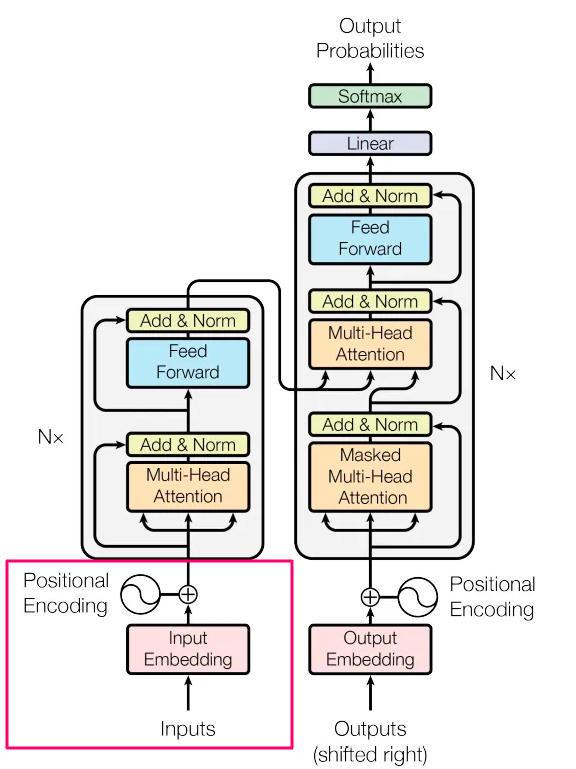
内容管理到零射击分类
内容管理零射击分类
如果我们想要分析一小段没有额外信息或背景的文本,并且能够得到我们自己定义的最合理的标签,那该怎么办呢?这可以为更确定性的策略引擎和规则引擎提供数据,并且在需要时甚至可以成为更大背景驱动分析的一部分。OpenAI确实提供了一种“内容审核”的方法,可以确定您的文本是否属于更恶劣的类别之一。然而,这种分析更多关注的是如何更加自定义地对给定的句子或短语定义我们自己的标签。
我们将查看4个类别:即政治、PHI/PII、法律事务和公司绩效。鉴于我们目前无法从Open AI获取关于这些自定义标签的概率分数的选择,我们将尝试使用更加面向用户的提示工程方法(选项1),而选项2则评估了Hugging Face的其他预训练模型。
我们还会使用一些样本句子,这些句子经常被扭曲以与多个类别对齐。例如,我们的CSV输入文件中的以下行被称为“有效负载”:
- 当部长们开始将问题变得个人化时,问题就开始偏离了轨道。
- 我试图与我的猫协商数据隐私问题,但它只是无视我,占用我的键盘打个盹。
- 参议院的听证会是关于一种正在试验中的药物是否只能用于这个病人的问题。他的血液有一种特殊的情况,目前还没有药物可以治疗。
- 一个政治辩论开始后,讨论的重点转向了与超大规模计算公司的合作伙伴之间的故事更好的公司优先事项。
- 法院关于言论自由的重大决定在在线平台上引发了关于表达和有害内容之间微妙界限的讨论,将法律考虑与在线治理的辩论交织在一起。
- 我在我进行PHI检查时告诉我的医生一个政治笑话,现在我的病历上写着:患者的幽默感:危险的两党制。
- 用户管理的访问让您享受所谓的控制您的身份的好处;但是有多少人会仔细审查您手机上利用名字、电子邮件和电话号码的应用程序权限?
选项1:使用OpenAI进行提示工程
GPT-4似乎比3.5涡轮堂兄弟在这些扭曲的句子上稍微好一些。输出的数据框的格式如下所示。它在大多数情况下都能正确地得到更大的概率,只是在像第3句这样的句子中,我们本来希望与PHI/PII相关的一些“%”是有关联的。它还说明我们需要请求OpenAI提供一些自定义便利来标记我们的标签,并利用这些模型更快、更“博学”的能力。
选项2:使用Hugging Face的模型进行零样本分类
接下来,我们尝试使用Hugging Face的预训练模型来进行相同的操作,这些模型在某种程度上是专门为此任务设计的。
注意:将multi_label的值设置为True。您也可以尝试将其设置为False。
让我们还使用我们自己的人类专业知识来审查这个输出(最后一列)。我们可以使用以下简单的指标:
- 合理 – 表示引擎准确地选择了多个标签
- 部分准确 – 两个标签中有一个是准确的
- 不准确 – 显然不太好
数据集太小,无法得出明确的结果,但它们在这个任务中似乎都位于相对可比的空间。
总结
大型语言模型对于许多目的来说都是一种“一刀切”的解决方案。对于需要对零样本分类进行自定义标签的情况,当我们几乎没有上下文可依赖时,我们仍然可以选择训练在更专门用途的NLI(自然语言推理)模型上的替代方案,如上述模型。对于特定需求的最终选择可能基于性能(在实时交易中使用时)、能够有效地使其更确定性的附加上下文的程度以及对于给定生态系统的集成的便利程度。
注意:特别感谢那些在论坛上纠正了我的代码或分享了如何更好地使用这些模型的建议的人。具体来说,Open AI论坛上有人分享了这样一个直觉,可以更好地查询GPT以获取通过API调用无法获得的结果。