神经网络剪枝与组合优化
神经网络剪枝与组合优化' can be condensed to '神经网络优化'.
由Hussein Hazimeh,Athena团队的研究科学家和MIT的研究生Riade Benbaki发布
现代神经网络在语言、数学推理和视觉等各种应用中取得了令人印象深刻的性能。然而,这些网络通常使用大型架构,需要大量的计算资源。这使得在资源受限的环境(如可穿戴设备和智能手机)中向用户提供此类模型变得不切实际。一种广泛使用的减少预训练网络推理成本的方法是通过修剪它们的权重,以一种不显著影响效用的方式。在标准神经网络中,每个权重定义了两个神经元之间的连接。因此,在修剪权重之后,输入将通过一组更小的连接传播,从而需要更少的计算资源。
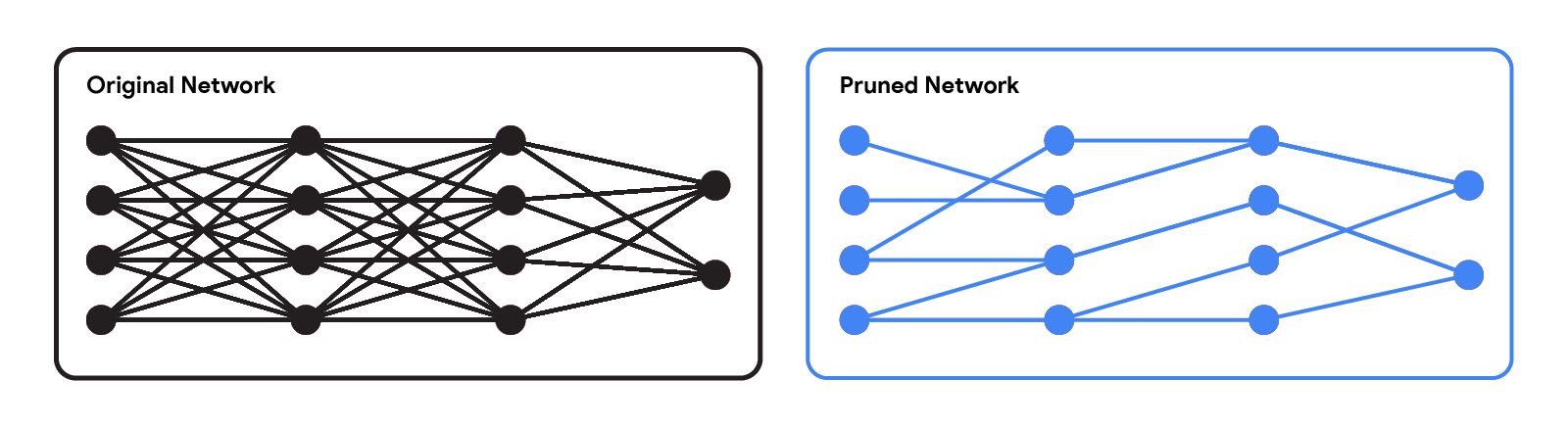 |
| 原始网络 vs. 修剪后的网络。 |
修剪方法可以应用于网络训练过程的不同阶段:训练后、训练中或训练前(即在权重初始化后立即)。在本文中,我们重点关注训练后的设置:给定一个预训练的网络,我们如何确定应该修剪哪些权重?一种常用的方法是幅度修剪,它删除幅度最小的权重。虽然高效,但该方法并未直接考虑移除权重对网络性能的影响。另一种流行的范式是基于优化的修剪,它根据移除权重对损失函数的影响程度来删除权重。尽管在概念上具有吸引力,但大多数现有的基于优化的方法似乎在性能和计算需求之间存在严重的权衡。那些进行粗略近似的方法(如假设对角Hessian矩阵)可以良好地扩展,但性能相对较低。另一方面,做更少近似的方法往往表现更好,但似乎不太可扩展。
在“Fast as CHITA: Neural Network Pruning with Combinatorial Optimization”中,我们介绍了如何开发一种用于大规模修剪预训练神经网络的基于优化的方法。CHITA(即“组合无Hessian迭代阈值算法”)在可扩展性和性能权衡方面优于现有的修剪方法,并且通过利用高维统计学、组合优化和神经网络修剪等多个领域的进展来实现。例如,对于修剪ResNet,CHITA的速度可以比现有最先进的方法快20倍到1000倍,并且在许多设置中提高准确性超过10%。
贡献概述
CHITA相对于流行方法有两个显著的技术改进:
- 高效使用二阶信息:使用二阶信息(即与二阶导数相关的信息)的修剪方法在许多情况下达到了最先进的水平。在文献中,这些信息通常通过计算Hessian矩阵或其逆来使用,但这个操作很难扩展,因为Hessian矩阵的大小与权重数量呈二次关系。通过精心重新构造,CHITA在不必显式计算或存储Hessian矩阵的情况下使用二阶信息,从而实现更高的可扩展性。
- 组合优化:流行的基于优化的方法使用简单的优化技术来单独修剪权重,即在决定修剪某个权重时,它们不考虑其他权重是否已被修剪。这可能导致修剪重要权重,因为在单独考虑时被认为不重要的权重在其他权重被修剪时可能变得重要。CHITA通过使用更先进的组合优化算法解决了这个问题,该算法考虑了修剪一个权重对其他权重的影响。
在下面的章节中,我们将讨论CHITA的修剪公式和算法。
计算友好的修剪公式
有许多可能的修剪候选项,这些候选项是通过仅保留原始网络中的一部分权重来获得的。令k为一个用户指定的参数,表示要保留的权重的数量。修剪可以自然地被形式化为一个最佳子集选择(BSS)问题:在所有可能的修剪候选项(即,仅保留k个权重的权重子集)中,选择具有最小损失的候选项。
 |
| 将修剪作为BSS问题:在具有相同总权重数的所有可能的修剪候选项中,最佳候选项被定义为损失最小的候选项。此示例显示了四个候选项,但实际上可能会更多。 |
在原始损失函数上解决修剪BSS问题通常是计算上难以处理的。因此,类似于先前的工作(如OBD和OBS),我们通过使用二阶泰勒级数将损失近似为二次函数,其中Hessian估计为经验Fisher信息矩阵。虽然梯度通常可以高效地计算,但由于其庞大的大小,计算和存储Hessian矩阵是代价高昂的。在文献中,通常通过对Hessian(例如,对角矩阵)和算法(例如,隔离修剪权重)进行限制性假设来应对这一挑战。
CHITA使用了修剪问题(使用二次损失的BSS)的高效重构,避免了显式计算Hessian矩阵,同时仍然使用了该矩阵的所有信息。这是通过利用经验Fisher信息矩阵的低秩结构实现的。这个重构可以被看作是一个稀疏线性回归问题,其中每个回归系数对应于神经网络中的某个权重。在解决这个回归问题后,设置为零的系数将对应于应该修剪的权重。我们的回归数据矩阵是(n x p),其中n是批量(子样本)大小,p是原始网络中的权重数。通常情况下,n << p,因此存储和操作这个数据矩阵比使用(p x p)的Hessian的常见修剪方法更可扩展。
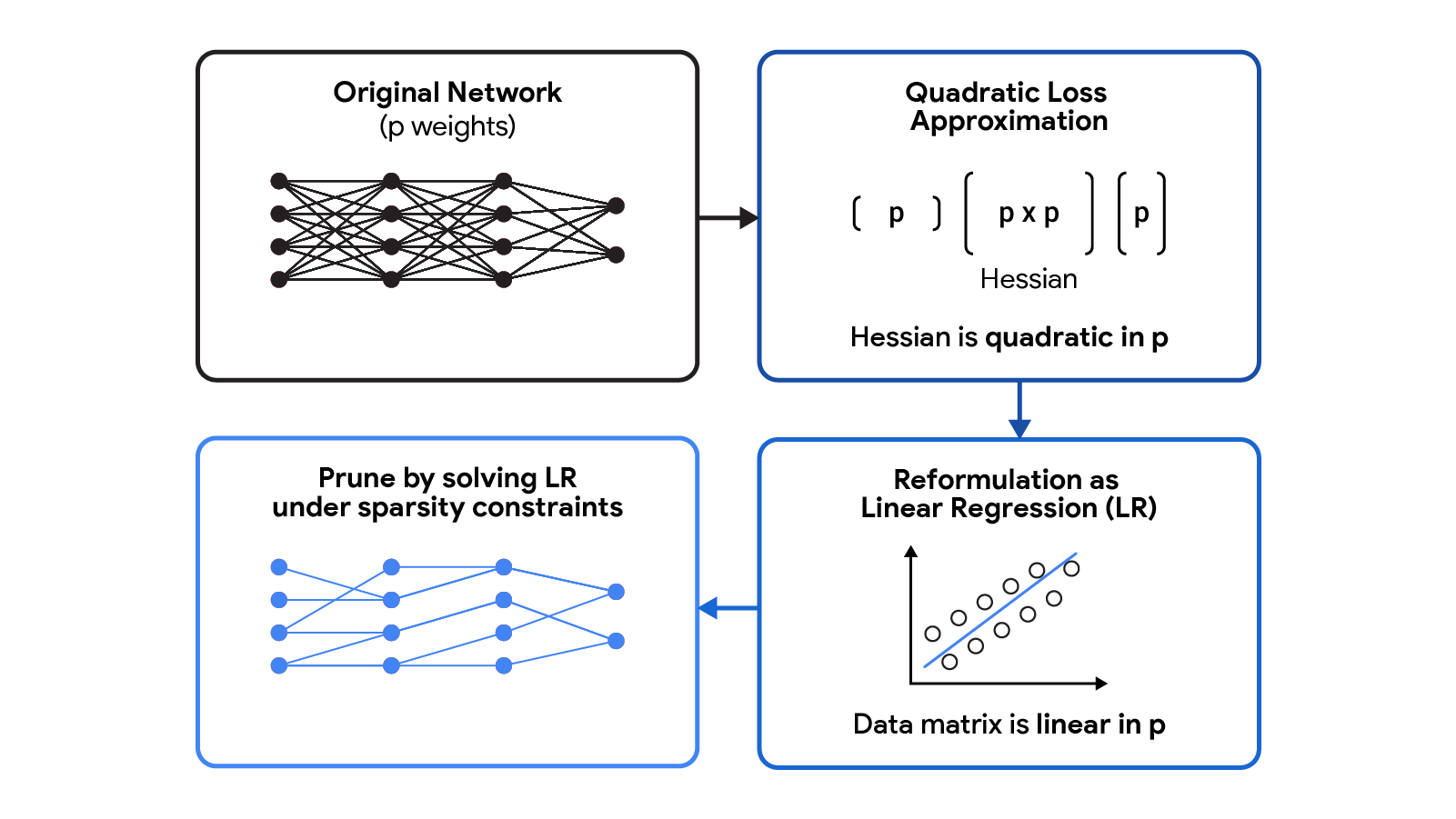 |
| CHITA将需要昂贵的Hessian矩阵的二次损失近似重构为线性回归(LR)问题。LR的数据矩阵在p方面是线性的,这使得重构比原始的二次近似更具可扩展性。 |
可扩展的优化算法
CHITA将修剪约束为具有最多k个非零回归系数的线性回归问题。为了获得此问题的解决方案,我们考虑了著名的迭代硬阈值(IHT)算法的修改版。IHT执行梯度下降,在每次更新后执行以下后处理步骤:将所有Top-k之外的回归系数(即,具有最大幅度的k个系数)设为零。IHT通常可以很好地解决这个问题,并且通过迭代地探索不同的修剪候选项并联合优化权重来实现这一目标。
由于问题规模的原因,使用恒定的学习率的标准IHT算法可能会收敛非常缓慢。为了更快的收敛,我们开发了一种新的线搜索方法,利用问题的结构来找到一个合适的学习率,即能够使损失函数有足够大的下降。我们还采用了几种计算方案来提高CHITA的效率和二阶近似的质量,从而得到了一个改进的版本,我们称之为CHITA++。
实验
我们将CHITA的运行时间和准确性与几种最先进的剪枝方法进行了对比,包括ResNet和MobileNet等不同架构。
运行时间:与单独剪枝权重的方法相比,CHITA更具可扩展性。例如,当剪枝ResNet时,CHITA的加速比可以达到1000倍以上。
剪枝后的准确性:下面,我们将CHITA和CHITA++与幅度剪枝(MP)、Woodfisher(WF)和组合脑外科医生(CBS)进行了比较,这些方法用于剪枝模型权重的70%。总体而言,我们看到CHITA和CHITA++有了很好的改进。
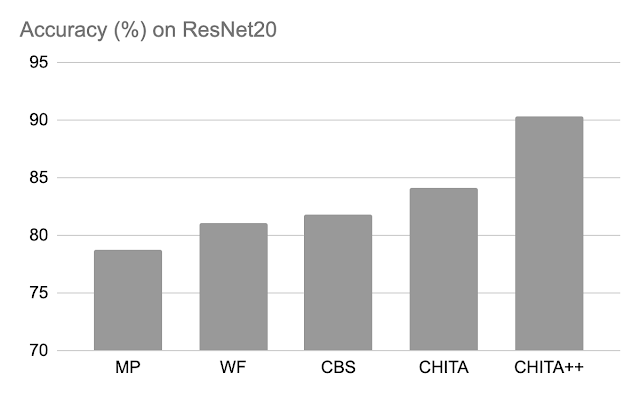 |
| ResNet20上各种方法的剪枝后准确性。结果是基于剪枝模型权重的70%。 |
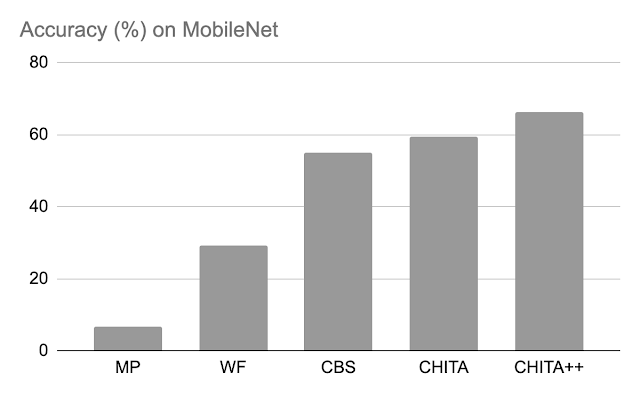 |
| MobileNet上各种方法的剪枝后准确性。结果是基于剪枝模型权重的70%。 |
接下来,我们报告了对一个更大的网络进行剪枝的结果:ResNet50(在这个网络上,一些在ResNet20图中列出的方法无法扩展)。在这里,我们与幅度剪枝和M-FAC进行了比较。下面的图表显示,CHITA在广泛的稀疏度范围内实现了更好的测试准确性。
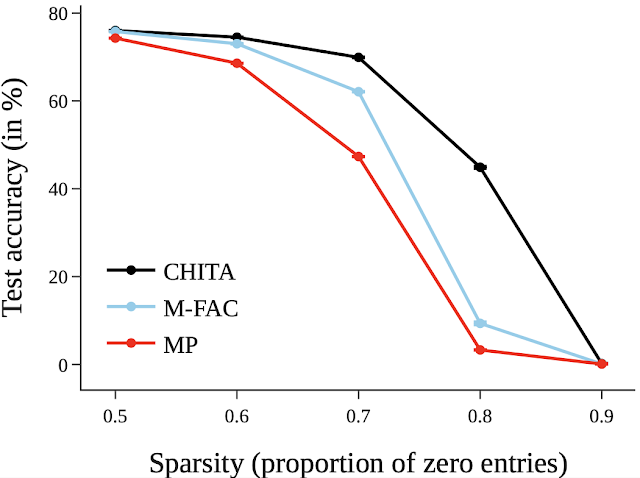 |
| 使用不同方法获得的剪枝网络的测试准确性。 |
结论、限制和未来工作
我们提出了CHITA,一种基于优化的方法,用于修剪预训练神经网络。CHITA通过高效利用二阶信息和借鉴组合优化和高维统计学的思想,提供了可扩展性和竞争性能。
CHITA专为非结构化修剪而设计,其中任何权重都可以被移除。理论上,非结构化修剪可以显著减少计算需求。然而,要在实践中实现这些减少,需要支持稀疏计算的特殊软件(可能还需要硬件)。相比之下,结构化修剪可以移除整个结构,如神经元,可能提供更容易在通用软件和硬件上实现的改进。将CHITA扩展到结构化修剪将是一个有趣的方向。
致谢
这项工作是Google和MIT之间的研究合作的一部分。感谢Rahul Mazumder、Natalia Ponomareva、Wenyu Chen、Xiang Meng、Zhe Zhao和Sergei Vassilvitskii在准备本文和论文方面的帮助。还要感谢John Guilyard在本文中创建的图形。