解锁媒体中人脸模糊的力量:全面探索和模型比较
解锁媒体中人脸模糊的力量
各种人脸检测和模糊算法的比较

在当今的数据驱动世界中,确保个人的隐私和匿名性至关重要。从保护个人身份到遵守严格的GDPR等法规,对各种媒体格式中人脸进行匿名化的高效可靠解决方案的需求空前。
目录
- 介绍
- 人脸检测- Haar级联- MTCNN- YOLO
- 人脸模糊- 高斯模糊- 像素化
- 结果和讨论- 实时性能- 基于场景的评估- 隐私
- 在视频中的使用
- Web应用程序
- 结论
介绍
在这个项目中,我们探讨并比较了几种人脸模糊的解决方案,并开发了一个Web应用程序,以便进行简单的评估。让我们来探索推动这样一个系统需求的多样化应用:
- 保护隐私
- 导航规范环境:随着规范环境的快速发展,全球各地的行业和地区正在实施更严格的规范来保护个人身份。
- 培训数据的机密性:机器学习模型依赖于多样化和精心准备的训练数据。然而,共享此类数据通常需要仔细进行匿名处理。
这个解决方案可以归结为两个关键组成部分:
- 人脸检测
- 人脸模糊技术
人脸检测
为了解决匿名化的挑战,第一步是定位图像中存在人脸的区域。为此,我测试了三个图像检测模型。
Haar级联

Haar级联是一种用于在图像或视频中进行对象检测(例如人脸)的机器学习方法。它通过利用一组称为“Haar-like特征”(图1)的训练特征来实现。这些特征是简单的矩形滤波器,专注于图像区域内的像素强度变化。这些特征可以捕捉到人脸中常见的边缘、角度和其他特征。
训练过程涉及提供正面脸部图像的正例和不包含脸部的负例。然后,算法通过调整特征的权重来学习区分这些示例。训练完成后,Haar级联实际上成为一个层次化的分类器,每个阶段都会逐步改进检测过程。
为了进行人脸检测,我使用了预训练的Haar级联模型,该模型是在正面人脸图像上进行训练的。
import cv2face_cascade = cv2.CascadeClassifier('./configs/haarcascade_frontalface_default.xml')def haar(image): gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30)) print(len(faces) + " total faces detected.") for (x, y, w, h) in faces: print(f"Face detected in the box {x} {y} {x+w} {y+h}")MTCNN
MTCNN(多任务级联卷积网络)是一种复杂而高精度的人脸检测算法,超越了Haar级联的能力。MTCNN旨在在具有不同人脸大小、方向和光照条件的场景中表现出色,它利用一系列神经网络,每个网络都针对人脸检测过程中的特定任务进行了定制。
- 第一阶段 —— 提案生成:MTCNN通过一个小型神经网络生成大量潜在的面部区域(边界框)来启动该过程。
- 第二阶段 —— 优化:第一阶段生成的候选区域在这一步骤中经过筛选。第二个神经网络评估提议的边界框,调整它们的位置以更精确地与真实的面部边界对齐。这有助于提高准确性。
- 第三阶段 —— 面部特征点:该阶段识别面部特征点,如眼角、鼻子和嘴巴。神经网络被用于准确定位这些特征。
MTCNN的级联结构使其能够在过程的早期迅速丢弃没有面部的区域,将计算集中在可能包含面部的区域上。它处理不同尺度(缩放级别)的面部和旋转的能力使其在复杂场景中比Haar级联更适用。然而,它的计算强度来自于其基于神经网络的顺序方法。
对于MTCNN的实现,我使用了mtcnn库。
import cv2from mtcnn import MTCNNdetector = MTCNN()def mtcnn_detector(image): faces = detector.detect_faces(image) print(len(faces) + " total faces detected.") for face in faces: x, y, w, h = face['box'] print(f"Face detected in the box {x} {y} {x+w} {y+h}")YOLOv5
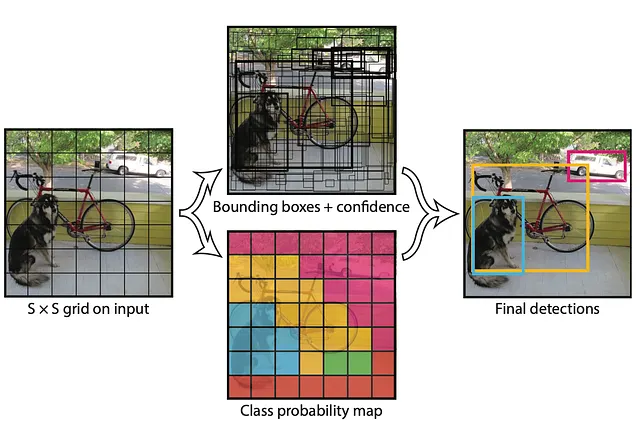
YOLO(You Only Look Once)是一种用于检测多种对象(包括人脸)的算法。与其前身不同,YOLO通过一次前向通过神经网络进行检测,使其更快速、更适用于实时应用和视频。使用YOLO在媒体中检测人脸的过程可以分为四个部分:
- 图像网格划分:输入图像被划分为一个网格。每个单元负责预测其边界内的对象。对于每个单元,YOLO会预测边界框、对象概率和类别概率。
- 边界框预测:在每个单元内,YOLO预测一个或多个边界框及其相应的概率。这些边界框表示潜在的对象位置。每个边界框由其中心坐标、宽度、高度和边界框内存在对象的概率来定义。
- 类别预测:对于每个边界框,YOLO预测其可能属于的各种类别(例如,“人脸”,“汽车”,“狗”)的概率。
- 非最大值抑制(NMS):为了消除重复的边界框,YOLO应用了NMS。该过程通过评估边界框的概率和与其他框的重叠情况来丢弃冗余的边界框,仅保留最自信和不重叠的边界框。
YOLO的主要优势在于其速度。由于它通过神经网络一次性处理整个图像,所以它比涉及滑动窗口或区域提议的算法要快得多。然而,对于较小的物体或拥挤的场景,这种速度可能会稍微降低精度。
可以通过在人脸特定数据上对其进行训练,并修改其输出类别以仅包括一个类别(“人脸”)来将YOLO适应于人脸检测。为此,我使用了基于YOLOv5构建的“yoloface”库。
import cv2from yoloface import face_analysisface=face_analysis()def yolo_face_detection(image): img,box,conf=face.face_detection(image, model='tiny') print(len(box) + " total faces detected.") for i in range(len(box)): x, y, h, w = box[i] print(f"Face detected in the box {x} {y} {x+w} {y+h}")人脸模糊处理
在识别图像中潜在人脸的边界框之后,下一步是对其进行模糊处理以去除其身份信息。为此任务,我开发了两种实现方式。图4提供了一个演示用的参考图像。
高斯模糊

高斯模糊是一种用于减少图像噪点和模糊细节的图像处理技术。这在人脸模糊领域特别有用,因为它可以擦除图像该部分的具体细节。它计算每个像素周围邻域内像素值的平均值。这个平均值以被模糊的像素为中心,使用高斯分布计算,给附近的像素更高的权重,给远离的像素较低的权重。结果是一个软化的图像,减少了高频噪声和细节。应用高斯模糊的结果如图5所示。
高斯模糊有三个参数:
- 要模糊的图像区域。
- 核大小:用于模糊操作的矩阵。较大的核大小会导致更强的模糊效果。
- 标准差:较高的值增强了模糊效果。
f = image[y:y + h, x:x + w]blurred_face = cv2.GaussianBlur(f, (99, 99), 15) # 您可以调整模糊参数image[y:y + h, x:x + w] = blurred_face像素化

像素化是一种图像处理技术,其中图像中的像素被更大的单色块替换。这个效果是通过将图像分成网格单元来实现的,每个单元对应一组像素。然后,单元中所有像素的颜色或强度被视为该单元中所有像素颜色的平均值,并且将这个平均值应用于该单元中的所有像素。这个过程创建了一个简化的外观,减少了图像中的细节级别。应用像素化的结果如图6所示。正如您所看到的,像素化极大地复杂化了人物身份的识别。
像素化只有一个主要参数,它决定了多少个分组的像素应该代表一个特定的区域。例如,如果我们有一个包含人脸的(10,10)区域的图像部分,它将被一个10×10像素组替代。较小的数值会导致更大的模糊效果。
f = image[y:y + h, x:x + w]f = cv2.resize(f, (10, 10), interpolation=cv2.INTER_NEAREST)image[y:y + h, x:x + w] = cv2.resize(f, (w, h), interpolation=cv2.INTER_NEAREST)结果与讨论
我将从两个角度评估不同的算法:实时性能分析和特定图像场景。
实时性能
使用相同的参考图像(图4),测量每个人脸检测算法在图像中定位人脸边界框所需的时间。结果基于每个算法的10次测量的平均值。模糊算法所需的时间微不足道,不会在评估过程中考虑。

可以观察到,由于YOLOv5通过神经网络的单次处理,实现了最佳性能(速度)。相比之下,像MTCNN这样的方法需要对多个神经网络进行顺序遍历。这进一步增加了算法并行化的复杂性。
基于场景的性能
为了评估上述算法的性能,在参考图像(图4)之外,我选择了几个在不同场景下测试算法的图像:
- 参考图像(图4)
- 人群密集区域 – 评估算法对不同大小的人脸的捕捉能力,有些人脸离得近,有些人脸离得远(图8)
- 侧面人脸 – 测试算法对非直视摄像头的人脸的检测能力(图10)
- 翻转人脸,180度 – 测试算法对旋转180度的人脸的检测能力(图11)
- 翻转人脸,90度 – 测试算法对旋转90度侧身的人脸的检测能力(图12)



Haar Cascade
Haar Cascade算法在匿名化人脸方面表现良好,但也有一些例外情况。它能够很好地检测到参考图像(图4)和“多张人脸”场景(图9)。在“人群密集区域”场景(图8)中,它处理得不错,尽管有些人脸没有完全被检测到或者距离较远。Haar Cascade在人脸非直视摄像头的情况(图10)和旋转人脸的情况(图11和图12)下遇到挑战,无法完全识别人脸。

MTCNN
MTCNN成功实现了与Haar Cascade非常相似的结果,具有相同的优点和缺点。此外,MTCNN在具有较暗肤色的图9中检测人脸时存在困难。

YOLOv5
YOLOv5产生的结果与Haar Cascade和MTCNN稍有不同。它成功地检测到了人们没有直接看向相机的脸部(图10),以及被旋转180度的脸部(图11)。然而,在“人群”图像(图8)中,它对于较远处的脸部的检测效果不如前述算法有效。

隐私
在处理图像时考虑隐私挑战时,一个关键的方面是在保持图像的自然外观的同时使人脸无法被识别。
高斯模糊
高斯模糊有效地模糊了图像中的人脸区域(如图5所示)。然而,其成功与所使用的高斯分布的参数密切相关。在图5中,可以看出人脸特征仍然可辨,这表明需要更高的标准差和核大小才能达到最佳效果。
像素化
像素化(如图6所示)通常在视觉上更受人眼的喜欢,因为它作为一种人脸模糊方法与高斯模糊相比更为熟悉。像素化中使用的像素数量在这种情况下起着重要作用,较少的像素数量会使人脸不太容易被识别,但可能会导致外观不太自然。
总的来说,像素化算法在高斯模糊算法之上更受人们青睐。这源于它的熟悉度和上下文的自然性,使隐私和美观之间达到了平衡。
逆向工程
随着AI工具的兴起,必须预见到逆向工程技术可能会针对模糊图像中的隐私过滤器进行去除。然而,模糊人脸的行为本身会将特定的面部细节不可逆地替换为更加概括的细节。目前,只有在提供了同一人的清晰参考图像的情况下,AI工具才能逆向工程模糊的人脸。矛盾的是,这与首先需要逆向工程的需求相矛盾,因为它假设已经知道个体的身份。因此,面部模糊作为一种高效且必要的手段,在面对不断发展的AI能力时保护隐私。
在视频中的应用
由于视频本质上是一系列图像的序列,相对而言,将每个算法修改为对视频进行匿名化是相对简单的。然而,在这里,处理时间变得至关重要。对于一个以60帧每秒(每秒图像数)录制的30秒视频,算法需要处理1800帧。在这种情况下,像MTCNN这样的算法将不可行,尽管它们在某些情况下有所改进。因此,我决定使用YOLO模型来实现视频的匿名化。
import cv2from yoloface import face_analysisface=face_analysis()def yolo_face_detection_video(video_path, output_path, pixelate): cap = cv2.VideoCapture(video_path) if not cap.isOpened(): raise ValueError("无法打开视频文件") # 获取视频属性 fps = int(cap.get(cv2.CAP_PROP_FPS)) frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) # 定义编解码器并为输出视频创建VideoWriter对象 fourcc = cv2.VideoWriter_fourcc(*'H264') out = cv2.VideoWriter(output_path, fourcc, fps, (frame_width, frame_height)) while cap.isOpened(): ret, frame = cap.read() if not ret: break tm = time.time() img, box, conf = face.face_detection(frame_arr=frame, frame_status=True, model='tiny') print(pixelate) for i in range(len(box)): x, y, h, w = box[i] if pixelate: f = img[y:y + h, x:x + w] f = cv2.resize(f, (10, 10), interpolation=cv2.INTER_NEAREST) img[y:y + h, x:x + w] = cv2.resize(f, (w, h), interpolation=cv2.INTER_NEAREST) else: blurred_face = cv2.GaussianBlur(img[y:y + h, x:x + w], (99, 99), 30) # You can adjust blur parameters img[y:y + h, x:x + w] = blurred_face print(time.time() - tm) out.write(img) cap.release() out.release() cv2.destroyAllWindows()Web应用
为了对不同的算法进行简化评估,我创建了一个Web应用程序,用户可以上传任何图像或视频,选择人脸检测和模糊算法,在处理后将结果返回给用户。实现是使用Flask和Python在后端完成的,利用了上述库以及OpenCV,并使用React.js在前端与模型进行用户交互。完整的代码可以在此链接中找到。
结论
在本文的范围内,探索了包括Haar级联、MTCNN和YOLOv5在内的各种人脸检测算法,并在不同的方面进行了比较和分析。该项目还侧重于图像模糊技术。
在某些情况下,Haar级联被证明是一种高效的方法,表现出良好的时间性能。MTCNN作为一种具有稳定人脸检测能力的算法,在各种条件下都表现出色,尽管在非传统朝向的脸部上有些困难。YOLOv5以其实时人脸检测能力,在时间为关键因素的场景(如视频)中成为一个优秀的选择,尽管在群组设置中略微降低了准确性。
所有算法和技术都集成到了一个单一的Web应用程序中。该应用程序提供了对所有人脸检测和模糊方法的简单访问和利用,以及使用模糊技术处理视频的能力。
本文是我在斯科普里计算机科学与工程学院“图像数字处理”课程中的工作总结。感谢您的阅读!