相似度搜索,第6部分:使用LSH Forest进行随机投影
相似度搜索,第6部分:使用LSH Forest进行随机投影
理解如何通过构建随机超平面对数据进行哈希并反映其相似性
相似性搜索是一个问题,给定一个查询,目标是在所有数据库文档中找到与之最相似的文档。
介绍
在数据科学中,相似性搜索经常出现在NLP领域、搜索引擎或推荐系统中,需要检索与查询相关的最相关文档或项。在海量数据中提高搜索性能的方法有很多。
在上一部分中,我们看到了LSH的主要范式,即将输入向量转换为低维哈希值,同时保留有关它们相似性的信息。为了获得哈希值(签名),使用了minhash函数。在本文中,我们将随机投影输入数据以获得类似的二进制向量。
相似性搜索,第5部分:局部敏感哈希(LSH)
探索如何将相似性信息融入哈希函数
towardsdatascience.com
思路
考虑一个高维空间中的一组点。可以构造一个随机超平面作为墙壁,将每个点分为两个子群:正面和负面。正面的每个点被赋予“1”,负面的每个点被赋予“0”。
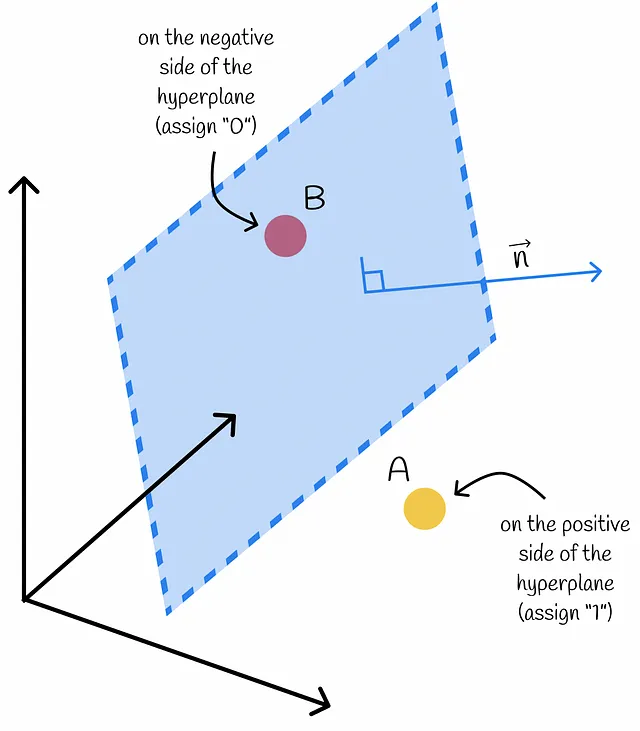
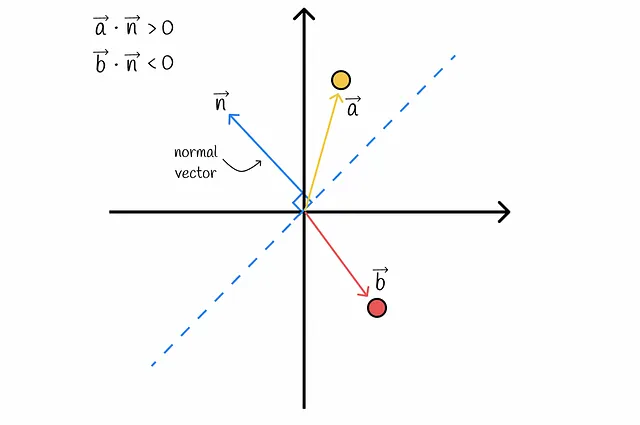
如何确定某个向量在超平面的哪一侧?通过使用内积!通过深入了解线性代数,可以确定给定向量与超平面的法向量之间的点积的符号,从而确定向量位于哪一侧。这样,可以将每个数据集向量分为两侧。
显然,用一个二进制值编码每个数据集向量是不够的。应该构造多个随机超平面,这样每个向量就可以根据其相对于特定超平面的位置使用多个0和1的值进行编码。如果两个向量具有完全相同的二进制编码,则表示没有任何构造的超平面可以将它们分隔到不同的区域。因此,它们在现实中可能非常接近。
要找到给定查询的最近邻居,只需以相同的方式使用0和1对查询进行编码,通过检查其相对于所有超平面的位置来完成。查询的找到的二进制向量可以与为数据集向量获得的所有其他二进制向量进行比较。可以通过使用汉明距离线性地完成这个过程。
汉明距离是两个向量在不同位置上取值不同的位置的数量。
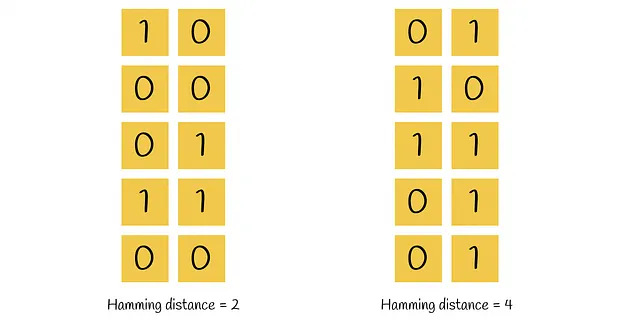
将与查询的汉明距离最小的二进制向量作为候选者,然后与初始查询进行全面比较。
为什么超平面是随机构建的?
在目前阶段,似乎有理由要求为什么超平面是以随机的方式构建的,而不是以确定性的方式,即可以定义用于分离数据集点的自定义规则。这背后有两个主要原因:
- 首先,确定性方法无法推广算法,并且可能导致过拟合。
- 其次,随机性允许对算法的性能进行概率性陈述,而这不依赖于输入数据。对于确定性方法,这是行不通的,因为它可能在一个数据上表现良好,而在另一个数据上性能较差。这类似于确定性快速排序算法,它在平均情况下以O(n * log n)的时间运行。然而,对于已排序的数组,它在O(n²)的时间内运行,这是最坏情况。如果有关算法工作流的知识,则可以始终提供最坏情况数据来明显破坏系统的效率。这就是为什么随机快速排序更受青睐。随机超平面也存在完全相同的情况。
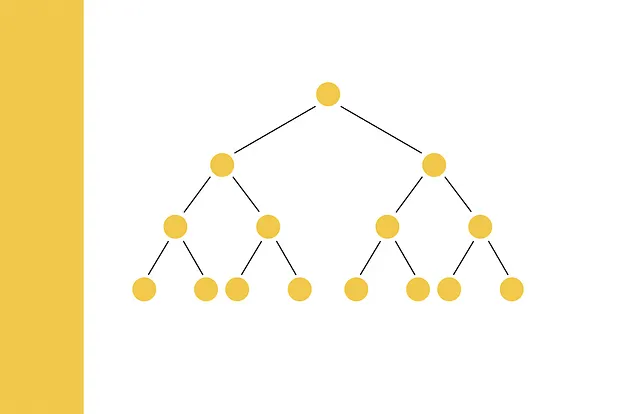
为什么LSH随机投影也被称为“树”?
随机投影方法有时被称为LSH树。这是因为哈希码分配的过程可以用决策树的形式表示,其中每个节点包含一个条件,即向量是否位于当前超平面的负面或正面。
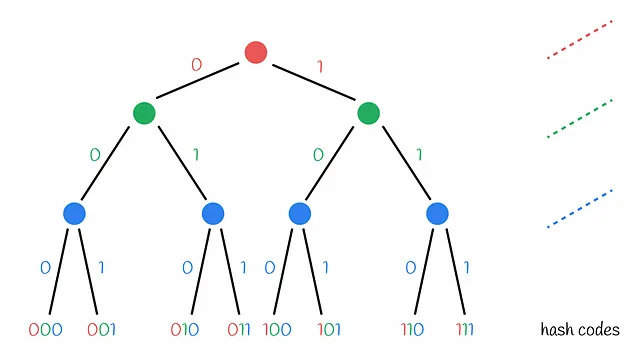
超平面森林
超平面是随机构建的。这可能导致它们无法很好地分离数据集点,如下图所示。
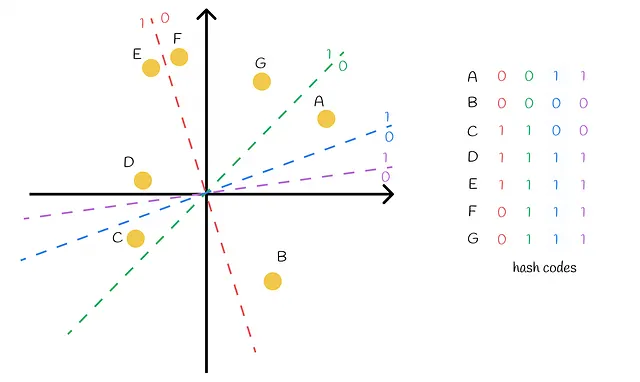
从技术上讲,当两个点具有相同的哈希码但彼此相距较远时,并不是个大问题。在算法的下一步中,这些点被作为候选者并进行全面比较,这样算法可以消除错误的正例。与假阴性情况相比,情况更加复杂:当两个点具有不同的哈希码,但实际上彼此接近。
为什么不使用经典机器学习中决策树的相同方法,将它们组合成随机森林以提高整体预测质量?如果一个估计器出现错误,其他估计器可以产生更好的预测,并减轻最终预测错误。使用这个想法,可以独立重复构建随机超平面的过程。生成的哈希值可以以与前一章中的最小哈希值类似的方式进行聚合,用于一对向量:
如果一个查询与另一个向量至少有一次相同的哈希码,则它们被认为是候选项。
使用这种机制可以减少误报的数量。
质量与速度的权衡
选择适当数量的超平面来对数据集进行划分很重要。选择更多的超平面来划分数据集点会减少碰撞次数,但计算哈希码和存储哈希码所需的时间和内存也会增加。确切地说,如果数据集由n个向量组成,我们通过k个超平面对其进行划分,那么平均而言,每个可能的哈希码将分配给n / 2ᵏ个向量。
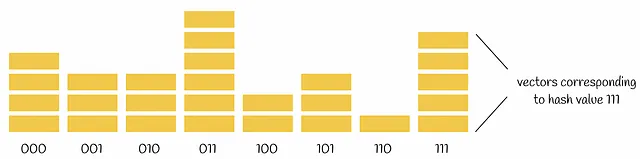
复杂度
训练
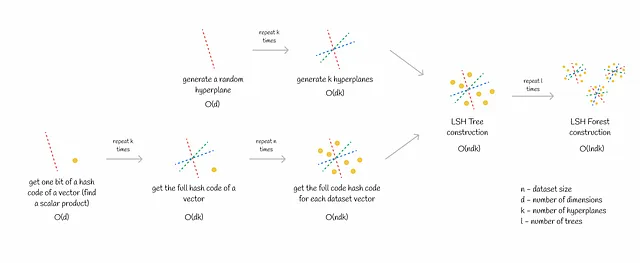
LSH Forest 的训练阶段包括两个部分:
- 生成k个超平面。这是一个相对快速的过程,因为在d维空间中生成一个超平面只需要O(d)的时间。
- 为所有数据集向量分配哈希码。这一步可能需要一些时间,尤其是对于大型数据集。获取一个哈希码需要O(dk)的时间。如果数据集由n个向量组成,则总的复杂度为O(ndk)。
上述过程会针对森林中的每棵树重复多次。
推断
LSH Forest 的一个优点是其快速的推断过程,包括两个步骤:
- 获取查询的哈希码。这等同于计算k个标量积,时间复杂度为O(dk)(d为维数)。
- 通过计算到候选项的精确距离,找到与查询最近的邻居。距离计算的复杂度为O(d)。每个桶平均包含n / 2ᵏ个向量。因此,对所有潜在候选项的距离计算需要O(dn / 2ᵏ)的时间。
总的复杂度为O(dk + dn / 2ᵏ)。
通常情况下,上述过程会针对森林中的每棵树重复多次。
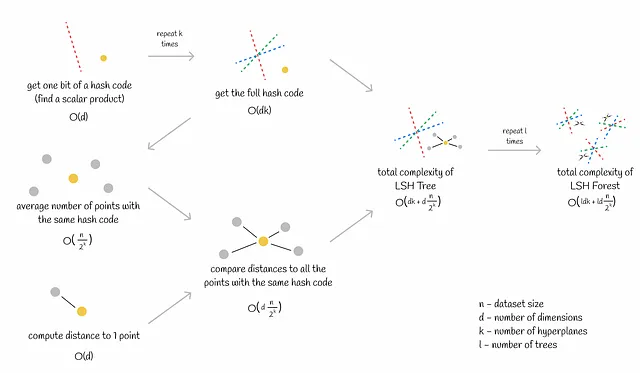
当选择的超平面数量k满足n ~ 2ᵏ(在大多数情况下是可能的)时,总的推断复杂度变为O(ldk)(其中l为树的数量)。基本上,这意味着计算时间不依赖于数据集的大小!这个细微之处使得相似性搜索在数百万甚至数十亿个向量上具有高效的可扩展性。
错误率
在关于LSH的前一部分文章中,我们讨论了基于签名相似性来计算两个向量被选为候选项的概率。在这里,我们将使用几乎相同的逻辑来找到LSH Forest的公式。
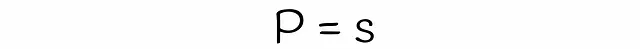

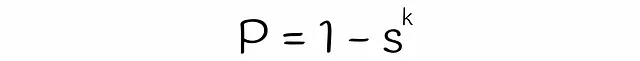
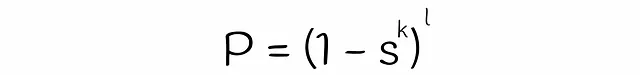
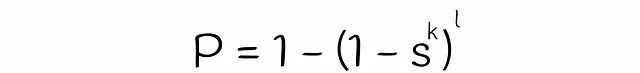
到目前为止,我们几乎获得了估计两个向量成为候选向量的概率的公式。唯一剩下的就是估计方程中变量s的值。在经典的LSH算法中,s等于两个向量的Jaccard指数或签名相似度。另一方面,为了估计LSH森林的s,将使用线性代数理论。
坦率地说,s是两个向量a和b具有相同位的概率。这个概率等于随机超平面将这些向量分隔到同一侧的概率。让我们进行可视化:
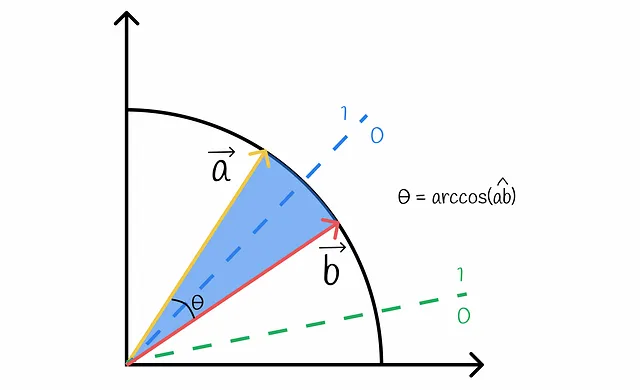
从图中可以看出,超平面只有在穿过向量a和b之间时才将它们分隔到不同的一侧。这种概率q与向量之间的角度成比例,可以很容易地计算:
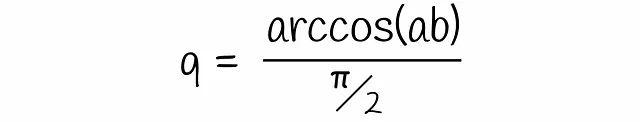
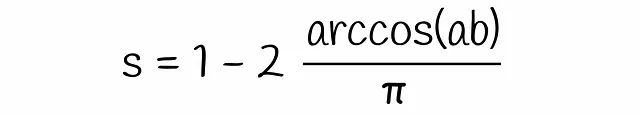
将这个方程代入先前得到的方程得到最终的公式:

可视化
利用最后得到的公式,让我们根据它们的余弦相似度可视化两个向量成为候选向量的概率,对于不同数量的超平面k和树l。

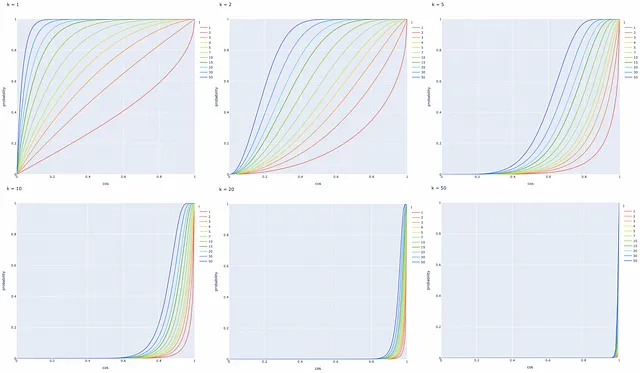
基于绘图,可以得出一些有用的观察结果:
- 余弦相似度为1的向量对总是成为候选项。
- 余弦相似度为0的向量对永远不会成为候选项。
- 当超平面数量k减少或LSH树数量l增加时,两个向量成为候选项的概率P增加(即更多的假阳性)。反之亦然。
总结一下,LSH是一个非常灵活的算法:可以根据给定的问题调整不同的k和l值,并获得满足问题要求的概率曲线。
示例
让我们看一个例子。假设构建了l = 5棵树,每棵树有k = 10个超平面。除此之外,还有两个余弦相似度为0.8的向量。在大多数系统中,这样的余弦相似度表示向量确实非常接近。根据前几节的结果,结果表明这个概率只有2.5%!显然,对于如此高的余弦相似度来说,这是一个非常低的结果。使用l = 5和k = 10的参数会导致大量的假阴性!下面的绿线表示这种情况下的概率。
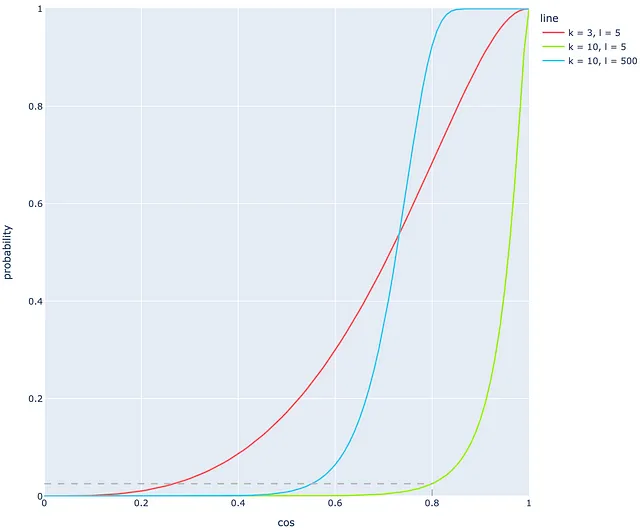
通过调整k和l的更好值来解决这个问题,将曲线向左移动。
例如,如果将k减少到3(红线),那么余弦相似度为0.8的相同值将对应于68%的概率,比之前好。乍一看,红线似乎比绿线更适合,但重要的是要记住,使用较小的k值(如红线的情况)会导致大量的碰撞。因此,有时最好调整第二个参数,即树的数量l。
与k不同,通常需要非常高数量的树l才能获得类似的线形。在图中,蓝线是通过将l的值从10更改为500而获得的。蓝线明显比绿线更适合,但仍然远非完美:由于余弦相似度值在0.6和0.8之间的高斜率,概率在余弦相似度为0.3-0.5附近几乎等于0,这是不利的。在现实生活中,文档相似度为0.3-0.5的小概率通常应该更高。
基于最后一个例子,很明显,即使使用非常高数量的树(需要大量计算),仍然会导致许多假阴性!这是随机投影方法的主要缺点:
虽然理论上可能得到完美的概率曲线,但要么需要大量计算,要么会导致大量碰撞。否则,会导致高假阴性率。
Faiss实现
Faiss(Facebook AI搜索相似度)是一个用于优化相似度搜索的用C++编写的Python库。该库提供了不同类型的索引,用于高效地存储数据和执行查询。
根据Faiss文档中的信息,我们将了解如何构建LSH索引。
随机投影算法在Faiss中的实现位于IndexLSH类内。尽管Faiss的作者使用了一种稍微不同的技术,称为“随机旋转”,但它与本文中描述的方法仍然有相似之处。该类仅实现了单个LSH树。如果我们想使用LSH森林,只需创建多个LSH树并聚合它们的结果。
IndexLSH类的构造函数接受两个参数:
- d: 维度的数量
- nbits: 编码单个向量所需的位数(可能的桶的数量等于2ⁿᵇᶦᵗˢ)
search() 方法返回的距离是与查询向量的汉明距离。
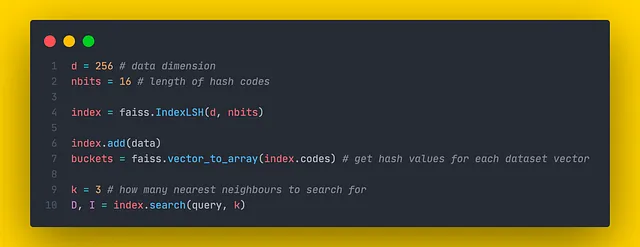
此外,通过调用 faiss.vector_to_array(index.codes) 方法,Faiss 允许检查每个数据集向量的编码哈希值。
由于每个数据集向量都由 nbits 个二进制值编码,因此存储单个向量所需的字节数等于:
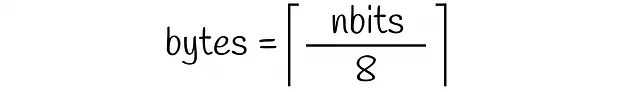
Johnson-Lindenstrauss引理
Johnson-Lindenstrauss引理是与降维相关的极好的引理。虽然可能很难完全理解其原始陈述,但可以用简单的话来表述:
选择一个随机子集并将原始数据投影到它上面,可以保持点之间的对应距离。
更精确地说,对于一个包含n个点的数据集,可以以O(logn)维的新空间表示它们,以便点之间的相对距离几乎保持不变。如果向量在LSH方法中由~logn个二进制值编码,则可以应用该引理。此外,LSH以与引理要求的方式随机创建超平面。
Johnson-Lindenstrauss引理的另一个令人难以置信之处是,新数据集的维度数量不取决于原始数据集的维度!在实践中,该引理对于非常小的维度效果不好。
结论
我们已经学习了一种强大的相似性搜索算法。它基于通过随机超平面将点分开的简单思想,在大型数据集上通常表现出良好的性能和扩展性。此外,它通过允许选择适当数量的超平面和树提供了很好的灵活性。
来自Johnson-Lindenstrauss引理的理论结果加强了随机投影方法的使用。
资源
- LSH Forest: 自适应索引用于相似性搜索
- Johnson-Lindenstrauss引理
- Faiss文档
- Faiss代码库
- Faiss索引摘要
所有图像(除非另有说明)均由作者提供。






