从多到少:在机器学习中使用降维处理高维数据
降维处理高维数据:机器学习中的维度转换
本文将讨论机器学习问题中的维度诅咒以及降维作为解决该问题的方法。
什么是维度诅咒?
有时,机器学习问题可能包含每个训练实例的成千上万甚至数百万个特征。在这样的数据上训练我们的机器学习模型既消耗资源,又耗时。这个问题通常被称为“维度诅咒”。
解决高维问题的方法
为了解决维度诅咒,我们经常采用不同的方法来减少数据中的特征数量(换句话说,减少维度的数量)。
降维方法的用处
降维方法有助于节省资源和时间。在罕见的情况下,降维甚至可以帮助过滤掉数据中的不必要噪音。降维的另一个用途是数据可视化。由于高维数据的可视化很难实现,即使我们成功进行了可视化,也很难理解,因此将维度降低到2或3通常有助于我们更清晰地可视化数据。
降维的缺点
降维方法并非没有缺点。当我们对数据进行降维时,会丢失信息。此外,使用降维方法并不保证模型性能的提高。请注意,这些方法只是一种更快地训练模型或保留资源的方法,而不是提高模型性能的方法。在大多数情况下,在降维数据上训练的模型性能将比在原始数据上训练的模型性能差。
有两种著名的降维方法。
- 投影
- 流形学习
投影
在大多数实际问题中,数据的特征在所有维度上并不均匀分布。有些几乎是恒定的,而其他的则相关。因此,这些训练实例位于原始高维空间的较低子空间内或相当接近。换句话说,存在着数据的较低维表示,几乎等同于其在原始空间中的表示。
但是,对于某些类型的数据集,这种方法并不是最佳方法。对于某些数据集,使用投影方法会将不同层的实例压缩在一起,这样的投影不能表示原始数据在较低维度上的情况。对于这种类型的数据,流形学习方法更合适。
流形学习
在流形学习方法中,我们将数据展开而不是投影到较低的子空间上。
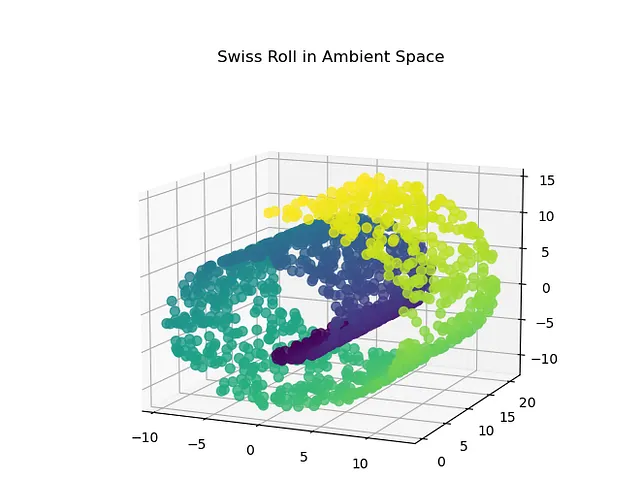
让我们以瑞士卷数据集的示例来理解流形学习。如上所示,通过可视化瑞士卷数据集,我们无法找到数据的投影而不会使许多数据实例重叠。因此,在这种情况下,我们不是将数据投影到较低的子空间上,而是将数据展开。这意味着我们将在二维空间中展开上述数据点,然后理解它。
现在让我们了解一种最流行且广泛使用的降维方法,即主成分分析(PCA)。
PCA是投影类型的方法。它首先找到与数据最接近的超平面,然后将数据投影到该超平面上。
有两种找到适合投影的正确超平面的方法:
- 找到在投影到超平面后,能够保留原始数据集最大方差量的超平面。
- 找到使原始数据集与其在超平面上的投影之间的均方距离最小的超平面。
请注意,我们使用方差作为度量标准,因为数据集的方差代表其所包含的信息量。
PCA 寻找解释方差最大的超平面上的轴(即主成分)。
让我们了解一下如何执行此操作。为了演示 PCA,我们将使用葡萄酒质量数据集。
方法 1
在这种方法中,我们将使用 PCA 类的默认设置进行训练,然后找出每个主成分贡献的方差。然后我们将找出在添加后给出最大方差量的主成分数量。然后再次使用这个理想的主成分数量来训练 PCA 类。
## 导入所需的库
import numpy as np
import pandas as pd
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import seaborn as sns
## 读取数据
wine = pd.read_csv('数据集路径')
wine.head()
## 将数据拆分为自变量和因变量
X, y = wine.drop('quality', axis=1), wine['quality']
## 方法 1
pca = PCA()
pca.fit(X)
cumsum = np.cumsum(pca.explained_variance_ratio_)
no_of_principal_components = np.argmax(cumsum >= 0.95) + 1
print(f"主成分数量:{no_of_principal_components}\n\n方差比例的累计和:{cumsum}.")
sns.set_style('darkgrid')
plt.plot(list(range(1, 12)), cumsum, color='c', marker='x')
plt.xlabel("主成分数量")
plt.ylabel("累计方差比例")
plt.title("寻找理想的主成分数量")
plt.grid(True)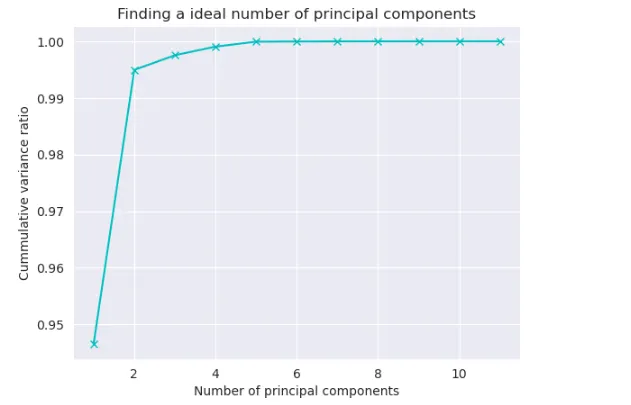
pca = PCA(n_components=2)
X_reduced = pca.fit_transform(X)
X_reduced
方法 2
我们可以将 n_components 的值设置为介于 0 和 1 之间的浮点数,而不是找到理想的主成分数量。该值表示在降维后希望保留的方差量。
pca = PCA(n_components=0.95)
X_reduced = pca.fit_transform(X)
X_reduced
解压缩数据
我们还可以使用 inverse_transform 函数将数据解压缩为其原始大小。显然,这不能给出与原始数据集相同的数据,因为在降维过程中我们丢失了一部分信息(约 5%)。但是,这个解压缩过程将给出非常接近原始数据集的数据。
pseudo_original_data = pca.inverse_transform(X_reduced)
pseudo_original_data
有许多 PCA 算法的变体:随机 PCA、增量 PCA、核 PCA 等。此外,除了这个流行的 PCA 算法之外,还有许多其他的降维算法,例如 isomap、t-分布随机邻域嵌入(t-SNE)、线性判别分析(LDA)等。
希望您喜欢这篇文章。如果对文章有任何想法,请告诉我。非常欢迎任何建设性的反馈。
请在 LinkedIn 上与我联系。我的邮件地址是 [email protected]。祝您有美好的一天!




