宣布 Amazon S3 支持 Amazon SageMaker Data Wrangler 的访问点功能
Amazon S3支持Amazon SageMaker Data Wrangler的访问点功能
我们很高兴宣布Amazon SageMaker数据整理器支持Amazon S3访问点。SageMaker数据整理器具有可视化的点选界面,简化了数据准备和特征工程的流程,包括数据选择、清洗、探索和可视化,而S3访问点通过提供具有特定访问策略的唯一主机名简化了数据访问。
从今天开始,SageMaker数据整理器使用户更容易从存储在Amazon Simple Storage Service(Amazon S3)中的共享数据集中准备数据,同时使组织能够安全地控制其组织中的数据访问。通过S3访问点,数据管理员现在可以创建应用程序和团队特定的访问点来促进数据共享,而不是管理具有许多不同权限规则的复杂存储桶策略。
在本文中,我们将向您介绍如何在SageMaker数据整理器中从S3访问点导入数据和导出数据。
解决方案概述
假设您作为管理员需要管理多个数据科学团队在SageMaker数据整理器中运行其自己的数据准备工作流。管理员通常面临三个挑战:
- 数据科学团队需要访问其数据集,同时不损害其他人的安全性
- 数据科学团队需要访问一些包含敏感数据的数据集,这进一步增加了权限管理的复杂性
- 安全策略只允许通过特定端点访问数据,以防止未经授权的访问并减少数据的暴露
传统的存储桶策略无法支持在端点级别上设置细粒度访问权限,因为存储桶策略将相同的权限应用于存储桶中的所有对象。传统的存储桶策略也无法支持在端点级别上保护访问。
S3访问点通过在粒度级别上授予细粒度的访问控制来解决这些问题,使得更容易为不同团队管理权限,而不影响存储桶的其他部分。您可以创建多个访问点,并为特定的用例制定个别策略,而不是修改单个存储桶策略,从而降低了配置错误或意外访问敏感数据的风险。最后,您可以在访问点上强制使用端点策略,以定义控制哪些VPC或IP地址可以通过特定访问点访问数据的规则。
我们演示如何在SageMaker数据整理器中使用S3访问点的以下步骤:
- 将数据上传到S3存储桶。
- 创建S3访问点。
- 使用必要的策略配置您的AWS身份和访问管理(IAM)角色。
- 创建SageMaker数据整理器流程。
- 将数据从SageMaker数据整理器导出到访问点。
在本文中,我们使用银行营销数据集作为样本数据。但您也可以使用其他任何数据集。
先决条件
在进行本教程之前,您应具备以下先决条件:
- 一个AWS账户。
- 一个Amazon SageMaker Studio域和用户。有关设置的详细信息,请参阅使用快速设置进行Amazon SageMaker域上的登记。
- 一个S3存储桶。
将数据上传到S3存储桶
将数据上传到S3存储桶。有关说明,请参阅上传对象。在本文中,我们使用银行营销数据集。
创建S3访问点
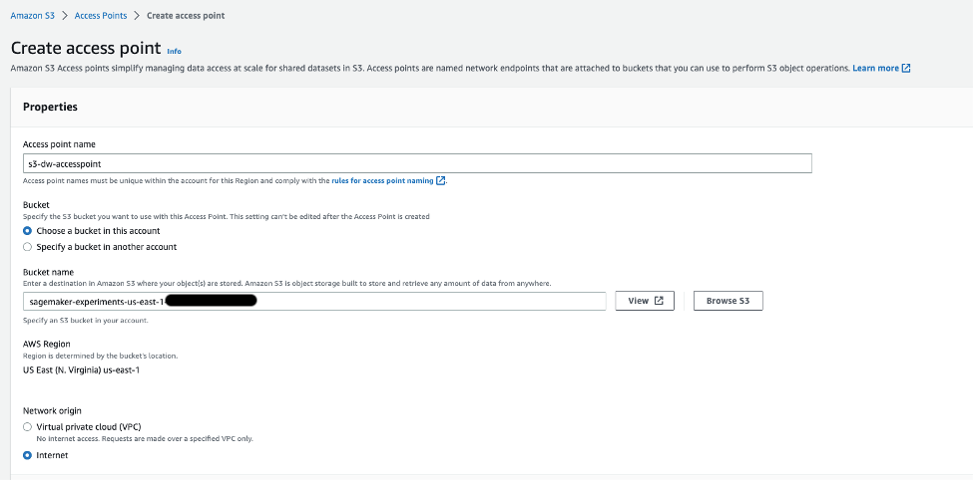
要创建S3访问点,请完成以下步骤。有关更多信息,请参阅创建访问点。
- 在Amazon S3控制台中,选择导航窗格中的访问点。
- 选择创建访问点。
- 对于访问点名称,输入访问点的名称。
- 对于存储桶,选择选择此帐户中的存储桶。
- 对于存储桶名称,输入您创建的存储桶的名称。
- 保留其余设置为默认值,选择创建访问点。
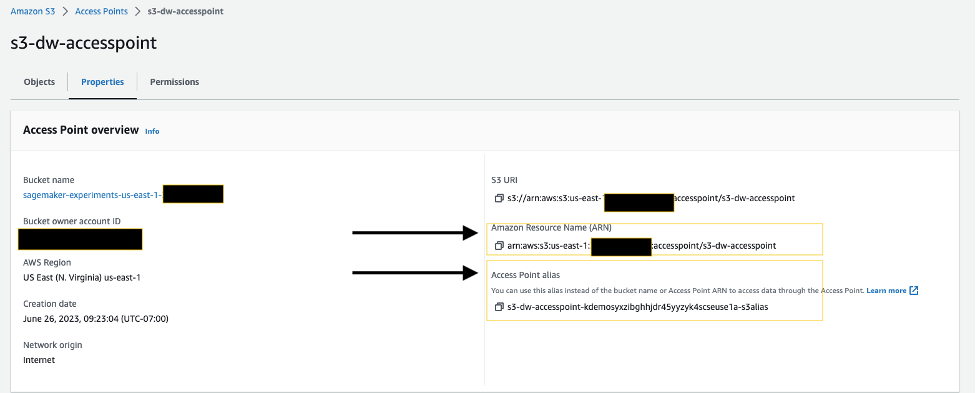
在访问点详细信息页面上,请注意Amazon资源名称(ARN)和访问点别名。在与SageMaker Data Wrangler交互时,您稍后将使用它们。
配置您的IAM角色
如果您已经准备好了一个SageMaker Studio域,请完成以下步骤来编辑执行角色:
- 在SageMaker控制台中,选择导航窗格中的Domains。
- 选择您的域。
- 在Domain settings选项卡上,选择Edit。
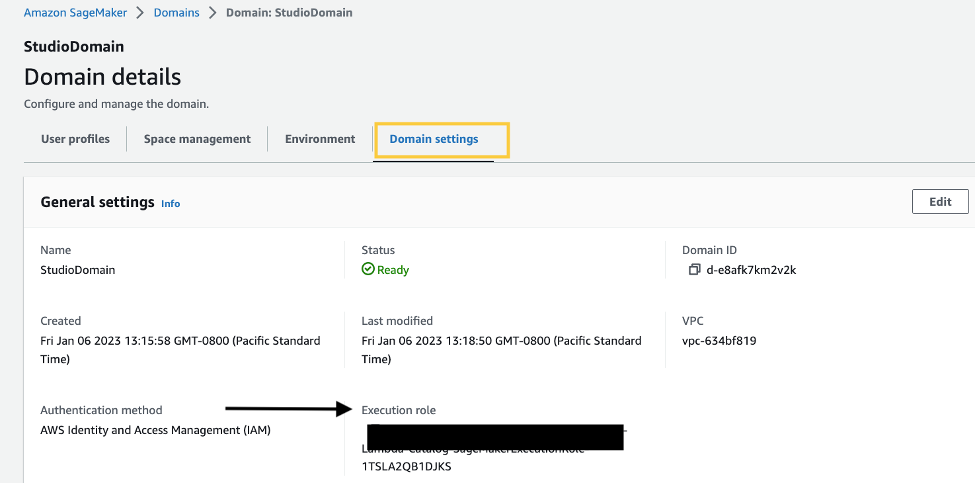
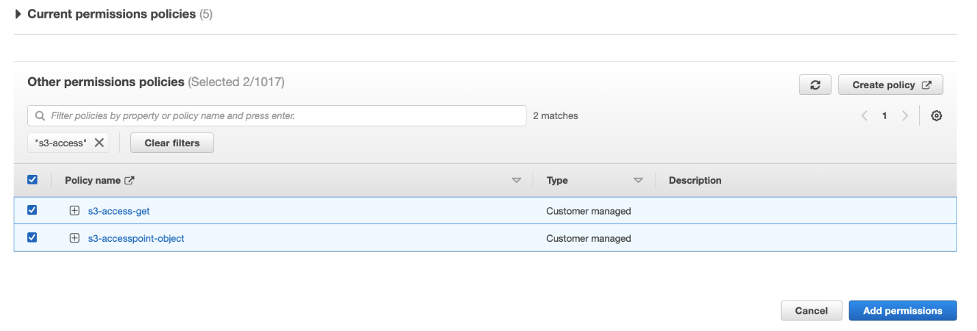
默认情况下,您用于访问Data Wrangler的IAM角色是SageMakerExecutionRole。我们需要添加以下两个策略以使用S3访问点:
-
策略1 – 此IAM策略授予SageMaker Data Wrangler执行
PutObject,GetObject和DeleteObject的权限:{ "Version": "2012-10-17", "Statement": [ { "Sid": "S3AccessPointAccess", "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject", "s3:DeleteObject" ], "Resource": "arn:aws:s3:us-east-1:<<accountID>>:accesspoint/<<s3-dw-accesspoint>>" } ] }
-
策略2 – 此IAM策略授予SageMaker Data Wrangler获取S3访问点的权限:
{ "Version": "2012-10-17", "Statement": [ { "Sid": "GetAccessPoint", "Effect": "Allow", "Action": "s3:GetAccessPoint", "Resource": "arn:aws:s3:us-east-1:<<accountID>>:accesspoint/<<s3-dw-accesspoint>>" } ] }
- 创建这两个策略并将它们附加到角色上。
在SageMaker Data Wrangler中使用S3访问点
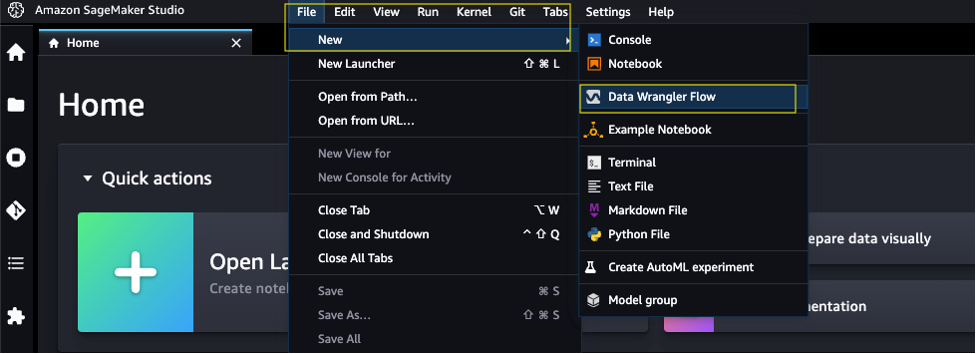
要创建一个新的SageMaker Data Wrangler流,请完成以下步骤:
- 启动SageMaker Studio。
- 在File菜单中,选择New和Data Wrangler Flow。
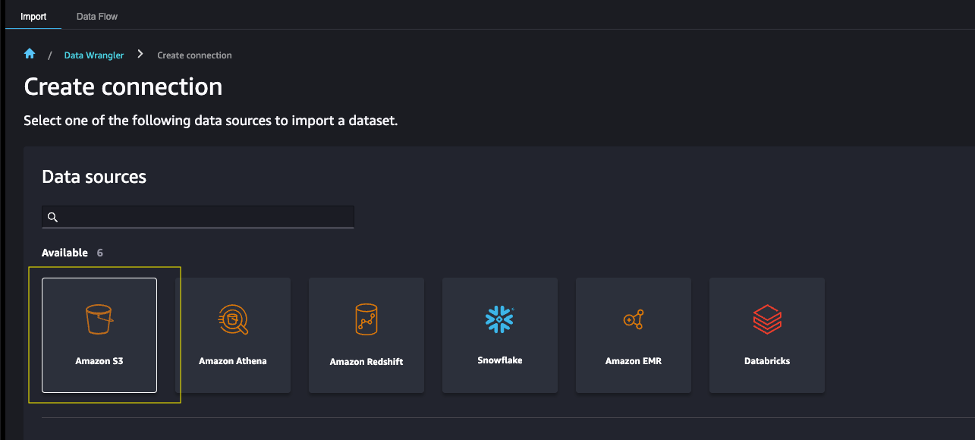
- 选择Amazon S3作为数据源。
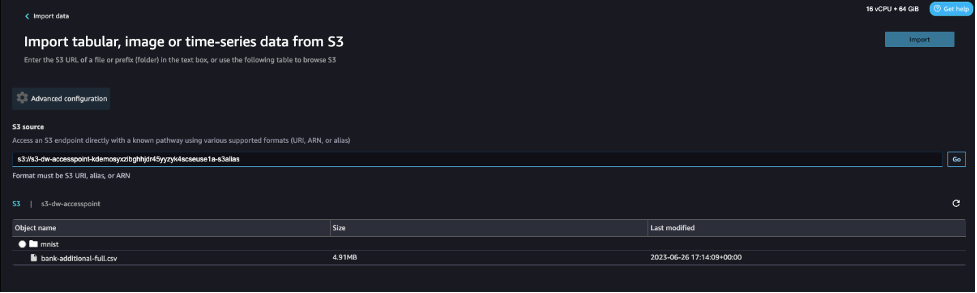
- 对于S3源,请输入之前注意下来的ARN或别名作为S3访问点。
对于本文,我们使用ARN来使用S3访问点导入数据。然而,ARN仅适用于相同区域内的S3访问点和SageMaker Studio域。
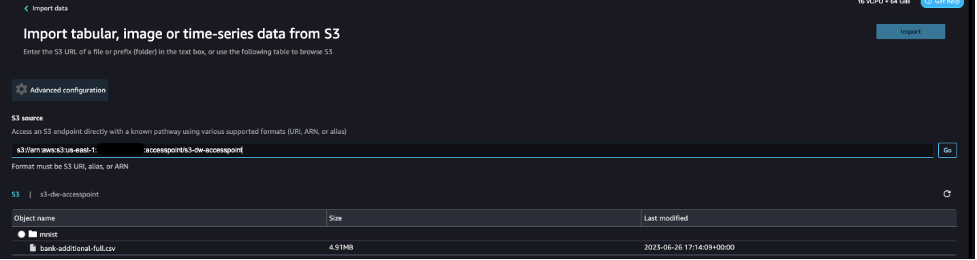
或者,您可以使用别名,如下面的截图所示。与 ARN 不同的是,别名可以跨区域引用。
将数据从 SageMaker Data Wrangler 导出到 S3 访问点
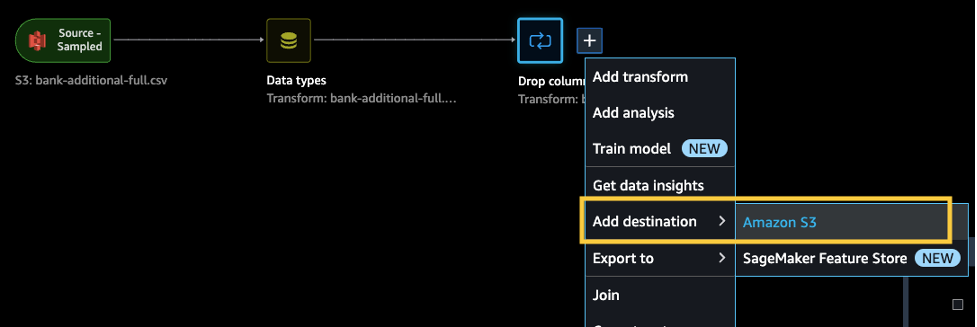
完成所需的转换后,我们可以将结果导出到 S3 访问点。在我们的案例中,我们只是删除了一列。完成您需要的任何转换后,请按照以下步骤进行操作:
- 在数据流中选择加号。
- 选择添加目标和 Amazon S3。
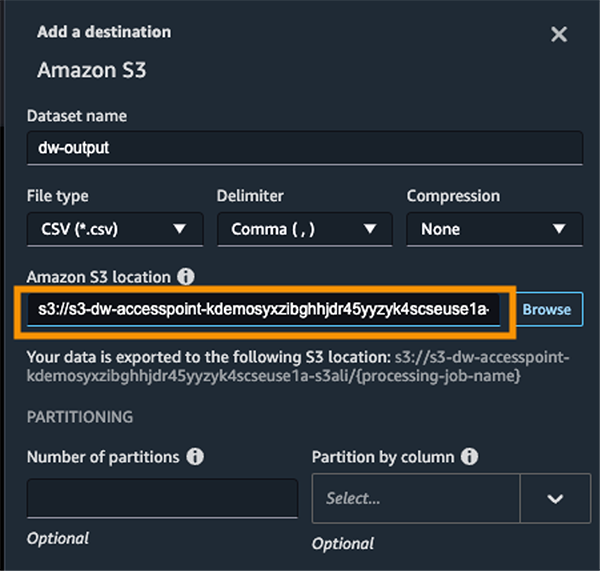
- 输入数据集名称和 S3 位置,引用 ARN。
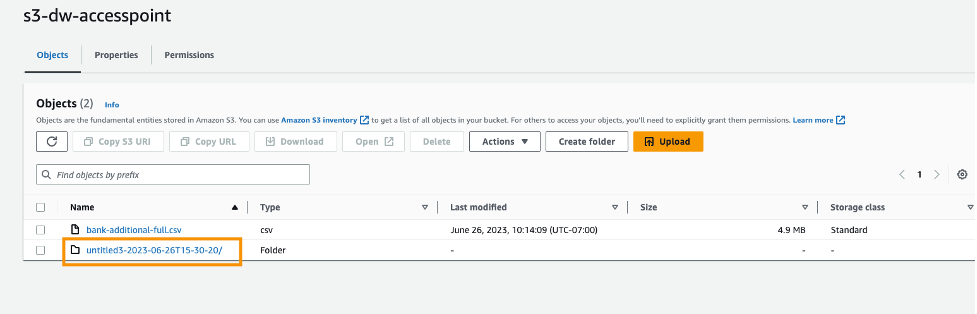
现在,您已经使用 S3 访问点安全高效地导入和导出数据,无需管理复杂的存储桶策略和导航多个文件夹结构。
清理
如果您创建了一个新的 SageMaker 域来跟进,请确保停止任何正在运行的应用程序并删除您的域以停止产生费用。此外,删除任何 S3 访问点并删除任何 S3 存储桶。
结论
在本文中,我们介绍了 SageMaker Data Wrangler 的 S3 访问点的可用性,并向您展示了如何使用此功能简化 SageMaker Studio 中的数据控制。我们从一个 S3 访问点别名访问数据集,并将生成的转换保存到另一个 AWS 账户的 S3 访问点。我们希望您利用此功能消除 SageMaker Studio 用户在数据访问方面的任何瓶颈,并鼓励您尝试一下!




