使用OpenAI和FastAPI构建具有记忆微服务的对话代理
使用OpenAI和FastAPI构建对话代理
打造上下文感知的对话代理:深入了解OpenAI和FastAPI的集成
介绍
在本教程中,我们将探索使用OpenAI和FastAPI创建具有记忆微服务的对话代理的过程。对话代理已成为各种应用程序的关键组件,包括客户支持、虚拟助手和信息检索系统。然而,许多传统的聊天机器人实现缺乏在对话期间保留上下文的能力,导致功能有限和用户体验不佳。这在构建遵循微服务架构的代理服务时尤为具有挑战性。
GitHub存储库的链接位于本文底部。
动机
本教程的动机是解决传统聊天机器人实现的局限性,并创建具有记忆微服务的对话代理,尤其在部署到像Kubernetes这样复杂环境中时至关重要。在Kubernetes或类似的容器编排系统中,微服务经常需要重新启动、更新和扩展。在这些事件中,传统聊天机器人的对话状态会丢失,导致交互不连贯和用户体验差。
通过构建具有记忆微服务的对话代理,我们可以确保即使在微服务重新启动、更新或交互不连续的情况下,关键的对话上下文仍然保留。这种状态的保留使代理能够无缝地继续对话,保持连贯性,并提供更自然和个性化的用户体验。此外,这种方法与现代应用程序开发的最佳实践保持一致,其中容器化的微服务通常与其他组件进行交互,使记忆微服务成为分布式设置中对话代理架构的有价值的补充。
我们将使用的技术栈
在此项目中,我们将主要使用以下技术和工具:
- OpenAI GPT-3.5:我们将利用OpenAI的GPT-3.5语言模型,该模型能够执行各种自然语言处理任务,包括文本生成、对话管理和上下文保留。我们需要生成一个OpenAI API密钥,请确保访问此URL来管理您的密钥。
- FastAPI:FastAPI将作为我们微服务的核心,提供处理HTTP请求、管理对话状态和与OpenAI API集成的基础设施。FastAPI非常适合使用Python构建微服务。
开发周期
在本节中,我们将逐步介绍使用记忆微服务构建对话代理的步骤。开发周期将包括:
- 环境设置:我们将创建一个虚拟环境,并安装必要的依赖项,包括OpenAI的Python库和FastAPI。
- 设计记忆微服务:我们将概述记忆微服务的架构和设计,该微服务负责存储和管理对话上下文。
- 集成OpenAI:我们将将OpenAI的GPT-3.5模型集成到我们的应用程序中,并定义处理用户消息和生成响应的逻辑。
- 测试:我们将逐步测试我们的对话代理。
环境设置
对于此设置,我们将使用以下结构构建微服务。这对于在同一项目下扩展其他服务非常方便,我个人喜欢这种结构。
├── Dockerfile <--- 容器├── requirements.txt <--- 库和依赖项├── setup.py <--- 构建和分发微服务作为Python包└── src ├── agents <--- 您的微服务名称 │ ├── __init__.py │ ├── api │ │ ├── __init__.py │ │ ├── routes.py │ │ └── schemas.py │ ├── crud.py │ ├── database.py │ ├── main.py │ ├── models.py │ └── processing.py └── agentsfwrk <--- 您的公共框架名称 ├── __init__.py ├── integrations.py └── logger.py我们需要在项目中创建一个名为src的文件夹,其中包含服务的Python代码;在我们的案例中,agents包含与我们的对话代理和API相关的所有代码,而agentsfwrk是我们在各个服务中通用的框架。
Dockerfile包含构建镜像的指令,在代码准备好后使用;requirements.txt包含项目中要使用的库;setup.py包含构建和分发项目的指令。
现在,只需创建服务文件夹,并添加__init__.py文件,将以下内容添加到项目的根目录的requirements.txt和setup.py中,将Dockerfile保留为空,我们将在部署周期部分回到它。
# Requirements.txtfastapi==0.95.2ipykernel==6.22.0jupyter-bokeh==2.0.2jupyterlab==3.6.3openai==0.27.6pandas==2.0.1sqlalchemy-orm==1.2.10sqlalchemy==2.0.15uvicorn<0.22.0,>=0.21.1
# setup.pyfrom setuptools import find_packages, setupsetup( name = 'conversational-agents', version = '0.1', description = 'conversational agents的微服务', packages = find_packages('src'), package_dir = {'': 'src'}, # 这是可选的 author = 'XXX XXXX', author_email = '[email protected]', maintainer = 'XXX XXXX', maintainer_email = '[email protected]',)让我们激活虚拟环境,在终端中运行pip install -r requirements.txt。暂时不要运行setup文件,让我们进入下一部分。
设计通用框架
我们将设计通用框架,以便在项目中的所有微服务中使用它。对于小型项目来说,这并不是必需的,但考虑到未来,您可以扩展它以使用多个LLM提供商,添加其他与自己的数据交互的库(例如LangChain,VoCode),以及其他常见功能,如语音和图像服务,而无需在每个微服务中实现它们。
按照agentsfwrk的结构创建文件夹和文件。每个文件及其描述如下:
└── agentsfwrk <--- 通用框架的名称 ├── __init__.py ├── integrations.py └── logger.py日志记录器是一个非常基本的实用程序,用于设置一个通用的日志记录模块,您可以按如下方式定义它:
import loggingimport multiprocessingimport sysAPP_LOGGER_NAME = 'CaiApp'def setup_applevel_logger(logger_name = APP_LOGGER_NAME, file_name = None): """ 为应用程序设置日志记录器 """ logger = logging.getLogger(logger_name) logger.setLevel(logging.DEBUG) formatter = logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s") sh = logging.StreamHandler(sys.stdout) sh.setFormatter(formatter) logger.handlers.clear() logger.addHandler(sh) if file_name: fh = logging.FileHandler(file_name) fh.setFormatter(formatter) logger.addHandler(fh) return loggerdef get_multiprocessing_logger(file_name = None): """ 为应用程序设置多进程日志记录器 """ logger = multiprocessing.get_logger() logger.setLevel(logging.DEBUG) formatter = logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s") sh = logging.StreamHandler(sys.stdout) sh.setFormatter(formatter) if not len(logger.handlers): logger.addHandler(sh) if file_name: fh = logging.FileHandler(file_name) fh.setFormatter(formatter) logger.addHandler(fh) return loggerdef get_logger(module_name, logger_name = None): """ 获取模块的日志记录器 """ return logging.getLogger(logger_name or APP_LOGGER_NAME).getChild(module_name)接下来,我们的集成层通过集成模块完成。该文件充当微服务逻辑与OpenAI之间的中间人,并旨在以通用方式为我们的应用程序提供LLM提供商。在这里,我们可以实现处理请求或响应中的异常、错误、重试和超时的常见方法。我从一位非常优秀的经理那里学到,始终在外部服务/API与我们应用程序的内部世界之间放置一个集成层。
下面是集成代码的定义:
# integrations.py# LLM提供商通用模块import jsonimport osimport timefrom typing import Unionimport openaifrom openai.error import APIConnectionError, APIError, RateLimitErrorimport agentsfwrk.logger as loggerlog = logger.get_logger(__name__)openai.api_key = os.getenv('OPENAI_API_KEY')class OpenAIIntegrationService: def __init__( self, context: Union[str, dict], instruction: Union[str, dict] ) -> None: self.context = context self.instructions = instruction if isinstance(self.context, dict): self.messages = [] self.messages.append(self.context) elif isinstance(self.context, str): self.messages = self.instructions + self.context def get_models(self): return openai.Model.list() def add_chat_history(self, messages: list): """ 向对话中添加聊天历史记录。 """ self.messages += messages def answer_to_prompt(self, model: str, prompt: str, **kwargs): """ 收集用户的提示信息,将其附加到同一对话中的消息中,然后返回gpt模型的响应。 """ # 保留对话中的消息 self.messages.append( { 'role': 'user', 'content': prompt } ) retry_exceptions = (APIError, APIConnectionError, RateLimitError) for _ in range(3): try: response = openai.ChatCompletion.create( model = model, messages = self.messages, **kwargs ) break except retry_exceptions as e: if _ == 2: log.error(f"最后一次尝试失败,发生异常: {e}.") return { "answer": "抱歉,我遇到了技术问题。" } retry_time = getattr(e, 'retry_after', 3) log.error(f"发生异常: {e}。{retry_time}秒后重试...") time.sleep(retry_time) response_message = response.choices[0].message["content"] response_data = {"answer": response_message} self.messages.append( { 'role': 'assistant', 'content': response_message } ) return response_data def answer_to_simple_prompt(self, model: str, prompt: str, **kwargs) -> dict: """ 收集上下文并添加用户的提示,然后根据指令返回gpt模型的响应。 该方法只允许一次消息交换。 """ messages = self.messages + f"\n<Client>: {prompt} \n" retry_exceptions = (APIError, APIConnectionError, RateLimitError) for _ in range(3): try: response = openai.Completion.create( model = model, prompt = messages, **kwargs ) break except retry_exceptions as e: if _ == 2: log.error(f"最后一次尝试失败,发生异常: {e}.") return { "intent": False, "answer": "抱歉,我遇到了技术问题。" } retry_time = getattr(e, 'retry_after', 3) log.error(f"发生异常: {e}。{retry_time}秒后重试...") time.sleep(retry_time) response_message = response.choices[0].text try: response_data = json.loads(response_message) answer_text = response_data.get('answer') if answer_text is not None: self.messages = self.messages + f"\n<Client>: {prompt} \n" + f"<Agent>: {answer_text} \n" else: raise ValueError("模型的响应无效。") except ValueError as e: log.error(f"解析响应时发生错误: {e}") log.error(f"用户的提示: {prompt}") log.error(f"模型的响应: {response_message}") log.info("向用户返回一个安全的响应。") response_data = { "intent": False, "answer": response_message } return response_data def verify_end_conversation(self): """ 通过检查用户的最后一条消息和助手的最后一条消息来验证对话是否已结束。 """ pass def verify_goal_conversation(self, model: str, **kwargs): """ 通过检查对话历史记录来验证对话是否已达到目标。 按照指令的要求格式化响应。 """ messages = self.messages.copy() messages.append(self.instructions) retry_exceptions = (APIError, APIConnectionError, RateLimitError) for _ in range(3): try: response = openai.ChatCompletion.create( model = model, messages = messages, **kwargs ) break except retry_exceptions as e: if _ == 2: log.error(f"最后一次尝试失败,发生异常: {e}.") raise retry_time = getattr(e, 'retry_after', 3) log.error(f"发生异常: {e}。{retry_time}秒后重试...") time.sleep(retry_time) response_message = response.choices[0].message["content"] try: response_data = json.loads(response_message) if response_data.get('summary') is None: raise ValueError("模型的响应无效。缺少摘要。") except ValueError as e: log.error(f"解析响应时发生错误: {e}") log.error(f"模型的响应: {response_message}") log.info("向用户返回一个安全的响应。") raise return response_data关于集成模块的一些说明:
- OpenAI密钥被定义为名为“OPENAI_API_KEY”的环境变量,我们应该下载此密钥并在终端或使用python-dotenv库中定义它。
- 与GPT模型集成的方法有两种,一种是用于聊天端点(
answer_to_prompt),另一种是用于完成端点(answer_to_simple_prompt)。我们将重点介绍第一种的使用方法。 - 有一种方法可以检查对话的目标——
verify_goal_conversation,它只需按照代理的指示并创建一个总结。
设计(记忆)微服务
最好的练习是设计并绘制一个图表,以可视化服务需要做的事情,包括与之交互时的参与者及其动作。让我们从简单的术语描述我们的应用程序开始:
- 我们的微服务是一个提供人工智能代理的供应商,他们是某个主题的专家,并且预期能够根据出站消息和提示进行对话。
- 我们的代理可以进行多个对话,并且带有要持久化的记忆,这意味着无论与代理互动的客户的会话如何,它们都必须能够保留对话历史记录。
- 代理应在创建时接收清晰的指示,以便在对话过程中相应地做出回应。
- 对于编程集成,代理还应遵循预期的响应格式。
我们的设计如下图所示:
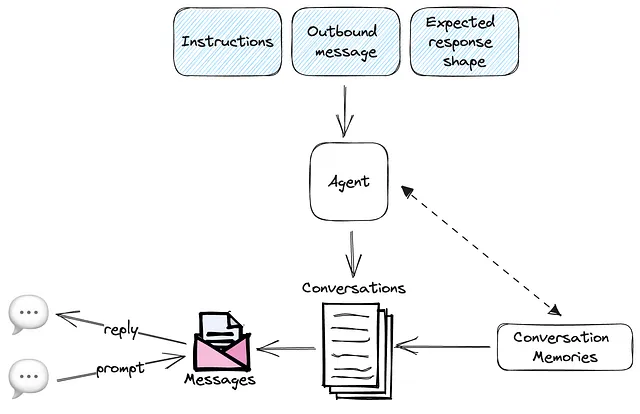
通过这个简单的图表,我们知道我们的微服务需要实现负责以下特定任务的方法:
- 代理的创建和指示定义
- 对话的开始和对话历史的保存
- 与代理聊天
我们将按照它们的顺序编写这些功能,但在深入研究之前,我们将构建应用程序的框架。
应用程序框架
为了开始开发,我们首先构建FastAPI应用程序的框架。应用程序框架包括主应用程序脚本、数据库配置、处理脚本和路由模块等基本组件。主脚本用作应用程序的入口点,在其中设置FastAPI实例。
主文件
让我们在agents文件夹中创建/打开main.py文件,并输入以下代码,它只是定义了一个根端点。
from fastapi import FastAPIfrom agentsfwrk.logger import setup_applevel_loggerlog = setup_applevel_logger(file_name = 'agents.log')app = FastAPI()@app.get("/")async def root(): return {"message": "Hello there conversational ai user!"}数据库配置
然后,我们创建/打开名为database.py的数据库配置脚本,用于建立与本地数据库的连接,以存储和检索对话上下文。为了简单起见,我们将首先使用本地SQLite,但您可以根据您的环境尝试其他数据库。
from sqlalchemy import create_enginefrom sqlalchemy.ext.declarative import declarative_basefrom sqlalchemy.orm import sessionmakerSQLALCHEMY_DATABASE_URL = "sqlite:///agents.db"engine = create_engine( SQLALCHEMY_DATABASE_URL, connect_args = {"check_same_thread": False})SessionLocal = sessionmaker(autocommit = False, autoflush = False, bind = engine)Base = declarative_base()API路由
最后,我们定义处理传入HTTP请求的路由模块,包括负责处理用户交互的端点。让我们创建api文件夹,并创建/打开routes.py文件,并粘贴以下代码。
from typing import Listfrom fastapi import APIRouter, Depends, HTTPExceptionfrom sqlalchemy.orm import Sessionimport agents.api.schemasimport agents.modelsfrom agents.database import SessionLocal, enginefrom agentsfwrk import integrations, loggerlog = logger.get_logger(__name__)agents.models.Base.metadata.create_all(bind = engine)# 路由的基本信息router = APIRouter( prefix = "/agents", tags = ["Chat"], responses = {404: {"description": "Not found"}})# 依赖项:用于在我们的端点中获取数据库def get_db(): db = SessionLocal() try: yield db finally: db.close()# 路由的根端点[email protected]("/")async def agents_root(): return {"message": "Hello there conversational ai!"}有了这个结构化的框架,我们准备开始编写我们设计的应用程序。
创建代理并分配指令
在本节中,我们将重点实现“创建代理”端点。该端点使用户能够启动新的对话并与代理进行交互,为代理提供上下文和一套指令,供其在整个对话过程中遵循。我们将首先介绍此过程的两个数据模型:一个用于数据库,另一个用于API。我们将使用Pydantic来定义我们的数据模型。在api文件夹中创建/打开schemas.py文件,并定义代理基类、代理创建和代理数据模型。
from datetime import datetimefrom typing import List, Optionalfrom pydantic import BaseModelclass AgentBase(BaseModel): # <-- 基本模型 context: str # <-- 我们的代理上下文 first_message: str # <-- 我们的代理将使用第一条消息接触用户。 response_shape: str # <-- 期望的每个代理与用户交互的响应的形状(用于编程通信) instructions: str # <-- 代理应遵循的一套指令。class AgentCreate(AgentBase): # <-- 创建数据模型 passclass Agent(AgentBase): # <-- 代理数据模型 id: str timestamp: datetime = datetime.utcnow() class Config: orm_mode = True代理数据模型中的字段如下所述:
- 上下文:代理的整体上下文。
- 第一条消息:我们的代理旨在与用户开始对话。可以简单地是“你好,我能帮你什么忙?”或者是“嗨,你请求一个代理来帮你找到关于股票的信息,是吗?”。
- 响应形状:该字段主要用于指定我们代理的响应输出格式,并应用于将LLM的文本输出转换为期望的编程通信形状。例如,我们可能希望指定我们的代理应将响应包装在一个名为
response的JSON格式中,即{'response': "string"}。 - 指令:此字段包含每个代理在整个对话过程中应遵循的指令和准则,例如“在每次交互期间收集以下实体[e1,e2,e3,…]”或“回复用户,直到他不再对对话感兴趣”或“在需要时不偏离主要话题并将对话驱回主要目标”。
现在我们继续打开models.py文件,我们将在其中编写属于代理实体的数据库表。
from sqlalchemy import Column, ForeignKey, String, DateTime, JSONfrom sqlalchemy.orm import relationshipfrom datetime import datetimefrom agents.database import Baseclass Agent(Base): __tablename__ = "agents" id = Column(String, primary_key = True, index = True) timestamp = Column(DateTime, default = datetime.utcnow) context = Column(String, nullable = False) first_message = Column(String, nullable = False) response_shape = Column(JSON, nullable = False) instructions = Column(String, nullable = False)这段代码与Pydantic模型非常相似,它定义了我们数据库中代理的表。
有了我们的两个数据模型,我们准备实现代理的创建。为此,我们将首先修改routes.py文件并添加端点:
@router.post("/create-agent", response_model = agents.api.schemas.Agent)async def create_agent(campaign: agents.api.schemas.AgentCreate, db: Session = Depends(get_db)): """ 创建代理 """ log.info(f"创建代理") # db_agent = create_agent(db, agent) log.info(f"创建的代理id为:{db_agent.id}") return db_agent我们需要创建一个新的函数,该函数从请求中接收一个代理对象并将其创建到数据库中。为此,我们将创建/打开crud.py文件,该文件将保存与数据库的所有交互(创建、读取、更新、删除)。
# crud.py
import uuid
from sqlalchemy.orm import Session
from agents import models
from agents.api import schemas
def create_agent(db: Session, agent: schemas.AgentCreate):
"""在数据库中创建一个代理"""
db_agent = models.Agent(
id = str(uuid.uuid4()),
context = agent.context,
first_message = agent.first_message,
response_shape = agent.response_shape,
instructions = agent.instructions
)
db.add(db_agent)
db.commit()
db.refresh(db_agent)
return db_agent使用我们创建的函数,我们现在可以返回到routes.py,导入crud模块,并在端点方法中使用它。
import agents.crud
@router.post("/create-agent", response_model = agents.api.schemas.Agent)
async def create_agent(agent: agents.api.schemas.AgentCreate, db: Session = Depends(get_db)):
"""创建一个代理端点"""
log.info(f"Creating agent: {agent.json()}")
db_agent = agents.crud.create_agent(db, agent)
log.info(f"Agent created with id: {db_agent.id}")
return db_agent现在让我们返回main.py文件,并添加“agents”路由。更改如下:
# main.py
from fastapi import FastAPI
from agents.api.routes import router as ai_agents
from agentsfwrk.logger import setup_applevel_logger
log = setup_applevel_logger(file_name = 'agents.log')
app = FastAPI()
app.include_router(router = ai_agents)
@app.get("/")
async def root():
return {"message": "Hello there conversational ai user!"}让我们测试这个功能。首先,我们需要将服务安装为Python包,然后在端口8000上启动应用程序。
# 从项目根目录运行
$ pip install -e .
# 启动应用程序
$ uvicorn agents.main:app --host 0.0.0.0 --port 8000 --reload访问http://0.0.0.0:8000/docs,在此处你将看到Swagger UI和用于测试的端点。提交有效载荷并检查输出。

我们将继续开发我们的应用程序,但测试第一个端点是进展的一个好迹象。
创建对话并保留对话历史
我们的下一步是允许用户与代理进行交互。我们希望用户与特定代理进行交互,因此我们需要将代理的ID与用户的第一次交互消息一起传递。让我们对代理数据模型进行一些修改,以便每个代理都可以拥有多个对话,引入“Conversation”实体。打开schemas.py文件并添加以下模型:
class ConversationBase(BaseModel): # <-- 对话的基础,它们必须属于一个代理
agent_id: str
class ConversationCreate(ConversationBase): # <-- 对话创建对象
pass
class Conversation(ConversationBase): # <-- 对话对象
id: str
timestamp: datetime = datetime.utcnow()
class Config:
orm_mode = True
class Agent(AgentBase): # <-- 代理数据模型
id: str
timestamp: datetime = datetime.utcnow()
conversations: List[Conversation] = [] # <-- 注意:我们将对话作为对话对象列表添加进来
class Config:
orm_mode = True请注意,我们修改了Agent数据模型并添加了对话。这样每个代理都可以根据我们的设计拥有多个对话。
我们需要修改数据库对象并在数据库模型脚本中包含对话表。打开models.py文件,并修改代码如下:
# models.py
class Agent(Base):
__tablename__ = "agents"
id = Column(String, primary_key = True, index = True)
timestamp = Column(DateTime, default = datetime.utcnow)
context = Column(String, nullable = False)
first_message = Column(String, nullable = False)
response_shape = Column(JSON, nullable = False)
instructions = Column(String, nullable = False)
conversations = relationship("Conversation", back_populates = "agent") # <-- 注意:我们将对话关系添加到代理表中
class Conversation(Base):
__tablename__ = "conversations"
id = Column(String, primary_key = True, index = True)
agent_id = Column(String, ForeignKey("agents.id"))
timestap = Column(DateTime, default = datetime.utcnow)
agent = relationship("Agent", back_populates = "conversations") # <-- 我们添加了对话和代理之间的关系注意我们在agents表中添加了每个代理的对话关系,并且在conversations表中添加了代理与对话之间的关系。
我们将创建一组CRUD函数来通过它们的ID检索代理和对话,这将帮助我们制定创建对话并保留其历史记录的过程。让我们打开crud.py文件并添加以下函数:
def get_agent(db: Session, agent_id: str): """ 通过ID获取代理 """ return db.query(models.Agent).filter(models.Agent.id == agent_id).first()def get_conversation(db: Session, conversation_id: str): """ 通过ID获取对话 """ return db.query(models.Conversation).filter(models.Conversation.id == conversation_id).first()def create_conversation(db: Session, conversation: schemas.ConversationCreate): """ 创建对话 """ db_conversation = models.Conversation( id = str(uuid.uuid4()), agent_id = conversation.agent_id, ) db.add(db_conversation) db.commit() db.refresh(db_conversation) return db_conversation这些新函数将在应用程序的正常工作流程中帮助我们,我们现在可以通过ID获取代理,通过ID获取对话,并通过提供一个可选的ID和应该持有对话的代理ID来创建对话。
我们可以继续创建一个创建对话的端点。打开routes.py并添加以下代码:
@router.post("/create-conversation", response_model = agents.api.schemas.Conversation)async def create_conversation(conversation: agents.api.schemas.ConversationCreate, db: Session = Depends(get_db)): """ 创建与代理关联的对话 """ log.info(f"创建分配给代理ID的对话: {conversation.agent_id}") db_conversation = agents.crud.create_conversation(db, conversation) log.info(f"创建对话,ID为: {db_conversation.id}") return db_conversation有了这个方法,我们离拥有一个真正的对话端点还差一步,我们将在下一步中进行审查。
当我们初始化代理时,我们在这里需要做出一个区分,我们可以创建一个对话而不触发双向消息交换,或者是在调用“与代理聊天”端点时触发对话的创建。这在编排微服务外部的工作流程中提供了一些灵活性,在某些情况下,您可能希望初始化代理,预先启动与客户的对话,并且当消息开始进来时,开始保留消息的历史记录。

重要提示:如果您按照本指南逐步操作并在此步骤中看到与数据库模式相关的错误,那是因为我们没有在每次修改模式时对数据库应用迁移,所以确保关闭应用程序(退出终端命令)并删除运行时创建的
agents.db文件。您将需要再次运行每个端点并记录ID。
与代理聊天
我们将在应用程序中引入最后一种实体类型,即Message实体。它负责对客户消息和代理消息之间的交互进行建模(双向消息交换)。我们还将添加用于定义端点响应结构的API数据模型。让我们先创建数据模型和API响应类型;打开schemas.py文件并修改代码:
########################################### 内部数据模型##########################################class MessageBase(BaseModel): # <-- 每个消息由用户/客户消息和代理消息组成 user_message: str agent_message: strclass MessageCreate(MessageBase): passclass Message(MessageBase): # <-- Message实体的数据模型 id: str timestamp: datetime = datetime.utcnow() conversation_id: str class Config: orm_mode = True########################################### API数据模型##########################################class UserMessage(BaseModel): conversation_id: str message: strclass ChatAgentResponse(BaseModel): conversation_id: str response: str我们现在需要在数据库模型脚本中添加数据模型,该模型表示数据库中的表。打开models.py文件并按如下方式进行修改:
# models.pyclass Conversation(Base): __tablename__ = "conversations" id = Column(String, primary_key = True, index = True) agent_id = Column(String, ForeignKey("agents.id")) timestap = Column(DateTime, default = datetime.utcnow) agent = relationship("Agent", back_populates = "conversations") messages = relationship("Message", back_populates = "conversation") # <-- We define the relationship between the conversation and the multiple messages in them.class Message(Base): __tablename__ = "messages" id = Column(String, primary_key = True, index = True) timestamp = Column(DateTime, default = datetime.utcnow) user_message = Column(String) agent_message = Column(String) conversation_id = Column(String, ForeignKey("conversations.id")) # <-- A message belongs to a conversation conversation = relationship("Conversation", back_populates = "messages") # <-- We define the relationship between the messages and the conversation.请注意,我们修改了Conversations表以定义消息与对话之间的关系,并创建了一个新表,该表表示应属于对话的交互(消息交换)。
我们现在将添加一个新的CRUD函数来与数据库交互并为对话创建消息。让我们打开crud.py文件并添加以下函数:
def create_conversation_message(db: Session, message: schemas.MessageCreate, conversation_id: str): """ 为对话创建消息 """ db_message = models.Message( id = str(uuid.uuid4()), user_message = message.user_message, agent_message = message.agent_message, conversation_id = conversation_id ) db.add(db_message) db.commit() db.refresh(db_message) return db_message现在我们准备构建最终且最有趣的端点,即chat-agent端点。让我们打开routes.py文件,并随代码一起进行实现,因为我们将在此过程中实现一些处理函数。
@router.post("/chat-agent", response_model = agents.api.schemas.ChatAgentResponse)async def chat_completion(message: agents.api.schemas.UserMessage, db: Session = Depends(get_db)): """ 根据客户端的消息从GPT模型获取响应,使用聊天完成端点。 响应是一个带有以下结构的JSON对象: ``` { "conversation_id": "string", "response": "string" } ``` """ log.info(f"User conversation id: {message.conversation_id}") log.info(f"User message: {message.message}") conversation = agents.crud.get_conversation(db, message.conversation_id) if not conversation: # 如果没有对话,我们可以选择即时创建一个,或者引发异常。 # 无论选择哪个,确保在必要时取消注释。 # 选项1: # conversation = agents.crud.create_conversation(db, message.conversation_id) # 选项2: return HTTPException( status_code = 404, detail = "对话未找到,请先创建对话。" ) log.info(f"对话id:{conversation.id}")在此端点的此部分中,我们正在确保创建或引发异常(如果对话不存在)。下一步是准备将发送到OpenAI的数据,为此,我们将在processing.py文件中创建一组处理函数,用于构建上下文、第一条消息、指令和LLM的预期响应结构。
# processing.pyimport json######################################### 聊天属性########################################def craft_agent_chat_context(context: str) -> dict: """ 为聊天端点构建代理使用的上下文。 """ agent_chat_context = { "role": "system", "content": context } return agent_chat_contextdef craft_agent_chat_first_message(content: str) -> dict: """ 为聊天端点构建代理的第一条消息。 """ agent_chat_first_message = { "role": "assistant", "content": content } return agent_chat_first_messagedef craft_agent_chat_instructions(instructions: str, response_shape: str) -> dict: """ 为聊天端点构建代理使用的指令。 """ agent_instructions = { "role": "user", "content": instructions + f"\n\n按照符合RFC8259标准的JSON格式,形状为:{json.dumps(response_shape)},没有偏差。" } return agent_instructions请注意最后一个函数,该函数期望在创建代理时定义的response_shape,这个输入将在对话过程中附加到LLM中,并指导代理遵循指南并将响应返回为JSON对象。
让我们回到routes.py文件并完成我们的终端实现:
# 从处理模块中导入新的模块。from agents.processing import ( craft_agent_chat_context, craft_agent_chat_first_message, craft_agent_chat_instructions)@router.post("/chat-agent", response_model = agents.api.schemas.ChatAgentResponse)async def chat_completion(message: agents.api.schemas.UserMessage, db: Session = Depends(get_db)): """ 使用聊天完成终端从客户端获取来自GPT模型的响应。 响应是一个具有以下结构的JSON对象: ``` { "conversation_id": "string", "response": "string" } ``` """ log.info(f"用户对话ID:{message.conversation_id}") log.info(f"用户消息:{message.message}") conversation = agents.crud.get_conversation(db, message.conversation_id) if not conversation: # 如果没有对话,我们可以选择即时创建一个或者抛出异常。 # 无论您选择哪个选项,在必要时确保取消注释。 # 选项1: # conversation = agents.crud.create_conversation(db, message.conversation_id) # 选项2: return HTTPException( status_code = 404, detail = "未找到对话。请先创建对话。" ) log.info(f"对话ID:{conversation.id}") # 注意:我们首先构建上下文,并将聊天消息作为列表传递给它, # 将第一条消息(代理的方法)附加到它上面。 context = craft_agent_chat_context(conversation.agent.context) chat_messages = [craft_agent_chat_first_message(conversation.agent.first_message)] # 注意:将所有消息追加到对话中,直到代理的最后一次交互 # 如果没有消息,这没有任何效果。 # 否则,我们按时间戳排序每个消息。 hist_messages = conversation.messages hist_messages.sort(key = lambda x: x.timestamp, reverse = False) if len(hist_messages) > 0: for mes in hist_messages: log.info(f"对话历史消息:{mes.user_message} | {mes.agent_message}") chat_messages.append( { "role": "user", "content": mes.user_message } ) chat_messages.append( { "role": "assistant", "content": mes.agent_message } ) # 注意:我们可以通过简单地添加规则来控制对话的长度。 if len(hist_messages) > 10: # 优雅地结束对话。 log.info("对话历史太长,结束对话。") api_response = agents.api.schemas.ChatAgentResponse( conversation_id = message.conversation_id, response = "此对话已结束,再见。" ) return api_response # 将消息发送给AI代理并获取响应 service = integrations.OpenAIIntegrationService( context = context, instruction = craft_agent_chat_instructions( conversation.agent.instructions, conversation.agent.response_shape ) ) service.add_chat_history(messages = chat_messages) response = service.answer_to_prompt( # 我们可以测试不同的OpenAI模型。 model = "gpt-3.5-turbo", prompt = message.message, # 我们还可以测试不同的参数。 temperature = 0.5, max_tokens = 1000, frequency_penalty = 0.5, presence_penalty = 0 ) log.info(f"代理响应:{response}") # 准备响应给用户 api_response = agents.api.schemas.ChatAgentResponse( conversation_id = message.conversation_id, response = response.get('answer') ) # 将交互保存到数据库 db_message = agents.crud.create_conversation_message( db = db, conversation_id = conversation.id, message = agents.api.schemas.MessageCreate( user_message = message.message, agent_message = response.get('answer'), ), ) log.info(f"对话消息ID {db_message.id} 已保存到数据库") return api_responseVoilà!这是我们最终的终端实现,如果我们查看代码中添加的注释,我们可以看到这个过程非常简单:
- 我们确保会话存在于我们的数据库中(或者我们创建一个)
- 我们从数据库中为代理人制定上下文和指令
- 我们通过提取对话历史来利用代理人的“记忆”
- 最后,我们通过OpenAI的GPT-3.5 Turbo模型请求代理人的回复,并将回复返回给客户端。
本地测试我们的代理人
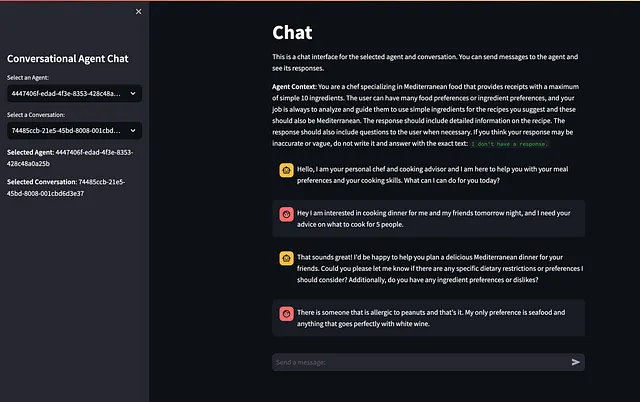
现在我们准备测试我们微服务的完整工作流程,我们将首先打开终端并输入 uvicorn agents.main:app — host 0.0.0.0 — port 8000 — reload 来启动应用程序。接下来,我们将通过访问 http://0.0.0.0:8000/docs 来导航到我们的Swagger UI,并提交以下请求:
- 创建代理人:提供一个您想要测试的有效载荷。我将提交以下内容:
{ "context": "您是一位专门从事地中海食品的厨师,提供最多包含10种简单成分的食谱。用户可以有许多食物偏好或成分偏好,您的工作始终是分析和引导他们使用简单成分来制作您建议的食谱,并且这些食谱也应该是地中海风格的。回复应包括有关食谱的详细信息。在必要时,回复还应提出问题给用户。如果您认为您的回复可能不准确或含糊不清,请不要写,以精确的文本回答:'我没有回答。'", "first_message": "你好,我是您的私人厨师和烹饪顾问,我在这里帮助您处理您的餐食偏好和烹饪技巧。今天有什么我可以帮您的吗?", "response_shape": "{'recipes': '包含食谱名称的字符串列表', 'ingredients': '食谱中使用的成分列表', 'summary': '对话摘要的字符串'}", "instructions": "运行对话消息并丢弃与烹饪无关的任何消息。专注于提取对话中提到的食谱,并对每个食谱提取成分列表。在被问到时,确保提供对话摘要。"}- 创建对话:将对话分配给您从上一个响应中获取到的
agent_id。
{ "agent_id": "替换为您刚刚创建的代理人的UUID。"}- 通过出站消息与我们的代理人进行交谈:我们的代理人将通过提问或向我们发送消息来初始化对话。我们将通过提交一条消息来跟随对话 – 我将使用这个:
{ "conversation_id": "74485ccb-21e5-45bd-8008-001cbd6d3e37", "message": "嗨,我想为我和我的朋友明天晚上做晚餐,我需要你建议我们给5个人做什么菜。"}
我们的代理人回复了我们,并且我们可以以自然的方式继续这个对话。
# 我们的问题{ "conversation_id": "74485ccb-21e5-45bd-8008-001cbd6d3e37", "message": "有人对花生过敏,就只有这一个。我唯一的偏好是海鲜,以及与白葡萄酒搭配得完美的任何菜。"}# 我们代理人的回复{ "conversation_id": "74485ccb-21e5-45bd-8008-001cbd6d3e37", "response": "太好了!我们肯定可以在菜单中考虑到花生过敏,并将海鲜融入其中。我们从一道清爽的开胃菜——柠檬大蒜烤虾串开始如何?这道菜简单美味,与白葡萄酒搭配得很好。\n\n这是柠檬大蒜烤虾串的食谱:\n\n成分:\n1. 1磅大虾,去壳和去肠\n2. 2瓣大蒜,切碎\n3. 2汤匙新鲜柠檬汁\n4. 2汤匙橄榄油\n5. 盐和胡椒适量\n6. 木签,浸泡在水中30分钟\n\n制作方法:\n1. 将烧烤架预热至VoAGI高温。\n2. 在一个碗中,将切碎的大蒜、柠檬汁、橄榄油、盐和胡椒混合在一起。\n3. 将虾串在浸泡过的木签上。\n4. 两面刷上大蒜柠檬腌料。\n5. 将虾串放在预热的烤架上,每面烤约2-3分钟,直到虾变粉红色和不透明为止。\n6. 从烤架上取出,热食。\n\n作为主菜,来一份地中海风格的烤三文鱼如何?它味道浓郁,健康,与白葡萄酒搭配得很好。\n\n这是地中海烤三文鱼的食谱:\n\n成分:\n1. 1磅三文鱼片\n2. 2汤匙橄榄油\n3. 2瓣大蒜,切碎\n4. 1茶匙干牛至\n5. 半个柠檬的汁\n6. 盐和胡椒适量\n\n制作方法:\n1. 将烤箱预热至375°F(190°C)。\n2. 将三文鱼片放在铺有烘焙纸或锡箔纸的烤盘上。\n3. 在一个小碗中,混合橄榄油、切碎的大蒜、干牛至、柠檬汁、盐和胡椒。\n4. 将混合物刷在三文鱼片上,确保均匀涂抹。\n5. 将三文鱼放入预热的烤箱中烤约12-15分钟,或者用叉子轻松剥离。\n6. 从烤箱中取出,静置几分钟后再食用。\n\n为了搭配这顿饭,您可以加一份烤地中海蔬菜作为配菜。它是您晚餐的丰富多彩和尽情地与代码和您的新代理玩耍吧。在下一部分中,我将重点介绍如何部署此服务。
部署周期
我们将在云中的容器环境下部署我们的应用,例如 Kubernetes、Azure 容器服务或 AWS 弹性容器服务。在这里,我们将创建一个 Docker 镜像并上传我们的代码,以便在其中一个环境中运行它。请打开我们在开始时创建的 Dockerfile,并粘贴以下代码:
# DockerfileFROM python:3.10-slim-bullseye# 设置工作目录WORKDIR /app# 将项目文件复制到容器中COPY . .# 使用 setup.py 安装软件包RUN pip install -e .# 安装依赖项RUN pip install pip -U && \ pip install --no-cache-dir -r requirements.txt# 设置环境变量ARG OPENAI_API_KEYENV OPENAI_API_KEY=$OPENAI_API_KEY# 公开必要的端口EXPOSE 8000# 运行应用程序# CMD ["uvicorn", "agents.main:app", "--host", "0.0.0.0", "--port", "8000"]
Dockerfile 安装应用程序,然后通过被注释掉的 CMD 运行它。如果您想将其作为独立应用程序在本地运行,请取消注释该命令;但对于其他服务(如 Kubernetes),这将在定义部署或 Pod 时在清单的命令部分中定义。
构建镜像,等待构建完成,然后通过运行以下命令来测试它:
# 构建镜像$ docker build - build-arg OPENAI_API_KEY=<替换为您的 OpenAI 密钥> -t agents-app .# 使用代理应用程序的命令运行容器(使用 -d 标志进行分离运行)$ docker run -p 8000:8000 agents-app uvicorn agents.main:app --host 0.0.0.0 --port 8000# 输出INFO: 启动服务器进程 [1]INFO: 等待应用程序启动.INFO: 应用程序启动完成.INFO: Uvicorn 正在运行,地址为 http://0.0.0.0:8000(按 CTRL+C 退出)INFO: 172.17.0.1:41766 - "GET / HTTP/1.1" 200 OKINFO: 172.17.0.1:41766 - "GET /favicon.ico HTTP/1.1" 404 Not FoundINFO: 172.17.0.1:41770 - "GET /docs HTTP/1.1" 200 OKINFO: 172.17.0.1:41770 - "GET /openapi.json HTTP/1.1" 200 OK
太棒了,您已经准备好在部署环境中使用该应用程序了。
最后,我们将尝试将此微服务与一个前端应用程序集成起来,通过调用内部的端点来提供代理和对话,这是使用这种架构构建和交互服务的常见方式。
使用周期
我们可以以多种方式使用这项新服务,我将只专注于构建一个前端应用程序,通过调用代理的端点使用户可以通过界面进行交互。我们将使用 Streamlit 来实现这一点,因为它是使用 Python 快速创建前端的简单方法。
重要提示:我在我们的代理服务中添加了其他实用工具,您可以直接从代码库中复制。在 crud.py 模块和 api/routes.py 路由中搜索 get_agents()、get_conversations() 和 get_messages()。
- 安装 Streamlit 并将其添加到我们的 requirements.txt 中。
# 如果需要,请固定版本$ pip install streamlit==1.25.0# 我们的 requirements.txt(添加了 streamlit)$ cat requirements.txtfastapi==0.95.2ipykernel==6.22.0jupyter-bokeh==2.0.2jupyterlab==3.6.3openai==0.27.6pandas==2.0.1sqlalchemy-orm==1.2.10sqlalchemy==2.0.15streamlit==1.25.0uvicorn<0.22.0,>=0.21.1
- 创建应用程序,首先在我们的
src文件夹中创建一个名为frontend的文件夹。创建一个名为main.py的新文件,并放置以下代码。
import streamlit as stimport requestsAPI_URL = "http://0.0.0.0:8000/agents" # 我们将使用本地URL和端口来定义这个示例中的微服务def get_agents(): """ 从API中获取可用代理的列表 """ response = requests.get(API_URL + "/get-agents") if response.status_code == 200: agents = response.json() return agents return []def get_conversations(agent_id: str): """ 获取具有给定ID的代理的对话列表 """ response = requests.get(API_URL + "/get-conversations", params = {"agent_id": agent_id}) if response.status_code == 200: conversations = response.json() return conversations return []def get_messages(conversation_id: str): """ 获取具有给定ID的对话的消息列表 """ response = requests.get(API_URL + "/get-messages", params = {"conversation_id": conversation_id}) if response.status_code == 200: messages = response.json() return messages return []def send_message(agent_id, message): """ 向具有给定ID的代理发送一条消息 """ payload = {"conversation_id": agent_id, "message": message} response = requests.post(API_URL + "/chat-agent", json = payload) if response.status_code == 200: return response.json() return {"response": "Error"}def main(): st.set_page_config(page_title = "🤗💬 AIChat") with st.sidebar: st.title("对话代理聊天") # 下拉框选择代理 agents = get_agents() agent_ids = [agent["id"] for agent in agents] selected_agent = st.selectbox("选择代理:", agent_ids) for agent in agents: if agent["id"] == selected_agent: selected_agent_context = agent["context"] selected_agent_first_message = agent["first_message"] # 下拉框选择对话 conversations = get_conversations(selected_agent) conversation_ids = [conversation["id"] for conversation in conversations] selected_conversation = st.selectbox("选择对话:", conversation_ids) if selected_conversation is None: st.write("请从下拉列表中选择一个对话。") else: st.write(f"**选择的代理**: {selected_agent}") st.write(f"**选择的对话**: {selected_conversation}") # 显示聊天消息 st.title("聊天") st.write("这是一个用于所选代理和对话的聊天界面。您可以向代理发送消息并查看其回复。") st.write(f"**代理上下文**: {selected_agent_context}") messages = get_messages(selected_conversation) with st.chat_message("assistant"): st.write(selected_agent_first_message) for message in messages: with st.chat_message("user"): st.write(message["user_message"]) with st.chat_message("assistant"): st.write(message["agent_message"]) # 用户提供的提示 if prompt := st.chat_input("发送消息:"): with st.chat_message("user"): st.write(prompt) with st.spinner("思考中..."): response = send_message(selected_conversation, prompt) with st.chat_message("assistant"): st.write(response["response"])if __name__ == "__main__": main()
下面的代码通过API调用连接到我们的代理微服务,允许用户选择代理和对话,并与代理进行聊天,类似于ChatGPT提供的功能。让我们通过打开另一个终端(确保您的代理微服务在端口8000上运行)并键入$ streamlit run src/frontend/main.py来运行此应用程序,然后您就可以开始使用了!
未来改进和结论
未来改进
我们的对话代理与内存微服务相结合有许多令人兴奋的机会。这些改进引入了高级功能,可以扩展用户交互并扩大应用程序或整体系统的范围。
- 增强的错误处理:为了确保强大可靠的对话,我们可以实现代码来优雅地处理意外的用户输入、API失败——处理OpenAI或其他服务,以及可能在实时交互过程中出现的问题。
- 集成缓冲区和对话总结:通过LangChain框架实现的缓冲区的集成,有可能优化令牌管理,使对话能够在更长的时间段内进行,而不会遇到令牌限制。此外,结合对话总结,允许用户回顾正在进行的讨论,有助于保持上下文,并提高整体用户体验。注意代理指令和响应形状,以便在我们的代码中轻松扩展。
- 数据感知的应用:通过将我们的代理模型连接到其他数据源(如内部数据库),我们可以创建具有独特和内部知识的代理。这涉及到训练或集成模型,能够理解和回应基于对您组织独特数据和信息的理解的复杂查询——请查看LangChain的数据连接模块。
- 模型多样化:虽然我们只使用了OpenAI的GPT-3.5模型,但语言模型提供商的领域正在迅速扩大。测试其他供应商的模型可以进行比较分析,揭示优点和缺点,并使我们能够选择最适合特定用例的模型——尝试使用不同的LLM集成,如HuggingFace、Cohere、Google等。
结论
我们开发了一个由OpenAI GPT模型驱动的智能代理微服务,并证明了这些代理可以具备存储在客户会话之外的记忆。通过采用这种架构,我们打开了无限的可能性。从上下文感知的对话到与复杂语言模型的无缝集成,我们的技术栈已经能够为我们的产品提供新的功能。
这个实现及其明显的好处清楚地表明,使用人工智能取决于具备正确工具和方法。使用AI驱动的代理不仅仅是关于快速工程,而是关于我们如何更有效地构建工具并与之互动,提供个性化的体验,并以AI和软件工程提供的精确度和准确性解决复杂任务。因此,无论您是在构建客户支持系统、销售虚拟助手、个人厨师,还是其他全新的东西,记住,旅程始于一行代码和丰富的想象力——可能性是无限的。
本文的完整代码在GitHub上——您可以在LinkedIn上找到我,随时与我联系!






