构建你的第一个自动纠错系统,无需机器学习
Build your first automatic error correction system without machine learning.
构建自己的拼写检查器的逐步指南。
拼写纠正无处不在。当我写这篇文章时,Grammarly悄悄地帮我纠正拼写错误。当你在电子商务网站上输入一个查询时,它会先进入正确的阶段,以更好地匹配所需物品的标题。
毫无疑问,拼写纠正对于任何书面交流都是必不可少的。它增强了我们的交流,保持了我们的专业性,并提高了我们的生产力。在考虑构建一个拼写纠正器时,我们可能很快就会想到一种“一刀切”的解决方案:深度学习。然而,深度学习只是有时候的最佳选择。
在本文中,我想介绍“噪声信道”,这是一种经典的拼写纠正技术,以及如何在没有深度学习背景的情况下构建你的纠正模块。
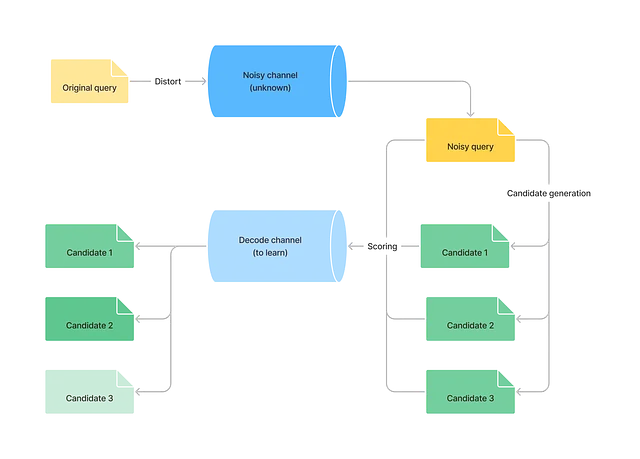
噪声信道
我们可以认为我们文档中的每个单词都经过了一个略微“扭曲”它们的噪声信道。我们的目标是学习“解码信道”,它可以还原那个“扭曲”过程。
为了纠正一个拼写错误的单词,我们收集所有可能的纠正候选词,并让它们通过解码信道,以找到可能性最高的候选词。
与机器学习方法相比,我认为噪声信道更适合初学者,原因如下:
- 成本效益:无需构建和维护深度模型。我们都知道只有一些人有资源来构建、服务和维护深度学习模型。
- 白盒子:噪声信道更容易解释。当拼写检查器出现意外行为时,我们可以将分数细分为较小的组件,并确定问题所在。因此,我们可以相应地进行优化(例如扩展字典、调整超参数等)。
然而,随着应用资源的增长,深度模型(如seq2seq)成为更好的选择,因为:
- 噪声信道缺乏…





