使用全同态加密实现大型语言模型的研究
全同态加密实现大型语言模型研究
大型语言模型(LLM)最近被证明是提高生产力的可靠工具,可应用于诸多领域,例如编程、内容创作、文本分析、网络搜索和远程学习。
大型语言模型对用户隐私的影响
尽管LLM具有吸引力,但仍存在与这些模型处理的用户查询相关的隐私问题。一方面,利用LLM的能力是可取的,但另一方面,存在将敏感信息泄露给LLM服务提供商的风险。在某些领域,如医疗保健、金融或法律,这种隐私风险是不可接受的。
解决此问题的一种可能方法是进行本地部署,在客户端机器上部署LLM所有者的模型。但是,这并不是最优的解决方案,因为构建一个LLM可能需要数百万美元(GPT3的成本为460万美元),而本地部署会存在泄露模型知识产权(IP)的风险。
Zama相信您可以兼顾两全:我们的目标是保护用户的隐私和模型的知识产权。在本博客中,您将了解如何利用Hugging Face transformers库,使这些模型的部分部分在加密数据上运行。完整的代码可以在此用例示例中找到。
- Huggy Lingo 使用机器学习改善Hugging Face Hub上的语言元数据
- 在机器学习中使用SHAP值进行模型解释性分析
- 麻省理工学院研究人员推出PhotoGuard:一种新的AI工具,可以防止未经授权的图像篡改
全同态加密(FHE)可以解决LLM隐私挑战
Zama对LLM部署挑战的解决方案是使用全同态加密(FHE),它使得能够在加密数据上执行函数。可以实现保护模型所有者的知识产权的目标,同时仍然保持用户数据的隐私。此演示显示,使用FHE实现的LLM模型保持了原始模型预测的质量。为了做到这一点,需要改编Hugging Face transformers库中的GPT2实现,使用Concrete-Python重新设计推理的部分,Concrete-Python可以将Python函数转换为FHE等效的函数。
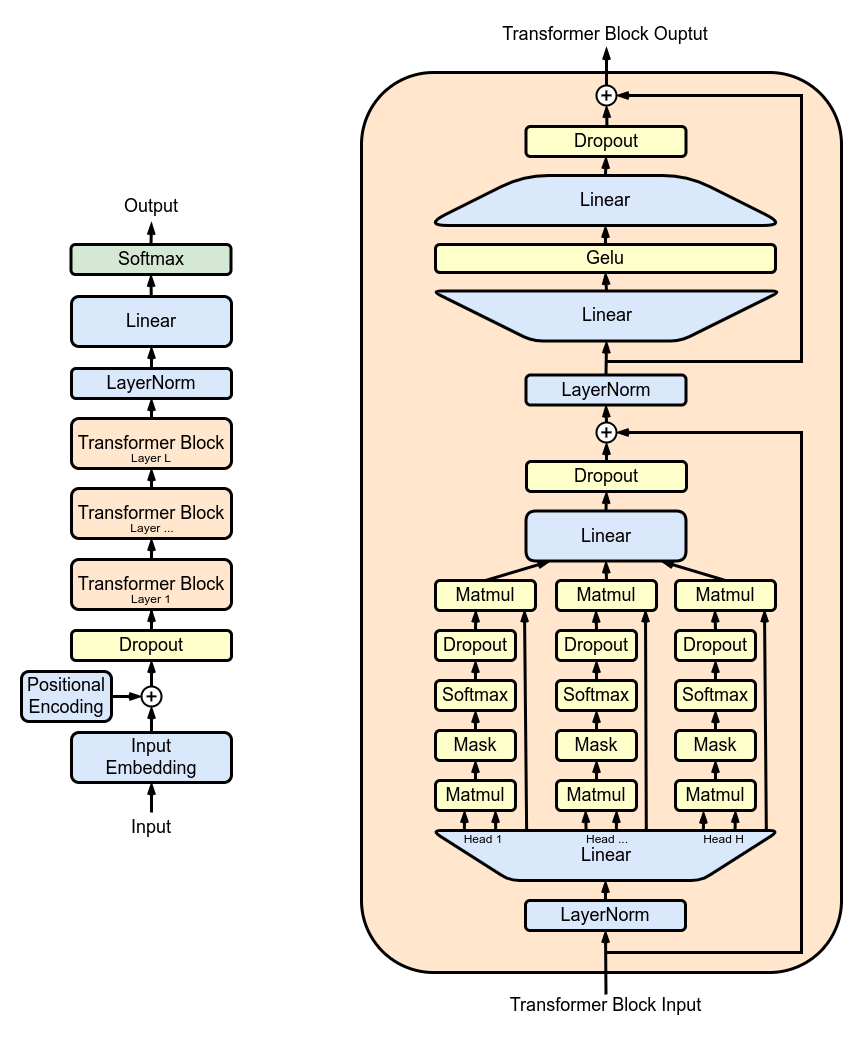
图1显示了GPT2的架构,它具有重复的结构:连续应用的多头注意力(MHA)层的系列。每个MHA层使用模型权重投影输入,计算注意力机制,然后将注意力的输出重新投影到新的张量中。
在TFHE中,模型权重和激活使用整数表示。非线性函数必须使用可编程引导(PBS)操作来实现。PBS在加密数据上实现了表查找(TLU)操作,同时刷新密文以允许任意计算。不足之处是PBS的计算时间占据了线性操作的时间。利用这两种类型的操作,可以在FHE中表示LLM的任何子部分,甚至是整个计算过程。
使用FHE实现LLM层
接下来,您将了解如何对多头注意力(MHA)块的单个注意力头进行加密。您还可以在此用例示例中找到完整MHA块的示例。

图2显示了底层实现的简化概述。客户端从共享模型开始本地推理,直到第一层被移除。用户对中间操作进行加密,并将其发送到服务器。服务器应用部分注意力机制,然后将结果返回给客户端,客户端可以对其进行解密并继续本地推理。
量化
首先,为了对加密值进行模型推理,模型的权重和激活必须进行量化并转换为整数。理想的方法是使用后训练量化,无需重新训练模型。过程是实现与FHE兼容的注意力机制,使用整数和PBS,然后检查对LLM准确性的影响。
为了评估量化的影响,在加密数据上运行具有单个LLM头的完整GPT2模型。然后,评估在变化权重和激活的量化位数时所获得的准确性。
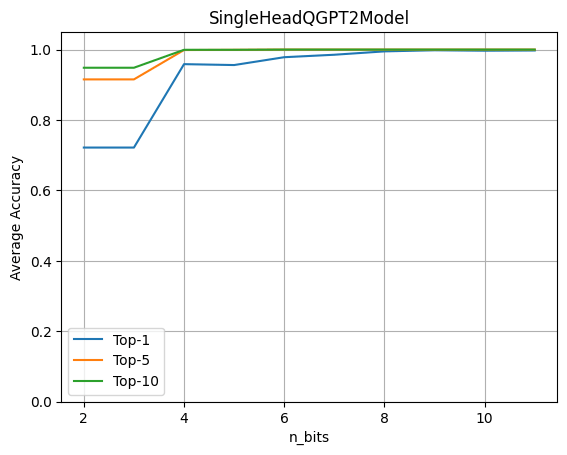
这个图显示了4位量化可以保持原始准确度的96%。实验使用了一个大约80个句子的数据集。通过比较原始模型的logits预测和量化头模型的预测来计算指标。
将FHE应用于Hugging Face GPT2模型
在Hugging Face的transformers库的基础上,重写要加密的模块的前向传递,以包括量化运算符。首先加载一个GPT2LMHeadModel,然后使用QGPT2SingleHeadAttention模块替换第一个多头注意力模块,构建一个SingleHeadQGPT2Model实例。完整的实现可以在这里找到。
self.transformer.h[0].attn = QGPT2SingleHeadAttention(config, n_bits=n_bits)然后,重写前向传递,使得多头注意力机制的第一个头部,包括构建查询、键和值矩阵的投影,使用FHE友好的运算符进行计算。下面的QGPT2模块可以在这里找到。
class SingleHeadAttention(QGPT2):
"""使用量化方法实现的单个注意力头的类。"""
def run_numpy(self, q_hidden_states: np.ndarray):
# 将输入转换为DualArray实例
q_x = DualArray(
float_array=self.x_calib,
int_array=q_hidden_states,
quantizer=self.quantizer
)
# 提取注意力基本模块名称
mha_weights_name = f"transformer.h.{self.layer}.attn."
# 使用适当的索引提取查询、键和值的权重和偏置值
head_0_indices = [
list(range(i * self.n_embd, i * self.n_embd + self.head_dim))
for i in range(3)
]
q_qkv_weights = ...
q_qkv_bias = ...
# 应用第一个投影以将Q、K和V提取为一个单独的数组
q_qkv = q_x.linear(
weight=q_qkv_weights,
bias=q_qkv_bias,
key=f"attention_qkv_proj_layer_{self.layer}",
)
# 提取查询、键和值
q_qkv = q_qkv.expand_dims(axis=1, key=f"unsqueeze_{self.layer}")
q_q, q_k, q_v = q_qkv.enc_split(
3,
axis=-1,
key=f"qkv_split_layer_{self.layer}"
)
# 计算注意力机制
q_y = self.attention(q_q, q_k, q_v)
return self.finalize(q_y)模型中的其他计算仍然是浮点数,非加密的,预计由客户端在本地执行。
加载以这种方式修改的GPT2模型的预训练权重后,可以调用generate方法:
qgpt2_model = SingleHeadQGPT2Model.from_pretrained(
"gpt2_model", n_bits=4, use_cache=False
)
output_ids = qgpt2_model.generate(input_ids)例如,可以要求量化模型完成短语“Cryptography is a”的补全。在使用FHE运行模型时,具有足够的量化精度,生成的输出为:
“Cryptography is a very important part of the security of your computer”
当量化精度过低时,将得到:
“Cryptography is a great way to learn about the world around you”
编译为FHE
现在可以使用以下Concrete-ML代码编译注意力头:
circuit_head = qgpt2_model.compile(input_ids)运行后,将看到以下打印输出:“Circuit compiled with 8 bit-width”。这个与FHE兼容的配置显示了在FHE中执行操作所需的最大比特宽度。
复杂度
在Transformer模型中,计算量最大的操作是注意力机制,它乘以查询、键和值。在FHE中,该成本由于在加密域中的乘法的特殊性而增加。此外,随着序列长度的增加,这些具有挑战性的乘法的数量呈二次增加。
对于加密头,长度为6的序列需要11,622个PBS操作。这是第一次实验,尚未对性能进行优化。虽然它可以在几秒钟内运行,但它需要相当多的计算能力。幸运的是,硬件将通过1000倍至10000倍提高延迟,使得在几年后,事物将从CPU上的几分钟变为ASIC上的< 100ms。有关这些预测的更多信息,请参阅此博文。
结论
大型语言模型是广泛用例中的优秀辅助工具,但它们的实施对于用户隐私提出了重大问题。在本博客中,您看到了使整个LLM在加密数据上工作的第一步,其中模型将完全在云中运行,而用户的隐私将得到充分尊重。
这一步骤包括将模型的特定部分(如GPT2)转换为FHE领域。此实现利用了transformers库,并允许您评估在模型的一部分在加密数据上运行时的准确性影响。除了保护用户隐私外,这种方法还允许模型所有者保持其模型的重要部分的私密性。完整的代码可以在此用例示例中找到。
Zama库的Concrete和Concrete-ML(别忘了在GitHub上给仓库点赞⭐️💛)可以直接构建ML模型并将其转换为FHE等效,以便能够在加密数据上进行计算和预测。
希望您喜欢这篇文章;欢迎分享您的想法/反馈!






