在一堆干草中找到针 — 用于Jaccard相似度的搜索索引
搜索索引中的Jaccard相似度算法
从基本概念到精确和近似索引

向量数据库因为成为大型语言模型(LLMs)的外部存储器而备受关注。这些向量数据库是建立在十几年前被称为近似最近邻(ANN)索引的研究基础上的新系统。这些索引算法接收许多高维向量(例如float32[]),并构建一个支持在高维空间中找到查询向量的近似邻居的数据结构。就像Google地图根据您的房屋纬度和经度找到邻居的房屋一样,只不过近似最近邻(ANN)索引在更高的维度空间中操作。
这个研究领域的历史可以追溯到几十年前。在90年代末,机器学习研究人员正在为图像和音频等多媒体数据手工制作数值特征。基于这些特征向量的相似度搜索成为一个自然的问题。有一段时间,研究人员在这个领域云集。直到一篇开创性的论文《何时“最近邻”有意义?》出现,基本上告诉大家不要再浪费时间,因为在手工制作特征的高维空间中,最近邻大多数情况下都没有意义——这是另一个帖子的有趣话题。直到今天,我仍然看到研究论文和向量数据库基准测试在SIFT-128数据集上发布性能数据,该数据集包含的正是没有意义的手工制作特征向量。
尽管手工制作特征引起了许多噪音,但已经有一条富有成果的研究线路专注于具有有意义相似度的一种高维数据类型:集合和Jaccard相似度。
在本文中,我将介绍用于集合的Jaccard相似度的搜索索引。我将从基本概念开始,然后转向精确和近似索引。
集合和Jaccard
集合就是一组不同的元素。您在Spotify上喜欢的歌曲是一个集合;您上周转发的推文是一个集合;从这篇博客文章中提取的不同标记也形成一个集合。集合是在音乐推荐、社交网络和抄袭检测等应用场景中表示数据点的一种自然方式。
假设在Spotify上,我关注这些艺术家:
[the weekend, taylor swift, wasia project]
而我的女儿关注这些艺术家:
[the weekend, miley cyrus, sza]
衡量我们音乐口味的相似度的一种合理方法是看我们两个都关注了多少位艺术家——即交集的大小。在这种情况下,我们两个都关注了the weekend,所以交集的大小为1。
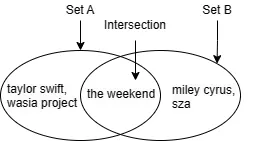
然而,您可以想象另一对用户每个人都关注了100位艺术家,交集大小也是1,但他们的口味相似度应该远远小于我女儿和我的相似度。为了使不同用户对之间的测量可比较,我们用并集大小对交集大小进行归一化。这样,我女儿和我关注的相似度为1 / 5 = 0.2,而另一对用户关注的相似度为1 / 199 ~= 0.005。这就是所谓的Jaccard相似度。
对于集合A和集合B,Jaccard相似度的公式如下:
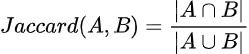
为什么要设定高维数据类型?一个集合可以被编码为“one-hot”向量,其中的维度一一对应于所有可能的元素(例如,Spotify上的所有艺术家)。向量中的一个维度如果集合包含与该维度对应的元素,则其值为1,否则为0。因此,我的关注艺术家的向量化集合如下所示:
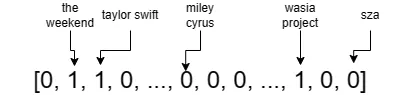
其中,第二、第三和倒数第三个维度分别是the weekend,taylor swift和wasia project。Spotify上有超过1000万位艺术家,因此这样的向量是非常高维且非常稀疏的——大多数维度都是0。
Jaccard搜索的倒排索引
人们希望快速找到东西,因此计算机科学家发明了一种称为索引的数据结构,以使软件应用程序的搜索性能满意。具体而言,Jaccard搜索索引是建立在一组集合上的,给定一个查询集合,它返回与查询集合具有最高Jaccard相似度的k个集合。
Jaccard的搜索索引是基于一种称为倒排索引的数据结构的。倒排索引具有非常简单的接口:输入一个集合元素,比如the weekend,它返回包含该输入元素的集合的ID列表,例如[ 32, 231, 432, 1322, ...]。倒排索引本质上是一个查找表,其键是所有可能的集合元素,值是集合ID的列表。在这个例子中,倒排索引中的每个列表都表示一个艺术家的关注者的ID。
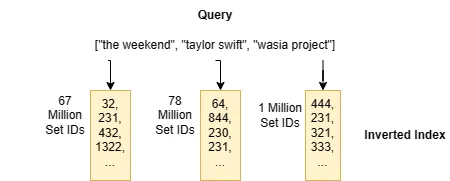

你可以看到为什么这被称为“倒排索引”:它允许你通过一个集合元素找到包含该元素的集合。
精确搜索算法
倒排索引是加速搜索的非常强大的数据结构。使用倒排索引,当进行搜索时,不需要遍历所有的集合并将每个集合与查询集合进行比较——如果你有数百万个集合,这将非常昂贵,你只需要处理与查询集合至少有一个元素相同的集合的ID。你可以直接从倒排索引列表中获取集合ID。
以下是实现这个搜索算法的方法:
def search_top_k_merge_list(index, sets, q, k): """使用倒排索引搜索top-k Jaccard。 参数: index: 倒排索引,键是集合元素 sets: 集合的查找表,键是集合ID q: 查询集合 k: 搜索参数k 返回值: list: 最多k个集合ID。 """ # 初始化一个空的候选人查找表。 candidates = defaultdict(0) # 遍历查询集合中的元素。 for x in q: ids = index[x] # 从索引中获取集合ID的列表。 for id in ids: candidates[id] += 1 # 增加交集大小的计数。 # 现在candidates[id]存储了ID为id的集合的交集大小。 # 一个简单的根据交集大小和集合大小计算Jaccard的例程,基于包含-排除原理。 jaccard = lambda id: candidates[id] / (len(q) + len(sets(id) - candidates[id])) # 按照Jaccard的顺序找到top-k候选人。 return sorted(list(candidates.keys()), key=jaccard, reverse=True)[:k]以简单的英语来说,该算法通过遍历与查询集中的元素匹配的每个倒排索引列表,并使用候选表来跟踪每个集合ID出现的次数。如果一个集合ID出现了n次,索引集合与查询集合有n个重叠元素。最后,算法使用候选表中的所有信息来计算Jaccard相似性,然后返回最相似集合的ID。
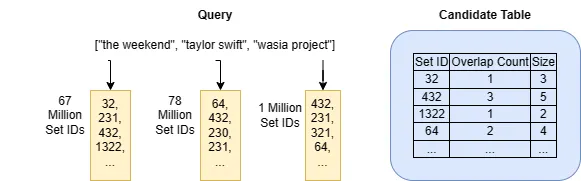
当查询集中的元素数量较小并且查询元素的倒排索引列表中的ID数量较小时,search_top_k_merge_list算法可以快速运行。在Spotify的场景中,如果大多数人关注少数几位艺术家(可能是真实情况),并且所有艺术家的关注者数量大致相同(不是真实情况),那么这种情况可能会发生。我们都知道,事实上,少数顶级艺术家被大多数人关注,而大多数艺术家的关注者很少。毕竟,音乐行业遵循帕累托分布。
泰勒·斯威夫特在Spotify上有7800万粉丝,The Weekend有6700万粉丝。如果我关注他们,search_top_k_merge_list算法将需要遍历至少1.45亿个集合ID,并且候选表candidates将增长到这个庞大的大小。尽管如今的计算机速度快且强大,在我的Intel i7机器上,创建这么大的表仍然需要至少30秒(Python),并且动态分配2.5 GB的内存。
大多数人关注这些超级明星艺术家。因此,如果您在搜索应用程序中使用此算法,您肯定会因为大量资源使用而得到巨大的云托管账单,并且搜索延迟会导致糟糕的用户体验。
分支界限优化
直观地讲,前面的算法search_top_k_merge_list以广度优先的方式处理所有潜在候选者,因为它仅使用倒排索引来计算交集。由于有数百万关注者的超级明星艺术家,该算法的性能较差。
另一种方法是对潜在候选者进行更加有选择性的处理。想象一下,您作为招聘经理面试候选人。您不能够面试所有给您发送简历的潜在候选人,因此您根据工作标准将候选人分成不同桶,并开始面试符合您最关心的标准的候选人。在逐个面试他们时,您评估每个候选人是否实际符合您的所有或大部分标准,并在找到合适的候选人后停止面试。
当寻找类似的关注艺术家集合时,这种方法也适用。关键思想是您希望从查询集中关注者最少的艺术家开始。为什么?简单地说,这些艺术家给您提供了较少的候选集合,因此您可以处理较少的来自倒排索引的艺术家列表,并更快地找到最佳的k个候选人。在我的Spotify关注列表中,wasian project只有100万粉丝,远少于泰勒·斯威夫特。那些关注wasian project的人数比关注泰勒·斯威夫特的人数少得多,但是他们与最佳的k个候选人有着相同的潜力。
这里的关键洞察是我们不想处理所有潜在的候选者列表,而是在处理足够多的候选者列表后停止。难点在于知道何时停止。下面是一个实现了这个思想的前一个算法的修改版本。
import heapqdef search_top_k_probe_set(index, sets, q, k): # 初始化一个优先级队列来存储当前的最佳k个候选者。 heap = [] # 初始化一个集合用于跟踪已探测的候选者。 seen_ids = set() # 根据倒排索引中列表的长度,从最少到最多的频率迭代查询集中的元素。 for i, x in enumerate(sorted(q, key=lambda x: len(index[x]))): ids = index[x] # 从索引中获取一个集合ID列表。 for id in ids: if id in seen_ids: continue # 跳过已探测到的候选者。 s = sets[id] intersect_size = len(q.intersection(s)) jaccard = intersect_size / (len(q) + len(s) - intersect_size) # 将候选者添加到优先级队列中。 if len(heap) < k: heapq.heappush(heap, (jaccard, id)) else: # 只有Jaccard比当前第k个候选者更高的候选者 # 才会在此操作中被添加。 heapq.heappushpop(heap, (jaccard, id)) seen_ids.add(id) # 如果任何来自剩余列表的新候选者都无法比当前最佳k个候选者中的任何一个具有更高的Jaccard相似性,我们就不需要再做任何工作了。 if (len(q) - i - 1) / len(q) (<= min(heap)[0]: break # 返回最佳的k个候选者。 return [id for _, id in heapq.nlargest(k, heap)]搜索顶部k探测集算法对找到的每个新候选项计算Jaccard相似度。它始终跟踪当前最佳的k个候选项,并在任何新候选项的上界Jaccard不大于当前最佳的k个候选项的最小Jaccard时停止。
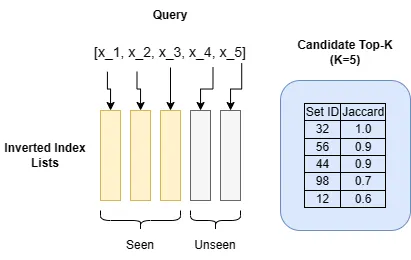
如何计算上界Jaccard?在处理n个候选列表后,对于任何未见的候选项,它们与查询集的最大交集最多等于剩余未处理列表的数量:|Q|-n。我们给予它最大的怀疑,即假设这样的候选项可能出现在剩余的|Q|-n个列表中的每一个列表中。现在我们可以使用简单的数学方法推导出这样的候选项X的上界Jaccard。
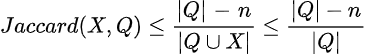
这个巧妙的技术在集合相似性搜索研究文献中被称为前缀过滤器。我写了一篇关于它的论文,详细介绍了更多细节和进一步的算法优化。我还创建了一个名为SetSimilaritySearch的Python库,实现了一个更优化的search_top_k_probe_set算法版本,还支持余弦相似度和包含相似度的计算。
Jaccard搜索的近似索引
在上一节中,我解释了两个在倒排索引上工作的搜索算法。这些算法是精确的,也就是说它们返回的前k个候选项是真正的前k个候选项。听起来陈词滥调?好吧,在我们设计大规模数据上的搜索算法时,这是一个我们应该问自己的问题,因为在许多情况下,不需要获取真正的前k个候选项。
再次思考一下Spotify的例子:你真的在乎搜索结果可能会错过一些与你口味相似的人吗?大多数人都知道,在日常应用程序(Google、Spotify、Twitter等)中,搜索永远不是详尽无遗或精确的。这些应用程序并不足以证明需要精确搜索。这就是为什么最常用的搜索算法都是近似的原因。
使用近似搜索算法有两个主要好处:
- 更快。如果不需要精确结果,可以省略许多步骤。
- 可预测的资源消耗。这一点不太明显,但对于几种近似算法,它们的资源使用(例如内存)可以事先配置,而与数据分布无关。
在本文中,我将介绍Jaccard最常用的近似索引:MinHash局部敏感哈希(MinHash LSH)。
LSH是什么?
局部敏感哈希索引是计算机科学中真正的奇迹。它们是由数论驱动的算法魔法。在机器学习文献中,它们是k-NN模型,但与典型的机器学习模型不同,LSH索引是数据无关的,因此它们的准确性在相似性条件下可以在摄取新数据点或更改数据分布之前确定。因此,它们更类似于倒排索引而不是模型。
LSH索引实际上是一组具有不同哈希函数的哈希表。就像一个典型的哈希表一样,LSH索引的哈希函数将数据点(例如集合、特征向量或嵌入向量)作为输入,并输出二进制哈希键。除此之外,它们之间几乎没有任何相似之处。
典型的哈希函数对于任何输入数据,都会输出几乎随机且均匀分布在整个键空间上的键。例如,MurmurHash是一个众所周知的哈希函数,它在32位键空间上输出接近均匀和随机的值。这意味着对于任何两个不同的输入,例如abcdefg和abcefg,只要它们不同,它们的MurmurHash键就不应该相关,并且应该具有成为整个32位键空间中任何一个键的相同概率。这是哈希函数的期望特性,因为您希望键均匀分布在哈希桶上,以避免链式处理或不断调整哈希表的大小。
LSH的哈希函数则相反:对于一对相似的输入,通过某个度量空间测量定义其相似性,它们的哈希键更有可能相等,而不是另一对不相似的输入的哈希键。
这意味着LSH哈希函数对于更相似的数据点具有更高的哈希键冲突概率。实际上,我们利用这种更高的冲突概率进行基于相似性的检索。
MinHash LSH
对于每个相似性/距离度量,都有一个LSH哈希函数。对于Jaccard距离,该函数称为MinHash函数。给定一个输入集合,MinHash函数使用随机哈希函数消耗所有元素,并跟踪观察到的最小哈希值。您可以使用单个MinHash函数构建LSH索引。请参见下图。

MinHash函数背后的数学理论表明,两个集合具有相同的最小哈希值(即哈希键冲突)的概率与它们的Jaccard相同。
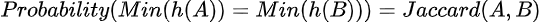
这是一个神奇的结果,但证明非常简单。
单个MinHash函数的LSH索引无法提供令人满意的准确性,因为冲突概率与Jaccard线性成正比。请参见下图了解原因。
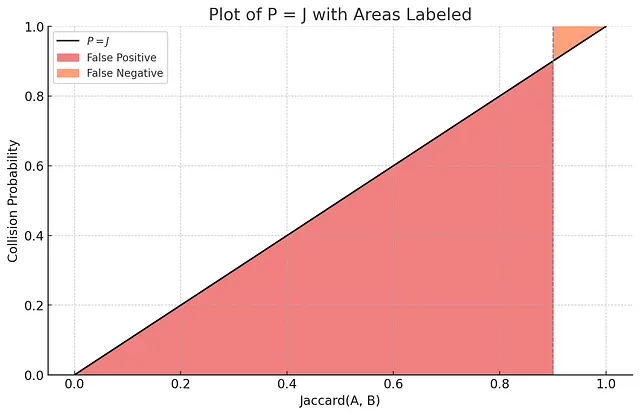
想象一下,我们在Jaccard = 0.9处划定一个阈值:高于0.9的Jaccard值与查询集相关,而低于0.9的Jaccard值则不相关。在搜索的背景下,“假阳性”的概念意味着返回了不相关的结果,而“假阴性”的概念意味着没有返回相关的结果。根据上图并查看与假阳性相对应的区域:如果索引只使用单个MinHash函数,它将以非常高的概率产生假阳性。
提高MinHash LSH的准确性
这就是为什么我们需要另一种LSH的魔法:一种称为boosting的过程。我们可以提升索引,使其更加适应指定的相关性阈值。
我们不仅使用一个,而是使用通过称为通用哈希的过程生成的m个MinHash函数 —— 基本上是相同哈希函数的m个随机排列,每个排列针对每个索引集生成m个最小哈希值。
想象一下,您列出了一个索引集的m个最小哈希值。我们将每个r个哈希值分组成一组哈希值,并创建b个这样的组。这需要m = b * r。

两个集合发生“带碰撞”的概率 —— 两个集合之间的所有哈希值在一个组内发生碰撞,或r个连续的哈希值发生碰撞,为Jaccard(A, B)^r。这比单个哈希值的概率要小得多。然而,两个集合之间至少发生一次“带碰撞”的概率是1 - (1-Jaccard(A, B)^r)^b。
为什么我们关心1 - (1-Jaccard(A, B)^r)^b?因为这个函数有一个特殊的形状:
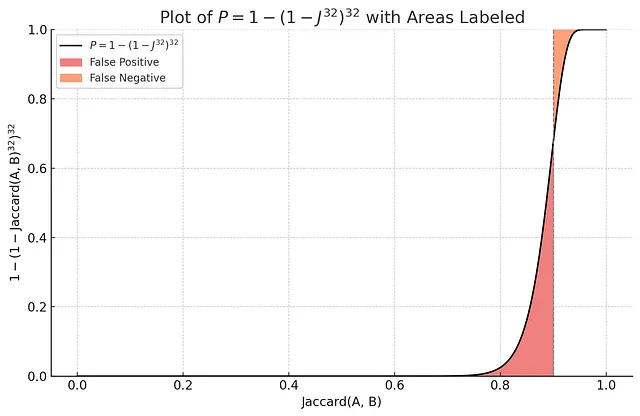
在上面的图中,可以看到使用m个MinHash函数时,“至少一次带碰撞”概率是一个具有陡峭上升曲线的S形函数,该曲线在Jaccard = 0.9附近。假设相关性阈值为0.9,该索引的假阳性概率要比仅使用一个随机哈希函数的索引要小得多。
因此,LSH索引始终使用b个r个MinHash函数来提高准确性。每个组是一个哈希表,存储指向索引集的指针。在搜索期间,任何与查询集在任何组上发生碰撞的索引集都会被返回。
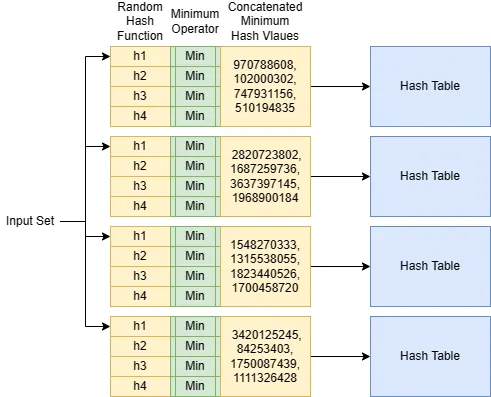
要构建一个MinHash LSH索引,我们可以指定先验的相关性阈值和基于Jaccard相似性的可接受的假阳性和假阴性概率,并在索引任何数据点之前计算出最优的m、b和r。这是使用LSH相对于其他近似索引的一个很大优势。
你可以在Python包datasketch中找到我对MinHash LSH的实现。它还包含其他与MinHash相关的算法,如LSH Forest和Weighted MinHash。
最后的想法
在这篇文章中,我涵盖了很多主题,但只是浅尝辄止了Jaccard相似性的搜索索引。如果你对这些主题感兴趣,我为你准备了一些进一步阅读的列表:
- 《大规模数据挖掘》(Jure Leskovec、Anand Rajaraman和Jeff Ullman著)。第三章详细介绍了MinHash和LSH。我认为这是一个很好的章节,可以帮助你理解MinHash的直觉。请注意,章节中描述的应用主要集中在基于n-gram的文本匹配上。
- 《JOSIE:数据湖中用于查找可连接表的重叠集合相似性搜索》。本文的初步部分解释了
search_top_k_merge_list和search_top_k_probe_set算法的直观性。主要部分解释了在输入集合很大(如表列)时如何考虑成本。 - 分别使用Datasketch和SetSimilaritySearch库实现了最先进的近似和精确的Jaccard相似性搜索索引。Datasketch项目的问题列表是应用场景和应用MinHash LSH时的实际考虑因素的宝库。
嵌入是什么情况?
近年来,由于深度神经网络(如Transformer)在表示学习方面的突破,当输入数据属于嵌入模型训练的相同领域时,学习的嵌入向量之间的相似性是有意义的。这种情况与本文描述的搜索场景之间的主要区别有:
- 嵌入向量是稠密向量,通常具有60到700个维度。每个维度都是非零的。相反,当表示为独热向量时,集合是稀疏的:10k到数百万个维度,但大多数维度都是零。
- 嵌入向量通常使用余弦相似度(或规范化向量的点积)。对于集合,我们使用Jaccard相似度。
- 在嵌入向量之间指定相似性阈值很困难,因为这些向量是原始数据(如图像或文本)的学习黑盒表示。另一方面,对于集合,指定Jaccard相似性阈值要容易得多,因为集合就是原始数据。
由于上述差异,直接比较嵌入和集合并不简单,因为它们是明显不同的数据类型,尽管你可以将它们都归类为高维数据。它们适用于不同的应用场景。