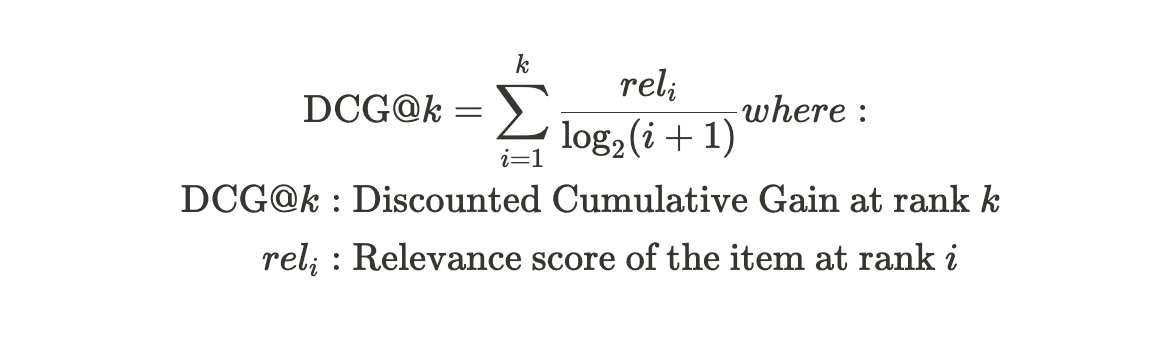揭示偏差调整的能力:增强不平衡数据集中的预测精度
揭示偏差调整的能力:增强不平衡数据集中的预测精度' Revealing the ability of bias adjustment enhancing prediction accuracy in imbalanced datasets.
处理类别不平衡对于数据科学中准确预测至关重要。本文介绍了偏差调整(Bias Adjustment)以在类别不平衡中提高模型准确性。探索偏差调整如何优化预测并克服这一挑战。
介绍
在数据科学领域中,有效处理不平衡的数据集对于精确预测至关重要。不平衡的数据集表现为类别差异显著,可能导致模型偏向多数类别,并在关键场景(如欺诈检测和疾病诊断)中对少数类别的性能表现不佳。
本文介绍一种实用的解决方案,即偏差调整。通过微调模型中的偏差项,偏差调整抵消类别不平衡,增强模型对多数和少数类别的准确预测能力。本文概述了适用于二元和多类别分类的算法,并探讨了它们的基本原理。值得注意的是,算法解释和基本原理部分严密建立了我的算法、过采样和调整类别权重之间的理论联系,提高读者的理解能力。
为了验证偏差调整与过采样之间的关系和合理性,本文进行了模拟研究,并运用实际应用案例说明了在信用卡欺诈检测中应用偏差调整的实施和实际效益。
- 新的SHAP图表:小提琴图和热力图
- 在XGen-Image-1之中:Salesforce Research如何构建、训练和评估一个庞大的文本到图像模型
- Anthropic获得来自SK Telecom的1亿美元资金注入,以推进电信行业特定的人工智能技术
偏差调整为在类别不平衡情况下改善预测建模结果提供了一条直接而有影响力的途径。本文全面介绍了偏差调整的机制、原理和在现实世界中的影响,使其成为寻求在不平衡数据集中提高模型性能的数据科学家的宝贵工具。
算法
偏差调整算法介绍了一种处理二元和多类别分类任务中类别不平衡的方法。通过在每个迭代周期重新校准偏差项,该算法增强了模型处理不平衡数据集的能力。通过调整偏差项,该算法使模型对少数类别实例更敏感,从而提高分类准确性。
模型 f(x) 及其在预测中的作用
我们的偏差调整算法的核心概念是 f(x)——一个指导我们处理类别不平衡方法的关键因素。f(x) 在输入特征 x 和最终预测结果之间起到了联系的作用。在二元分类中,它作为一个映射将输入转换为与 Sigmoid 激活函数相对应的实值,用于概率解释。在多类别分类中,f(x) 转变为一组函数 f_k(x),其中每个类别 k 都有自己的函数,与 Softmax 激活函数配合工作。这种区别对于我们的偏差调整算法至关重要,我们使用 f(x) 来调整偏差项,并微调对类别不平衡的敏感性。
算法简要概述
该算法的概念很简单:计算每个类别 k 的 f_k(x) 的平均值,并将该平均值表示为 δk。通过将 f_k(x) 减去 δk,我们确保 f_k(x) − δk 的期望值对于每个类别 k 都变为 0。因此,模型预测每个类别出现的可能性相等。虽然这提供了对算法原理的简明概述,但需要注意的是,这种方法是基于理论和数学基础的,后续文章的部分将进一步探讨。
二元分类算法

预测的利用:在进行预测时,应用算法中最后计算的 δ 值。这个 δ 值反映了训练过程中进行的累积调整,并作为 Sigmoid 激活函数中最终偏差项的基础。

多类别分类算法

预测的利用:我们算法训练过程的最终结果是一个关键元素——最后计算得到的δk值。这个δk值包含了在训练过程中精心编排的累积偏置项调整。它的重要性在于它在预测过程中作为softmax激活函数的最终偏置项的基础参数的角色。
算法解释和基本原理
从过采样到调整类别权重,从调整类别权重到新算法
在本节中,我们将探讨算法的解释和基本原理。我们的目标是阐明算法操作背后的机制和原理,以便深入了解它在解决分类任务中的类别不平衡问题上的有效性。
损失函数和不平衡
我们首先深入研究算法的核心——损失函数。在我们的初步阐述中,我们将研究不直接解决类别不平衡问题的损失函数。让我们考虑一个二分类问题,其中类别1占90%的观测值,而类别0占剩下的10%。将来自类别1的观测值集合表示为C1,来自类别0的观测值集合表示为C0,我们以此作为起点。
没有解决类别不平衡问题的损失函数形式如下:
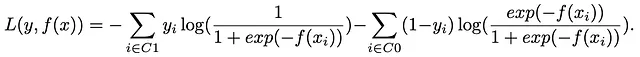
在模型估计的过程中,我们努力将这个损失函数最小化:
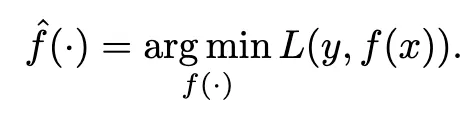
缓解不平衡:过采样和调整类别权重
然而,我们的努力的关键在于解决类别不平衡问题。为了克服这个挑战,我们尝试使用过采样技术。虽然有各种过采样方法存在,包括简单过采样、随机过采样、SMOTE等,但为了说明清楚,我们的重点集中在简单过采样上,稍微提及随机过采样。
简单过采样:我们武器库中的一个基本方法是简单过采样,这是一种将少数类实例复制8倍以与多数类的大小相匹配的技术。在我们的示例中,少数类占10%,多数类占剩下的90%,我们将少数类观测值复制8倍,有效地使类别分布相等。将复制的观测值集合表示为D0,这一步将我们的损失函数转换为:
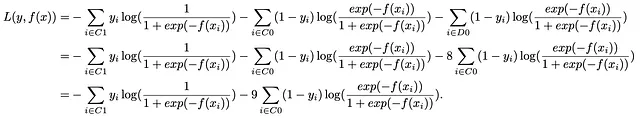
这揭示了一个深刻的洞察:简单过采样的核心原理无缝对应于调整类别权重的概念。将少数类复制8倍实际上相当于将少数类的权重增加到9倍。重要的是,过采样技术与权重调整机制相互映射。
随机过采样:对随机过采样进行简要思考也会得出类似的观察结果。随机过采样,类似于其简化版本,相当于随机调整观测权重。
从调整类别权重到调整偏置
一个关键的发现突显了我们方法的核心:在偏置调整、过采样和权重调整之间存在基本的等价关系。这个洞察来自于
“Prentice和Pyke(1979)…已经表明,当模型包含每个类别的常数(截距)项时,这些常数项是由于Y的不平衡选择概率而受到影响的唯一系数” Scott&Wild(1986)[2]。此外,Manski和Lerman(1977)还在softmax设置中展示了同样的结果[1]。
揭示重要性:将这一洞察力转化到机器学习领域,常数项(截距)是偏置项。这一基本观察揭示了,当我们重新校准类别权重或观测权重时,产生的变化主要体现为对偏置项的调整。简而言之,偏置项是将我们的策略与解决类别不平衡问题联系起来的关键。
统一视角
这种理解提供了一个简明的解释,即我们的算法、过采样和权重调整本质上是可以互换和替代的。这种统一化简化了我们的方法,同时保持了它在缓解类别不平衡挑战方面的效力。
模拟研究:通过过采样验证偏置项的影响
为了巩固我们的主张,即过采样主要影响偏置项,同时保持模型的核心不变,我们进行了一项有针对性的模拟研究。我们的目标是通过实证数据来演示过采样技术仅影响偏置项,而不改变模型的本质。
模拟设置
为了说明目的,我们将重点放在一个简化的情景上:具有单个特征的逻辑回归。我们的模型定义为:
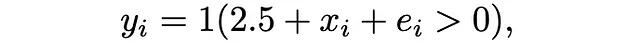
其中1(.)表示指示函数,x_i来自标准正态分布,而e_i来自逻辑分布。在这个上下文中,我们设置f(x)=x。
运行模拟:
利用这个设置,我们详细研究了过采样技术对偏置项的影响,同时保持模型的核心不变。我们使用了三种过采样方法:简单过采样、SMOTE和随机抽样。每种方法都被细致地应用,并仔细记录结果。
下面的Python代码片段概述了模拟过程:
# 导入包
import numpy as np
import statsmodels.api as sm
from imblearn.over_sampling import SMOTE, RandomOverSampler
# 设置随机种子
np.random.seed(1)
# 创建模拟数据集
x = np.random.normal(size=10000)
y = (2.5 + x + np.random.logistic(size=10000)) > 0
# 偏置项设置为2.5,x的系数设置为1
# 类别1的大小为9005
print(sum(y == 1))
# 类别0的大小为995
print(sum(y == 0))
# 我们希望将类别0的大小与类别1相匹配
# 方法0:什么也不做
x0 = x
y0 = y
method0 = sm.Logit(y0, sm.add_constant(x0)).fit()
print(method0.summary()) # 偏置项为2.54,x的系数为0.97
# 方法1:简单过采样
x1 = np.concatenate((x, np.repeat(x[y == 0], 8)))
y1 = np.concatenate((y, np.array([0] * (len(x1) - len(x)))))
method1 = sm.Logit(y1, sm.add_constant(x1)).fit()
print(method1.summary()) # 偏置项为0.35,x的系数为0.98
# 方法2:SMOTE
smote = SMOTE(random_state=1)
x2, y2 = smote.fit_resample(x[:, np.newaxis], y)
method2 = sm.Logit(y2, sm.add_constant(x2)).fit()
print(method2.summary()) # 偏置项为0.35,x的系数为1
# 方法3:随机抽样
random_sampler = RandomOverSampler(random_state=1)
x3, y3 = random_sampler.fit_resample(x[:, np.newaxis], y)
method3 = sm.Logit(y3, sm.add_constant(x3)).fit()
print(method3.summary()) # 偏置项为0.35,x的系数为0.99
结果:
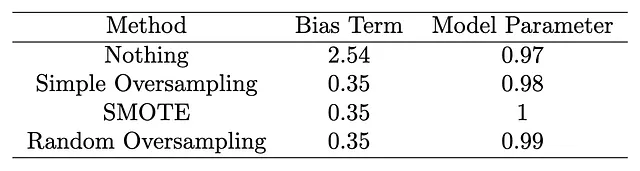
关键观察
我们的模拟研究结果简明地验证了我们的命题。尽管应用了各种过采样方法,但核心模型函数 f(x)=x 保持不变。关键的洞察在于模型组件在所有过采样技术中的显著一致性。相反,偏差项表现出明显的变化,证实了我们的主张,即过采样主要影响偏差项,而不影响底层模型结构。
强化核心概念
我们的模拟研究无可否认地强调了过采样、权重调整和偏差项修改之间的基本等价性。通过展示过采样仅仅改变了偏差项,我们加强了这样一个原则:这些策略是解决类别不平衡问题的可互换工具。
将偏差调整算法应用于信用卡欺诈检测
为了展示我们的偏差调整算法在解决类别不平衡问题方面的有效性,我们使用了一个关于信用卡欺诈检测的 Kaggle 竞赛的真实数据集。在这种情况下,挑战在于预测一笔信用卡交易是否是欺诈行为(标记为 1)还是非欺诈行为(标记为 0),鉴于欺诈案例的固有稀缺性。
我们首先加载必要的包并准备数据集:
import numpy as npimport pandas as pdimport tensorflow as tfimport tensorflow_addons as tfafrom sklearn.model_selection import train_test_splitfrom imblearn.over_sampling import SMOTE, RandomOverSampler# 加载和预处理数据集df = pd.read_csv("/kaggle/input/playground-series-s3e4/train.csv")y, x = df.Class, df[df.columns[1:-1]]x = (x - x.min()) / (x.max() - x.min())x_train, x_valid, y_train, y_valid = train_test_split(x, y, test_size=0.3, random_state=1)batch_size = 256train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train)).shuffle(buffer_size=1024).batch(batch_size)valid_dataset = tf.data.Dataset.from_tensor_slices((x_valid, y_valid)).batch(batch_size)然后,我们定义一个用于二分类的简单深度学习模型,并设置优化器、损失函数和评估指标。我遵循竞赛评估标准选择了 AUC 作为评估指标。此外,由于本文的重点是展示如何实现偏差调整算法,而不是在预测方面取得优异表现,所以模型被故意简化:
model = tf.keras.Sequential([ tf.keras.layers.Normalization(), tf.keras.layers.Dense(32, activation='swish'), tf.keras.layers.Dense(32, activation='swish'), tf.keras.layers.Dense(1)])optimizer = tf.keras.optimizers.Adam()loss = tf.keras.losses.BinaryCrossentropy()val_metric = tf.keras.metrics.AUC()在我们偏差调整算法的核心中,训练和验证步骤详细地处理了类别不平衡问题。为了阐明这个过程,我们深入研究了平衡模型预测的复杂机制。
带有累积 Delta 值的训练步骤
在训练步骤中,我们开始增强模型对类别不平衡的敏感性之旅。在这里,我们计算并累积两个不同聚类的模型输出之和:delta0 和 delta1。这些聚类非常重要,分别代表与类别 0 和 1 相关联的预测值。
# 定义训练步骤函数@tf.functiondef train_step(x, y): delta0, delta1 = tf.constant(0, dtype = tf.float32), tf.constant(0, dtype = tf.float32) with tf.GradientTape() as tape: logits = model(x, training=True) y_pred = tf.keras.activations.sigmoid(logits) loss_value = loss(y, y_pred) # 计算用于解决类别不平衡的新偏差项 if len(logits[y == 1]) == 0: delta0 -= (tf.reduce_sum(logits[y == 0])) elif len(logits[y == 0]) == 0: delta1 -= (tf.reduce_sum(logits[y == 1])) else: delta0 -= (tf.reduce_sum(logits[y == 0])) delta1 -= (tf.reduce_sum(logits[y == 1])) grads = tape.gradient(loss_value, model.trainable_weights) optimizer.apply_gradients(zip(grads, model.trainable_weights)) return loss_value, delta0, delta1验证步骤:使用 Delta 进行不平衡解决
在验证步骤中,从训练过程中得出的归一化 Delta 值成为主角。凭借这些经过精细调整的类别不平衡指标,我们可以更准确地将模型的预测与类别的真实分布对齐。 test_step 函数集成了这些 Delta 值,自适应地调整预测,最终得到一个精细的评估。
@tf.functiondef test_step(x, y, delta): logits = model(x, training=False) y_pred = tf.keras.activations.sigmoid(logits + delta) # 使用 Delta 调整预测 val_metric.update_state(y, y_pred)利用 Delta 值进行不平衡校正
随着训练的进行,我们收集到了delta0和delta1聚类和的有价值见解。这些累积值成为我们模型预测中固有偏差的指标。在每个时期结束时,我们执行一个重要的转换。通过将累积的聚类和值除以每个类别的相应观察数,我们得到了归一化的 Delta 值。这种归一化作为一个关键的均衡器,概括了我们的偏差调整方法的本质。
E = 1000P = 10B = len(train_dataset)N_class0, N_class1 = sum(y_train == 0), sum(y_train == 1)early_stopping_patience = 0best_metric = 0for epoch in range(E): # 初始化 delta delta0, delta1 = tf.constant(0, dtype = tf.float32), tf.constant(0, dtype = tf.float32) print("\n开始第 %d 个时期" % (epoch,)) # 遍历数据集的批次 for step, (x_batch_train, y_batch_train) in enumerate(train_dataset): loss_value, step_delta0, step_delta1 = train_step(x_batch_train, y_batch_train) # 更新 delta delta0 += step_delta0 delta1 += step_delta1 # 取所有 delta 值的平均 delta = (delta0/N_class0 + delta1/N_class1)/2 # 在每个时期结束时运行验证循环 for x_batch_val, y_batch_val in valid_dataset: test_step(x_batch_val, y_batch_val, delta) val_auc = val_metric.result() val_metric.reset_states() print("验证 AUC:%.4f" % (float(val_auc),)) if val_auc > best_metric: best_metric = val_auc early_stopping_patience = 0 else: early_stopping_patience += 1 if early_stopping_patience > P: print("达到提前停止耐心。训练在验证 AUC:%.4f 处结束" % (float(best_metric),)) break;结果
在我们应用于信用卡欺诈检测中,我们的算法的增强效果显而易见。通过将偏差调整无缝集成到训练过程中,我们获得了令人瞩目的 AUC 分数 0.77。与没有偏差调整指导下达到的 AUC 分数 0.71 形成了鲜明对比。预测性能的深刻提升证明了该算法在处理类别不平衡方面的能力,为实现更准确可靠的预测指引了道路。
参考文献
[1] Manski, C. F., & Lerman, S. R. (1977). The estimation of choice probabilities from choice based samples. Econometrica: Journal of the Econometric Society, 1977–1988.
[2] Scott, A. J., & Wild, C. J. (1986). Fitting logistic models under case-control or choice based sampling. Journal of the Royal Statistical Society Series B: Statistical Methodology, 48(2), 170–182.