类别不平衡:从SMOTE到SMOTE-NC和SMOTE-N
类别不平衡:SMOTE到SMOTE-NC和SMOTE-N
探索三种算法解决类别不平衡问题
在之前的故事中,我们解释了朴素随机过采样和随机过采样示例(ROSE)算法的工作原理。更重要的是,我们还定义了类别不平衡问题,并从直觉上得出了解决方案。我强烈建议查看那个故事,以确保对类别不平衡问题有清晰的理解。
在本故事中,我们将继续考虑SMOTE、SMOTE-NC和SMOTE-N算法。但在此之前,值得指出的是,我们在上个故事中考虑的两种算法适用于以下实现框架:
- 定义算法如何接受属于X类的需要Nx个示例的数据,并通过过采样计算这些示例
- 根据某些比率超参数,计算需要添加到每个类别的点的数量
- 对于每个类别运行算法,然后将所有新添加的点与原始数据合并,形成最终的过采样数据集
对于随机过采样和ROSE算法,生成类X的Nx个示例的算法也是这样的:
- 从属于类X的数据中随机选择Nx个点(可重复选择)
- 对所选择的每个点执行逻辑以生成一个新点(例如,复制或放置一个高斯分布然后从中采样)
我们将在本故事中考虑的其他算法也符合同样的框架。
SMOTE(合成少数类过采样技术)
因此,要解释SMOTE的作用,我们只需要回答一个问题:从类X中随机选择的Nx个示例中的每个示例执行的逻辑是什么,以生成Nx个新示例?
答案如下:
- 找到点的k个最近邻(k是算法的超参数)
- 随机选择其中一个
- 从点到随机选择的邻居绘制一条线段
- 在该线段上随机选择一个点
- 将其作为新点返回
在数学上,
- 如果点x_i具有最近邻z_i1、z_i2、…、z_ik
- 如果j是[1,k]之间的随机数
- 如果r是[0,1]之间的随机数
那么对于每个点x_i,SMOTE只需简单地应用以下公式生成一个新点x_i’:

这就是SMOTE算法的全部内容。从点x_i开始,沿着矢量z_ij – x_i朝着距离r的方向走,然后放置一个新点。

一个小的附注是,算法的操作方式与论文中所述的方式有一些小差异。特别是,作者假设比率是整数(如果不是,则向下取整)。如果类X的比率是整数C,则对其中的每个点进行C次随机选择邻居并应用我们描述的SMOTE逻辑。在实践中,当实现SMOTE时,通常将其推广为使用浮点数比率工作,如我们所述,只需随机选择Nx个点,然后对每个点应用SMOTE。对于整数比率(例如C=2),平均每个点被选择两次,我们回到原始算法。这是有道理的,因为它是从重复使用整数比率进行过采样到随机过采样的相同转换,而上一个故事中已经解释过了。
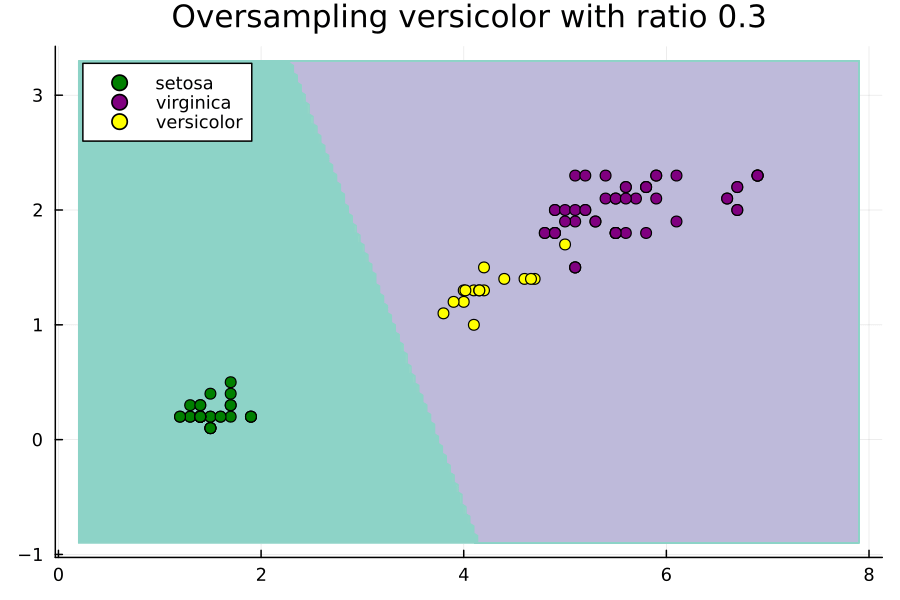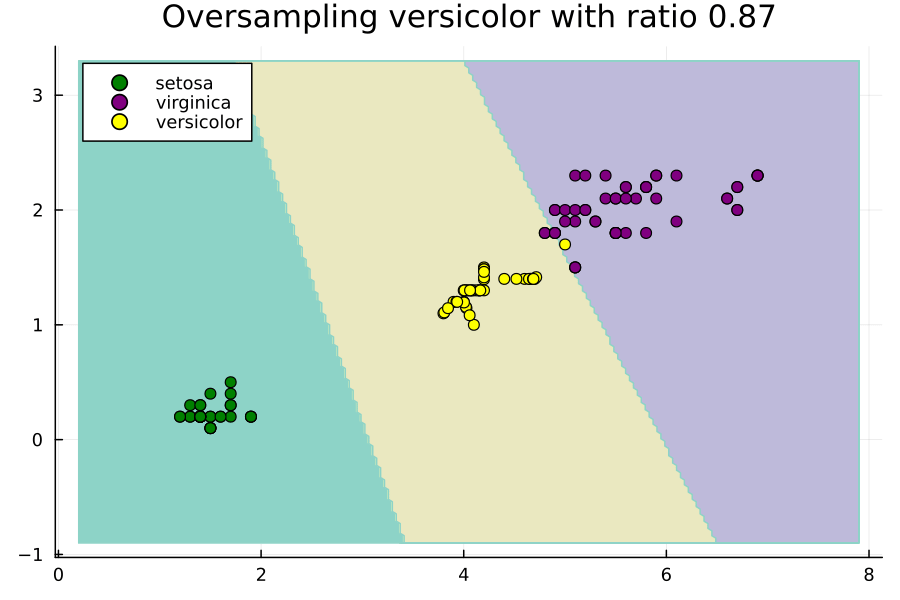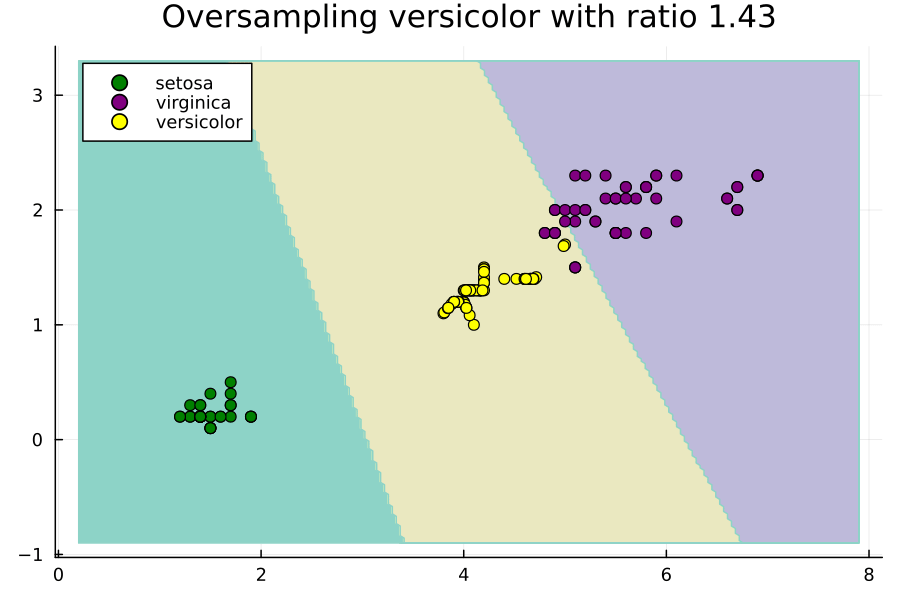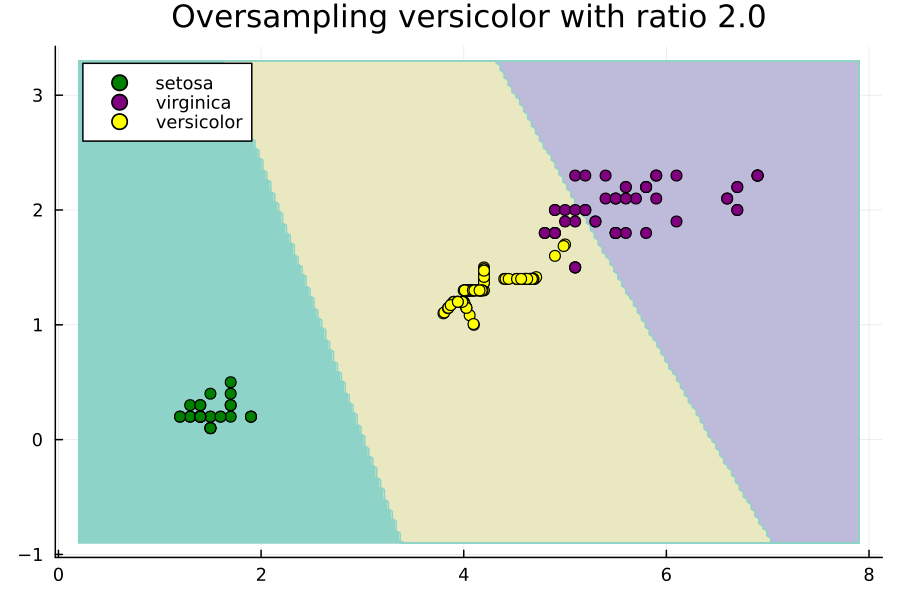
这个动画展示了在不平衡的Iris数据集的子集上,通过改变过采样比率来改变SVM的决策区域是如何变化的。这里的比率相对于多数类的大小。也就是说,比率为1.0将设置Nx,使得versicolor类具有与virginica类一样多的示例。
你可能会想为什么SMOTE会比ROSE更好。毕竟,SMOTE在论文中生成点的逻辑没有得到证明;与此同时,ROSE中从P(x|y)的估计中进行采样更加合理和直观。一个可能的问题是,获得P(x|y)的良好估计需要大量的数据;然而,我们知道少数类通常只有很少的数据。如果我们没有很多数据,我们有两个选择:
- 选择带宽太小,这样我们就回到了可能出现过拟合的情况,就像随机过采样一样
- 选择带宽太大,极端情况下等同于只从特征空间中均匀地添加随机点(即不真实的例子)
如果你仔细思考一下,我们应该对SMOTE这个问题不太担心。如果存在一个完全分离数据的超平面,那么在应用SMOTE后,该解决方案仍然存在。事实上,SMOTE生成点的方式可能会使非线性超平面变得更加线性,因此它似乎具有更低的过拟合风险。
SMOTE-NC(SMOTE-Nominal Continuous)
虽然ROSE和SMOTE似乎相比简单的随机过采样提供了显著的改进,但它们的缺点是丧失了处理分类变量的能力,而这对于简单的随机过采样来说并不是问题。SMOTE的作者足够聪明,想出了一种方法来解决这个问题,即开发了一个扩展算法,用于处理同时存在分类特征的情况。
你可能会认为对分类特征进行编码是一种解决办法;然而,你并不完全正确,因为SMOTE或ROSE将把它们视为连续变量,并为它们生成无效的值。例如,如果一个特征是二进制的,那么选择的点沿着线的位置可能是0.57,这既不是0也不是1。四舍五入是个坏主意,因为那相当于随机选择它是0还是1。
回想一下,SMOTE是如何生成新点的:
- 假设点x_i有最近的邻居z_i1,z_i2,…,z_ik
- 设j是[1,k]的随机数
- 设r是[0, 1]的随机数
然后对于每个点x_i,SMOTE通过简单地应用
生成一个新点x_i’。
很明显,除非我们扩展它来回答以下两个问题,否则我们不能在存在分类特征的情况下应用相同的方法:
- 如何找到k个最近的邻居?欧几里得距离度量只适用于连续特征。
- 如何生成新点?我们不能应用SMOTE方程来生成x_i’的分类部分。
对于第一个问题,作者建议修改欧几里得距离以考虑分类部分。假设x_i和z_ij各自涉及m个连续特征和n个分类特征,则在修改后的度量中,连续特征自然相减并平方,然后为每对不同的分类特征添加一个常数惩罚。这个惩罚特别是所有连续特征方差的中位数,可以在算法开始时计算得到。
例如,要衡量两个点x_1和x_2之间的距离

那么如果标准差的中位数是m,则距离由以下公式给出:
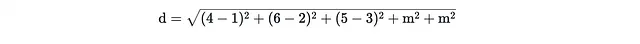
最后两项表示最后两个分类特征的差异。
虽然作者没有为度量提供任何解释,但观察到,衡量分类特征之间距离的最常见方法之一是汉明距离。它只为每对不同的分类特征添加1。如果汉明距离为6,则意味着两个点在6个分类特征上具有不同的值。在我们的情况下,显然将惩罚设置为1,就像在汉明距离中一样,是不直观的,因为如果连续特征经常强烈变化,那么1的总和将在总和中非常微不足道,相当于忽略了度量中的分类特征。使用任意两个连续特征的平均平方差作为惩罚似乎是解决这个问题的办法,因为如果连续特征的方差经常很大,那么惩罚也很大,而不是可以忽略的。唯一的问题是作者使用了方差的中位数而不是均值,这可能可以通过它对离群值的鲁棒性来解释。
回答第二个问题要简单得多,现在我们已经使用修改后的度量找到了k个最近邻居,我们可以像往常一样使用SMOTE方程生成新点的连续部分。为了生成新点的分类部分,我们可以简单地取k个最近邻居的分类部分的众数。也就是说,让邻居们在分类部分的值上投票,最常见的值将占主导地位。
由此可见,SMOTE-NC生成新点的步骤如下:
- 找到该点的k个最近邻居(k是该算法的超参数),使用修改后的欧几里得度量
- 随机选择其中一个邻居
- 在连续特征空间中,从该点到该邻居绘制一条线段
- 在该线段上随机选择一个点
- 将其作为新点的连续部分
- 对于新点的分类部分,取k个最近邻居的分类部分的众数
SMOTE-N(SMOTE-名义)
很明显,当没有分类特征参与时,SMOTE-NC就变成了SMOTE,因为此时惩罚项为零,并且在生成过程中跳过了众数步骤。然而,如果没有连续特征参与,则算法处于一种不稳定的状态,因为没有定义惩罚项,也就没有连续特征。你可以将其设置为1或其他值,然后按照正常方式操作算法,但这并不理想,因为在计算最近邻居时很容易出现很多并列的情况。如果一个点与另外10个点之间的汉明距离为7,它们真的都与该点同样接近吗?还是它们只是共同具有与该点在7个特征上的差异?
SMOTE-N是论文中提出的另一个处理纯分类数据的算法。它通过在分类特征上使用另一种距离度量来对上述问题做出负回应。一旦找到k个最近邻居,就使用模式计算确定新点;然而,这一次,点本身也参与了计算。
因此,只需解释SMOTE-N中使用的距离度量即可执行K-NN。该度量称为“修改值距离度量”(Cost&Salzberg,1993),其工作方式如下:给定具有q个分类值和分别具有p_1,p_2,…,p_q个可能值的每个分类特征的两个特征向量。
- 通过一个长度为K的向量V对每个分类值进行编码,其中K是类别的数量。V[i]应该是该值在第i个类别中的频率除以所有类别中的频率。
- 现在,任何分类向量都由一个长度为k的张量表示
- 通过计算每对长度为k的向量之间的曼哈顿距离,然后取结果的L2范数,计算表示由该张量表示的任何两个分类向量之间的距离
举个例子,假设我们想要找到以下两个分类向量之间的距离

假设有3个类别,编码后我们得到

计算每对向量之间的曼哈顿距离,得到
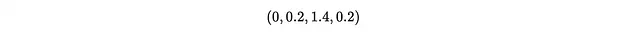
经计算,得到1.428的L2范数。
准确地说,论文指出可以使用L1范数或L2范数,但没有决定在算法中使用哪个(这里我们选择了L2)。
你可能会问为什么这比使用简单的汉明距离更好。明确的答案是作者没有给出解释。然而,为了提供一些直观的理解,我们之前提到汉明距离在KNN的距离计算中往往会导致很多并列情况。假设我们有三个分类向量

在这里,Hamming距离表明x_2和x_3与x_1的距离一样近,因为在两种情况下,Hamming距离都为1。与此同时,修改后的值差异度量会先考虑每个值在类别上的分布情况,然后再决定哪个更接近。假设B2每个类别的频率是[0.3, 0.2, 0.5],B3每个类别的频率是[0.1, 0.9, 0],B1每个类别的频率是[0.25, 0.25, 0.5]。在这种情况下,修改后的值差异度量会表明x_3更接近于x_1,因为B1与B2的距离比B3与B2的距离更近。从概率的角度来看,如果我们要收集一个具有未知类别的新点,那么知道该类别是B2还是B3并不能很好地预测类别,从这个意义上说它们是相似的或可互换的。
因此,总结一下,SMOTE-N算法的操作步骤如下来生成一个新点:
- 使用修改后的值差异度量找到该点的k个最近邻(k是算法的超参数)
- 返回邻居(包括该点本身)的分类值的众数,以生成新点
就是这样!现在你应该清楚地知道SMOTE、SMOTE-N和SMOTE-NC是如何工作的了。下次见,再见。
参考文献:
[1] N. V. Chawla, K. W. Bowyer, L. O.Hall, W. P. Kegelmeyer,“SMOTE:合成少数类过采样技术”,人工智能研究杂志,321–357,2002年。






