数据流中的矩阵近似
矩阵近似' in English is 'matrix approximation'.
近似矩阵而无需拥有其所有行
矩阵近似是数据挖掘和机器学习中一个广泛研究的子领域。许多数据分析任务依赖于获取矩阵的低秩近似。例如,降维、异常检测、数据去噪、聚类和推荐系统等。在本文中,我们将研究矩阵近似的问题,以及在没有完整数据的情况下如何计算它!
本文的内容部分来自我在斯坦福大学-CS246课程上的讲座。希望你觉得有用。请在这里找到完整的内容。
数据作为矩阵
大多数在网络上生成的数据可以表示为矩阵,其中矩阵的每一行都是一个数据点。例如,在路由器中,网络上发送的每个数据包都是一个数据点,可以表示为所有数据点的矩阵中的一行。在零售业中,每个购买行为都是所有交易的矩阵中的一行。

与此同时,几乎所有在网络上生成的数据都具有流式特性;这意味着数据由外部来源以高速率生成,我们无法控制。想象一下每秒钟用户在Google搜索引擎上进行的所有搜索。我们称此数据为流式数据,因为它像流水一样涌入。
一些典型的流式网络规模数据示例如下:
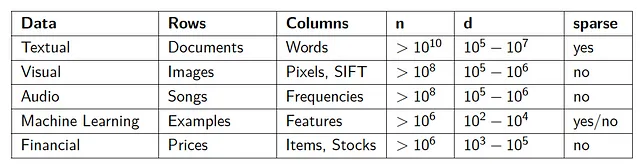
将流式数据视为包含n个行在d维空间中的矩阵A,其中通常有n >> d。通常n的数量级为十亿级别且不断增加。
数据流模型
在数据流模型中,数据以高速到达,每次只有一行,算法必须快速处理数据,否则数据将永远丢失。