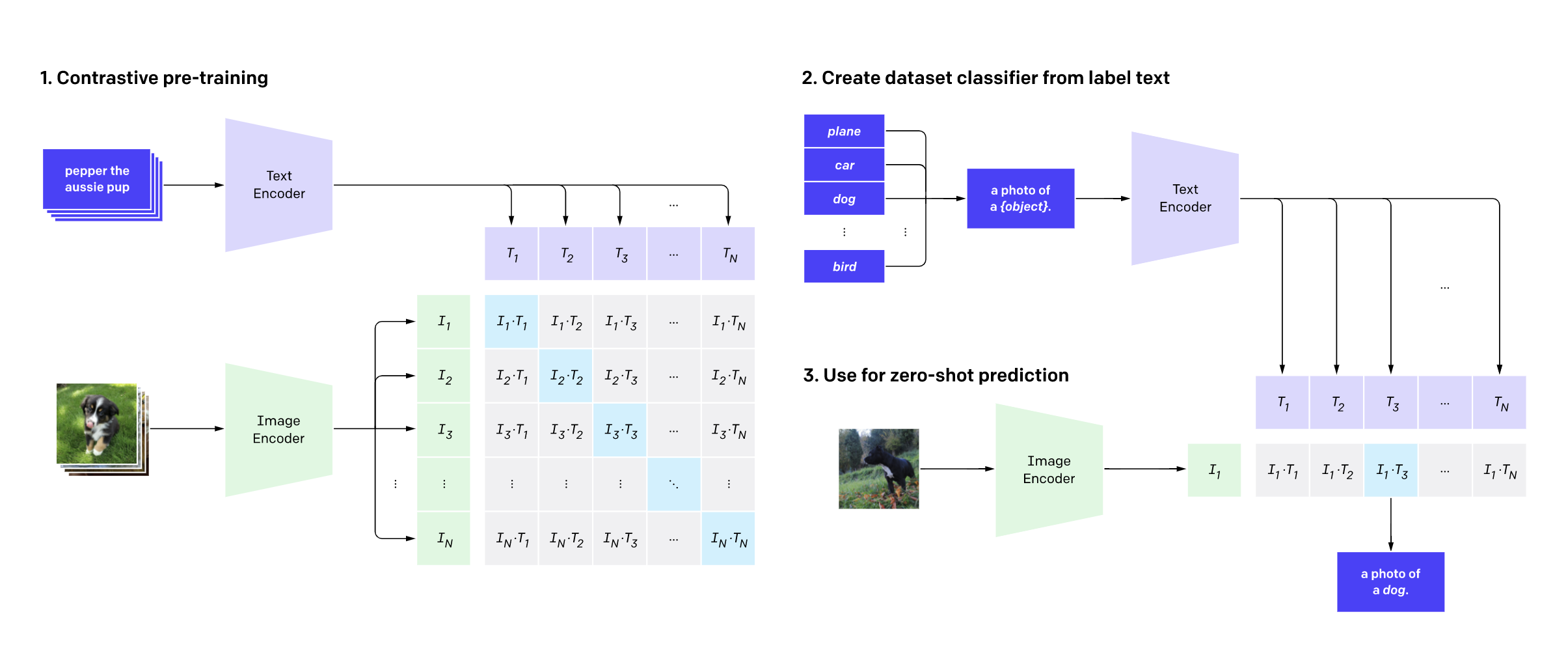
深度学习在互联网上:协作训练语言模型
深度学习:互联网上的协作训练语言模型
在Quentin Lhoest和Sylvain Lesage的额外帮助下。
现代语言模型通常需要大量计算资源进行预训练,没有数十个甚至数百个GPU或TPU的支持,很难获得这些模型。尽管理论上可能可以结合多个个人的资源,但实际上,因特网的连接速度远远慢于高性能GPU超级计算机,因此此前这样的分布式训练方法的成功案例非常有限。
在本博客中,我们介绍了一种名为DeDLOC的新的协作分布式训练方法,它可以适应参与者的网络和硬件限制。我们通过与40名志愿者一起预训练孟加拉语模型sahajBERT,展示了它在实际场景中的成功应用。在孟加拉语的下游任务中,该模型的质量接近于最先进的水平,并且与使用数百个高级加速器的更大模型相当。
开放协作中的分布式深度学习
我们为什么要这样做?
如今,许多高质量的自然语言处理系统都基于大型预训练的Transformer模型。一般而言,模型的质量随着规模的增加而提高:通过增加参数数量和利用大量未标记的文本数据,可以在自然语言理解和生成方面取得无与伦比的结果。
- 介绍 Optimum:大规模变压器的优化工具包
- Hugging Face 和 Graphcore 合作,为 IPU 优化的 Transformer 提供支持
- 使用Streamlit在Hugging Face Spaces上托管您的模型和数据集
不幸的是,我们使用这些预训练模型不仅仅是因为它方便。对于在大型数据集上训练Transformer模型所需的硬件资源,往往超出了单个个人甚至大多数商业或研究机构的承受范围。以BERT为例,其训练成本估计约为7000美元,对于像GPT-3这样的最大模型,这个数字可能高达1200万美元!这种资源限制似乎是显而易见和不可避免的,但在更广泛的机器学习社区中,难道真的没有使用预训练模型的替代方案吗?
然而,也许我们已经有了解决这个问题的方法,我们只需要四处寻找。可能情况是,我们正在寻找的计算资源已经存在;例如,我们中的许多人在家里拥有强大的计算机,配备了游戏或工作站级别的GPU。你可能已经猜到我们将要做的是类似于Folding@home、Rosetta@home、Leela Chess Zero或不同的BOINC项目,利用志愿计算的方法来共享计算资源,但这种方法更加普遍。例如,几个实验室可以将它们的小型集群联合起来利用所有可用的资源,一些人可能希望使用廉价的云实例加入实验。
对于怀疑的人来说,可能会觉得我们在这里缺少一个关键因素:分布式深度学习中的数据传输通常是一个瓶颈,因为我们需要从多个工作节点收集梯度。确实,任何在因特网上进行分布式训练的天真方法都注定会失败,因为大多数参与者没有千兆位的连接,并且可能随时从网络中断开。那么你如何通过家庭数据计划来训练任何东西呢? 🙂
作为解决这个问题的方法,我们提出了一种名为开放协作中的分布式深度学习(或DeDLOC)的新训练算法,该算法在我们最近发布的预印本中有详细描述。现在,让我们来了解一下这个算法背后的核心思想!
与志愿者一起训练
在最常用的多GPU分布式训练版本中,非常简单。回想一下,当进行深度学习时,通常会计算在训练数据的批次中许多示例的损失函数的梯度的平均值。在数据并行的分布式深度学习中,您只需将数据分配给多个工作节点,分别计算梯度,然后在处理完本地批次后将它们平均。当在所有工作节点上计算出平均梯度后,我们使用优化器调整模型权重并继续训练模型。您可以在下面的插图中看到执行的不同任务的示例。

通常,为了减少同步的数量并稳定学习过程,我们可以在平均之前累积N个批次的梯度,这等效于将实际批次大小增加N倍。这种方法与大多数最先进的语言模型使用大批次的观察相结合,使我们产生了一个简单的想法:在每个优化器步骤之前,让我们在所有志愿者设备上累积一个非常大的批次!除了与常规分布式训练完全等效和易于扩展性之外,这种方法还具有内置的容错性,我们在下面进行了说明。
让我们考虑一些我们可能在协作实验中遇到的潜在故障情况。迄今为止,最常见的情况是一个或多个参与者断开了训练过程:他们的连接可能不稳定,或者他们只是想将他们的GPU用于其他用途。在这种情况下,我们只会遭受训练的小挫折:这些参与者的贡献将从当前累积的批次大小中扣除,但其他参与者会用他们的梯度进行补偿。此外,如果更多的参与者加入,目标批次大小将更快地达到,并且我们的训练过程将自然加速。您可以在视频中看到这个示例:
自适应平均
现在我们已经讨论了整个训练过程,还有一个问题需要解决:我们如何实际聚合参与者的梯度?大多数家用计算机很难接受传入连接,并且下载速度也可能成为限制因素。
由于我们依赖志愿者的硬件进行实验,中央服务器并不是一个可行的选择,因为当扩展到数十个客户端和数亿个参数时,它将很快面临过载。今天大多数数据并行训练运行并不使用这种策略;相反,它们依赖于全局归约——一种高效的全对全通信原语。凭借巧妙的算法优化,每个节点都可以计算全局平均值,而无需将整个本地梯度发送给每个对等节点。
由于全局归约是分散的,似乎是个不错的选择;然而,我们仍然需要考虑硬件和网络设置的多样性。例如,一些志愿者可能使用具有较慢网络但功能强大的GPU的计算机加入,一些人可能只与其他对等节点的子集有更好的连接性,而另一些人可能无法接受传入连接。
事实证明,我们可以通过利用性能的信息来实时制定最优的数据传输策略!在高层次上,我们根据每个对等节点的互联网速度将整个梯度向量分成多个部分:具有最快连接的节点聚合最大的部分。此外,如果某些节点不接受传入连接,它们只需将其数据发送到聚合中,而不计算平均值。根据条件,这种自适应算法可以恢复出众所周知的分布式深度学习算法,并通过混合策略改进它们,如下所示。

sahajBERT
正如往常一样,拥有一个设计良好的算法框架并不意味着它在实践中能按预期工作,因为某些假设在实际训练中可能不成立。为了验证这项技术的竞争性能并展示其潜力,我们组织了一个特殊的合作活动,为孟加拉语预训练了一个掩码语言模型。尽管孟加拉语是世界上使用最为广泛的第五大母语,但公开可用的掩码语言模型却很少,这突显了能够赋予社区力量的工具的重要性,为该领域带来了大量机会。
我们通过Neuropark社区的真实志愿者进行了这个实验,并使用了公开可用的数据集(OSCAR和维基百科),因为我们希望有一个完全可重现的示例,可以为其他团体提供灵感。下面,我们描述了我们训练运行的详细设置,并展示了其结果。
架构
对于我们的实验,我们选择了ALBERT(A Lite BERT)——一种用于语言表示的模型,它以掩码语言建模(MLM)和句子顺序预测(SOP)作为目标进行预训练。我们选择这个架构是因为权重共享使其非常高效:例如,ALBERT-large只有大约1800万个可训练参数,在GLUE基准测试中性能与拥有大约1.08亿个权重的BERT-base相当。这意味着在我们的设置中,需要在对等节点之间交换的数据较少,这对于加快每次训练迭代的速度非常重要。
分词器
我们模型的第一个组件称为分词器,它负责将原始文本转换为词汇索引。由于我们正在为孟加拉语训练模型,该语言与英语并不非常相似,因此我们需要将语言特定的预处理作为分词器的一部分实现。我们可以将其视为以下操作序列:
- 规范化:包括对原始文本数据的所有预处理操作。这一步骤是我们进行了最多更改的步骤,因为删除某些细节可能会改变文本的含义,也可能会保持不变,这取决于语言。例如,标准的ALBERT规范化器会删除重音符号,而对于孟加拉语,我们需要保留它们,因为它们包含有关元音的信息。因此,我们使用以下操作:NMT规范化,NFKC规范化,删除多个空格,同化孟加拉语中重复的Unicode字符,并进行小写处理。
- 预分词:描述了将输入(例如按空格)拆分成特定标记边界的规则。与原始工作一样,我们选择将空格排除在标记之外。因此,为了区分单词之间的词和避免出现多个单空格标记,每个对应于单词开头的标记以特殊字符“_”(U+2581)开头。此外,我们将所有标点符号和数字与其他字符分离,以压缩词汇表。
- 分词器建模:在这个级别上,文本被映射为词汇序列。有几种算法可以实现这一点,例如字节对编码(BPE)或Unigram,其中大多数算法需要从文本语料库中构建词汇表。按照ALBERT的设置,我们使用了Unigram语言模型方法,在OSCAR数据集的孟加拉语部分进行了32k个标记的词汇表的训练。
- 后处理:在分词之后,我们可能希望添加一些架构所需的特殊标记,例如以特殊标记
[CLS]开始序列或以特殊标记[SEP]分隔两个片段。由于我们的主要架构与原始ALBERT相同,我们保持相同的后处理:具体而言,我们在每个示例的开头添加一个[CLS]标记,并在两个片段之间以及末尾添加一个[SEP]标记。
你可以通过运行以下代码来重复使用我们的分词器:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("neuropark/sahajBERT")数据集
我们需要解决的最后一件事是训练数据集。正如你可能知道的,BERT或ALBERT等预训练模型的巨大优势在于你不需要一个已注释的数据集,只需要大量的文本。为了训练sahajBERT,我们使用了2021年3月20日的孟加拉维基百科转储文件以及OSCAR的孟加拉子集(600MB + 6GB的文本)。这两个数据集可以从HF Hub轻松下载。
然而,加载整个数据集需要时间和存储空间,这些是我们的同行可能没有的资源。为了充分利用参与者提供的资源,我们实现了数据集流式处理,这使得他们可以几乎在加入网络后立即训练模型。具体而言,数据集中的示例是并行下载和转换的。我们还可以对数据集进行洗牌,这样我们的同行在同一时间处理相同的示例的机会很小。由于数据集不是提前下载和预处理的,从纯文本到训练示例所需的转换(如下图所示)是即时完成的。

数据集流式处理模式在🤗数据集库的v1.9版本中可用,因此你可以立即使用它,如下所示:
from datasets import load_dataset
oscar_dataset = load_dataset("oscar", name="unshuffled_deduplicated_bn", streaming=True)协作活动
sahajBERT协作训练活动于5月12日至5月21日举行。该活动汇集了40名参与者,其中30名是孟加拉语言的志愿者,另外10名是作者组织的志愿者。这40名志愿者加入了Neuropark Discord频道,以接收与活动相关的所有信息并参与讨论。为了加入实验,志愿者需要:
- 将他们的用户名发送给管理员进行白名单管理;
- 在本地、Google Colaboratory或Kaggle上打开提供的笔记本;
- 运行一个代码单元并在请求时填写他们的Hugging Face凭据;
- 在共享的仪表板上观察训练损失的下降!
出于安全考虑,我们建立了一个授权系统,只有Neuropark社区的成员才能训练模型。为了避免过多技术细节,我们的授权协议允许我们确保每个参与者都在白名单内,并承认每个同行的个体贡献。
在下图中,你可以看到每个志愿者的活动情况。在实验过程中,志愿者共登录了600个不同的会话。参与者经常同时启动多个运行,并且许多人将他们启动的运行时间分散在不同的时间段。个别参与者的运行时间平均为4小时,最长达到21小时。你可以在论文中了解更多有关参与统计的信息。
除了参与者提供的资源,我们还使用了16个抢占式(价格便宜但经常中断)单GPU T4云实例来确保运行的稳定性。实验的累计运行时间为234天,在下图中你可以看到每个同行贡献的损失曲线的部分!
最终模型已上传到模型中心,所以如果你想的话可以下载并使用它:https://hf.co/neuropark/sahajBERT
评估
为了评估sahajBERT的性能,我们在孟加拉语中对其进行了两个下游任务的微调:
- 在WikiANN的孟加拉语部分上进行命名实体识别(NER)任务。该任务的目标是将输入文本中的每个标记分类为以下类别之一:人物、组织、地点或无。
- 在来自IndicGLUE的Soham文章数据集上进行新闻类别分类(NCC)任务。该任务的目标是预测输入文本所属的类别。
我们在NER任务的训练过程中进行了评估,以确保一切顺利;正如你在下图中所看到的,情况确实如此!
在训练结束时,我们将sahajBERT与其他三个预训练语言模型进行了比较:XLM-R Large、IndicBert和bnRoBERTa。在下表中,你可以看到我们的模型与HF Hub上可用的最佳孟加拉语语言模型的结果相当,尽管我们的模型仅有约1800万个训练参数,而例如XLM-R(一个强大的多语言基准模型)有近5.59亿个参数,并在数百个V100 GPU上进行训练。
这些模型也可以在Hub上找到。您可以通过在模型卡上玩Hosted Inference API小部件或直接在Python代码中加载它们来直接测试它们。
sahajBERT-NER
模型卡片:https://hf.co/neuropark/sahajBERT-NER
from transformers import (
AlbertForTokenClassification,
TokenClassificationPipeline,
PreTrainedTokenizerFast,
)
# 初始化tokenizer
tokenizer = PreTrainedTokenizerFast.from_pretrained("neuropark/sahajBERT-NER")
# 初始化model
model = AlbertForTokenClassification.from_pretrained("neuropark/sahajBERT-NER")
# 初始化pipeline
pipeline = TokenClassificationPipeline(tokenizer=tokenizer, model=model)
raw_text = "এই ইউনিয়নে ৩ টি মৌজা ও ১০ টি গ্রাম আছে ।" # 更改我
output = pipeline(raw_text)sahajBERT-NCC
模型卡片:https://hf.co/neuropark/sahajBERT-NER
from transformers import (
AlbertForSequenceClassification,
TextClassificationPipeline,
PreTrainedTokenizerFast,
)
# 初始化tokenizer
tokenizer = PreTrainedTokenizerFast.from_pretrained("neuropark/sahajBERT-NCC")
# 初始化model
model = AlbertForSequenceClassification.from_pretrained("neuropark/sahajBERT-NCC")
# 初始化pipeline
pipeline = TextClassificationPipeline(tokenizer=tokenizer, model=model)
raw_text = "এই ইউনিয়নে ৩ টি মৌজা ও ১০ টি গ্রাম আছে ।" # 更改我
output = pipeline(raw_text)结论
在这篇博文中,我们讨论了一种方法,可以将sahajBERT作为第一个真正成功应用于实际问题的协作预训练神经网络的方法。
这对整个机器学习社区意味着什么?首先,现在可以与朋友一起运行大规模分布式预训练,我们希望能看到许多以前不太容易获得的酷炫新模型。此外,我们的结果对于多语言自然语言处理可能很重要,因为现在任何语言的社区都可以训练自己的模型,而不需要将大量计算资源集中在一个地方。
致谢
DeDLOC论文和sahajBERT训练实验由Michael Diskin、Alexey Bukhtiyarov、Max Ryabinin、Lucile Saulnier、Quentin Lhoest、Anton Sinitsin、Dmitry Popov、Dmitry Pyrkin、Maxim Kashirin、Alexander Borzunov、Albert Villanova del Moral、Denis Mazur、Ilia Kobelev、Yacine Jernite、Thomas Wolf和Gennady Pekhimenko创建。该项目是Hugging Face、Yandex Research、HSE University、MIPT、University of Toronto和Vector Institute的合作结果。
此外,我们还要感谢Stas Bekman、Dmitry Abulkhanov、Roman Zhytar、Alexander Ploshkin、Vsevolod Plokhotnyuk和Roman Kail在构建训练基础设施方面的宝贵帮助。此外,我们还要感谢Abhishek Thakur对下游评估的帮助,以及Tanmoy Sarkar和Omar Sanseviero的帮助,他们帮助我们组织了协作实验,并定期向参与者报告了训练过程中的进展情况。
下面,您可以看到协作实验的所有参与者:
参考文献
“Distributed Deep Learning in Open Collaborations”,ArXiv
在DeDLOC存储库中的sahajBERT实验的代码。