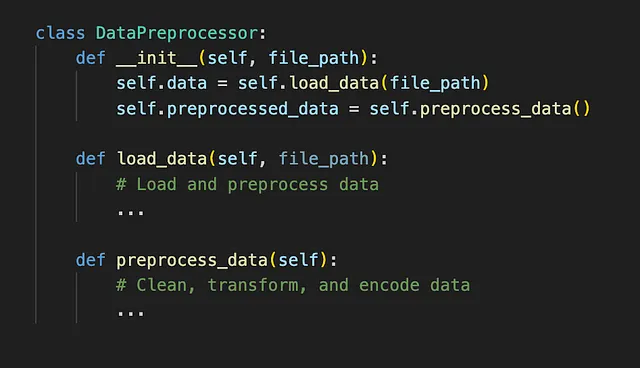
对于数据科学家来说,代码是分析和决策的支撑。随着数据科学应用变得更加复杂,从嵌入软件的机器学习模型到编排大量信息的复杂数据流程管道,开发清晰、有组织、可维护的代码变得至关重要。面向对象编程(OOP)提供了灵活性和效率,使数据科学家能够灵活应对不断变化的需求。OOP引入了类的概念,类作为创建封装数据和操作数据的操作的对象的蓝图。这种范式转变使得数据科学家能够超越传统的功能性方法,促进模块化设计和代码可重用性。
在本文中,我们将探讨通过创建类和应用面向对象技术来重构数据科学代码的好处,以及这种方法如何增强模块化和可重用性。
类在数据科学中的威力
在传统的数据科学工作流程中,函数一直是封装逻辑的方法。这通常足够,因为函数允许开发人员最小化重复的代码。然而,随着项目的发展,维护大量函数的集合可能导致难以导航、调试和扩展的代码。
这就是类的作用。类是创建对象的蓝图,它将数据和操作数据的函数(称为方法)捆绑在一起。通过将代码组织成类,开发人员可以获得几个优势:
- “在随机行走任务上,Temporal-Difference(0)和Constant-α Monte Carlo方法的比较”
- 从零开始使用OceanBase创建一个Langchain的替代方案
- “NVIDIA的盈利报告揭示了其在人工智能革命中的主导地位”
- 模块化和封装:类通过将相关功能组合在一起来促进模块化。每个类封装了自己的属性(数据)和方法(函数),减少了全局变量污染的风险和命名冲突的可能性。这有助于保持关注点的清晰分离,使代码更易于理解和修改。
- 可重用性:类通过为不同部分的相似任务提供一致的接口来鼓励可重用性…