在Amazon SageMaker Studio中使用Amazon SageMaker JumpStart的稳定扩散XL
使用Amazon SageMaker JumpStart的稳定扩散XL
今天我们很高兴地宣布,稳定扩散 XL 1.0(SDXL 1.0)现已通过 Amazon SageMaker JumpStart 提供给客户。SDXL 1.0 是 Stability AI 最新的图像生成模型。SDXL 1.0 增强功能包括原生的 1024 像素图像生成,支持多种宽高比。它专为专业使用设计,并经过高分辨率逼真图像的校准。SDXL 1.0 提供了各种预设的艺术风格,可在市场营销、设计和图像生成等行业中使用。您可以轻松尝试这些模型,并在 SageMaker JumpStart 中使用它们,SageMaker JumpStart 是一个机器学习(ML)中心,提供算法、模型和 ML 解决方案的访问,让您快速开始 ML。
在本文中,我们将介绍如何通过 SageMaker JumpStart 使用 SDXL 1.0 模型。
稳定扩散 XL 1.0(SDXL 1.0)是什么
SDXL 1.0 是稳定扩散的进化版,是图像生成领域的下一个前沿。SDXL 能够以各种艺术风格生成复杂概念的惊人图像,包括逼真的照片级图像,质量超过目前可用的最佳图像模型。与原始的稳定扩散系列一样,SDXL 高度可定制(以参数为基础),可以在 Amazon SageMaker 实例上部署。
下面的狮子图片是使用 SDXL 1.0 生成的,使用了一个简单的提示,我们将在本文后面探讨。

SDXL 1.0 模型包括以下亮点:
- 表达自由 – 一流的逼真度,以及在几乎任何艺术风格中生成高质量的艺术作品的能力。不同的图像是由模型赋予的特定感觉而不产生的,确保了绝对的风格自由。
- 艺术智能 – 一流的能力,能够生成对于图像模型而言难以渲染的概念,例如手和文本,或者空间排列的物体和人物(例如,蓝盒子上面的红盒子)。
- 更简单的提示 – 与其他生成图像模型不同,SDXL 只需要几个词就能创建复杂、详细和美观的图像。不再需要段落的限定词。
- 更准确 – SDXL 中的提示不仅简单,而且更符合提示的意图。SDXL 改进的 CLIP 模型能够有效地理解文本,使得像“红色广场”和“红色的广场”这样的概念被认为是不同的。这种准确性使得在使用更高级功能或进行精细调整之前,通过文本直接获得完美的图像变得更加容易。
什么是 SageMaker JumpStart
使用 SageMaker JumpStart,机器学习从业者可以从广泛的最先进模型中选择,用于内容编写、图像生成、代码生成、问题回答、文案撰写、摘要生成、分类、信息检索等用例。机器学习从业者可以将基础模型部署到专用的 SageMaker 实例中,使用 SageMaker 进行模型训练和部署。SDXL 模型今天可以在 Amazon SageMaker Studio 中发现,并且根据本文撰写时的情况,可在 us-east-1、us-east-2、us-west-2、eu-west-1、ap-northeast-1 和 ap-southeast-2 区域使用。
解决方案概述
在本文中,我们演示如何将 SDXL 1.0 部署到 SageMaker,并使用它生成基于文本和图像的提示的图像。
SageMaker Studio 是一个基于 Web 的集成开发环境(IDE),用于机器学习,可以让您构建、训练、调试、部署和监控机器学习模型。有关如何入门和设置 SageMaker Studio 的更多详细信息,请参阅 Amazon SageMaker Studio。
一旦您进入SageMaker Studio用户界面,访问SageMaker JumpStart并搜索Stable Diffusion XL。选择SDXL 1.0模型卡片,将打开一个示例笔记本。这意味着您只需负责计算费用,没有相关的模型费用。闭合权重的SDXL 1.0提供了SageMaker优化脚本和容器,具有更快的推断时间,并且可以在较小的实例上运行,与开放权重的SDXL 1.0相比。示例笔记本将引导您完成步骤,但我们也会在本文后面讨论如何发现和部署模型。
在接下来的章节中,我们将展示如何使用SDXL 1.0创建具有较短提示的逼真图像,并在图像中生成文本。稳定扩散XL 1.0提供了增强的图像合成和面部生成功能,具有令人惊叹的视觉效果和逼真的美学效果。
稳定扩散XL 1.0参数
以下是SXDL 1.0使用的参数:
- cfg_scale – 扩散过程如何严格遵循提示文本。
- height 和 width – 图像的高度和宽度(以像素为单位)。
- steps – 运行的扩散步数。
- seed – 随机噪声种子。如果提供了种子,生成的图像将是确定性的。
- sampler – 用于扩散过程的采样器,以去噪我们的生成图像。
- text_prompts – 用于生成的文本提示的数组。
- weight – 为每个提示提供特定的权重。
更多信息,请参阅Stability AI的文本到图像文档。
以下代码是与提示一起提供的输入数据示例:
{
"cfg_scale": 7,
"height": 1024,
"width": 1024,
"steps": 50,
"seed": 42,
"sampler": "K_DPMPP_2M",
"text_prompts": [
{
"text": "一张带有罗勒和番茄的新鲜披萨的照片,来自传统烤箱",
"weight": 1
}
]
}本文中的所有示例都基于Stability Diffusion XL 1.0的示例笔记本,该笔记本可以在Stability AI的GitHub存储库中找到。
使用SDXL 1.0生成图像
在以下示例中,我们专注于稳定扩散XL 1.0模型的能力,包括卓越的逼真感、增强的图像合成能力以及生成逼真面部的能力。我们还探索了显著提升的视觉美学效果,产生出具有视觉吸引力的输出。此外,我们演示了使用较短的提示的用法,以更轻松地创建描述性图像。最后,我们展示了图像中的文本现在更易读,进一步丰富了生成内容的整体质量。
以下示例展示了使用简单的提示获取详细图像的方法。只使用提示中的几个词,它就能够创建一个复杂、详细且美观的图像,与提供的提示相似。
text = "一只猫的拿铁艺术照片"
output = deployed_model.predict(GenerationRequest(text_prompts=[TextPrompt(text=text)],
seed=5,
height=640,
width=1536,
sampler="DDIM",
))
decode_and_show(output)
接下来,我们展示了style_preset输入参数的使用,这个参数只在SDXL 1.0上可用。传入style_preset参数可以引导图像生成模型朝特定的风格发展。
一些可用的style_preset参数包括enhance、anime、photographic、digital-art、comic-book、fantasy-art、line-art、analog-film、neon-punk、isometric、low-poly、origami、modeling-compound、cinematic、3d-mode、pixel-art和tile-texture。这些风格预设的列表可能会有所变化,有关更新的最新发布和文档,请参阅最新版本。
在这个例子中,我们使用一个提示来生成一个带有style_preset为origami的茶壶。模型能够根据提供的艺术风格生成高质量的图像。
output = deployed_model.predict(GenerationRequest(text_prompts=[TextPrompt(text="茶壶")],
style_preset="origami",
seed = 3,
height = 1024,
width = 1024
))
让我们尝试一些带有不同提示的风格预设。下一个例子展示了使用style_preset="photographic"和提示语“一只古老而疲倦的狮子真实姿势的肖像”来生成肖像的风格预设。
text = "一只古老而疲倦的狮子真实姿势的肖像"
output = deployed_model.predict(GenerationRequest(text_prompts=[TextPrompt(text=text)],
style_preset="photographic",
seed=111,
height=640,
width=1536,
))
现在让我们尝试使用相同的提示语(“一只古老而疲倦的狮子真实姿势的肖像”),风格预设为橡皮泥。输出图像是一幅独特的图像,它没有受到模型赋予的任何特定感觉的影响,确保了绝对的风格自由。

SDXL 1.0的多提示
正如我们所见,该模型的核心基础之一是通过提示生成图像的能力。SDXL 1.0支持多提示。使用多提示,您可以通过为每个提示分配特定的权重来混合概念。如下生成的图像中可以看到,它有一个丛林背景和高高的亮绿色草地。这个图像是使用以下提示生成的。您可以将其与我们之前的单一提示进行比较。
text1 = "一只古老而疲倦的狮子真实姿势的肖像"
text2 = "丛林和高高的亮绿色草地"
output = deployed_model.predict(GenerationRequest(
text_prompts=[TextPrompt(text=text1),
TextPrompt(text=text2, weight=0.7)],
style_preset="photographic",
seed=111,
height=640,
width=1536,
))
空间感知生成图像和负面提示
接下来,我们来看一下具有详细提示的海报设计。正如我们之前看到的,多提示允许您组合概念以创建新的独特结果。
在这个例子中,提示在主题位置、外貌、期望和周围环境方面非常详细。模型还试图通过负面提示来避免具有扭曲或渲染不良的图像。生成的图像显示了空间排列的物体和主题。
text = “一只可爱的蓬松白猫站在后腿上,好奇地凝视着一个华丽的金色镜子。但在镜子的反射中,猫看到的不是自己,而是一只威武的狮子。镜子在纯白背景上散发着柔和的光芒。”
text = "一只可爱的蓬松白猫站在后腿上,好奇地凝视着一个华丽的金色镜子。但在镜子的反射中,猫看到的不是自己,而是一只威武的狮子。镜子在纯白背景上散发着柔和的光芒。"
negative_prompts = ['扭曲的猫特征', '扭曲的狮子特征', '渲染不良']
output = deployed_model.predict(GenerationRequest(
text_prompts=[TextPrompt(text=text)],
style_preset="enhance",
seed=43,
height=640,
width=1536,
steps=100,
cfg_scale=7,
negative_prompts=negative_prompts
))
让我们尝试另一个示例,保持相同的负面提示,但更改详细提示和样式预设。正如您所看到的,生成的图像不仅在空间上排列对象,还会根据细节进行样式预设的更改,比如华丽的金色镜子和主体的反射。
text = "一只可爱蓬松的白猫站在后腿上,好奇地凝视着一面华丽的金色镜子。在镜子的反射中,猫看到了自己。"
negative_prompts = ['扭曲的猫特征', '扭曲的狮子特征', '渲染不佳']
output = deployed_model.predict(GenerationRequest(
text_prompts=[TextPrompt(text=text)],
style_preset="霓虹朋克",
seed=4343434,
height=640,
width=1536,
steps=150,
cfg_scale=7,
negative_prompts=negative_prompts
))
使用SDXL 1.0生成面部
在这个例子中,我们展示了SDXL 1.0如何创建增强的图像构图和具有真实特征(如手和手指)的面部生成。生成的图像是由AI创建的一个人物形象,手明显抬起。请注意手指和姿势中的细节。否则,这样的AI生成图像将是无定形的。
text = "一张举起手的老人照片,真实的姿势。"
output = deployed_model.predict(GenerationRequest(
text_prompts=[TextPrompt(text=text)],
style_preset="摄影",
seed=11111,
height=640,
width=1536,
steps=100,
cfg_scale=7,
))
使用SDXL 1.0生成文本
SDXL适用于包含图像内文本生成的复杂图像设计工作流程。这个示例提示展示了这个功能。观察使用SDXL生成的文本生成的清晰度,并注意电影的样式预设。
text = "写下以下单词:梦想"
output = deployed_model.predict(GenerationRequest(text_prompts=[TextPrompt(text=text)],
style_preset="电影",
seed=15,
height=640,
width=1536,
sampler="DDIM",
steps=32,
))
从SageMaker JumpStart发现SDXL 1.0
SageMaker JumpStart为您提供基础模型的访问、定制和集成,以便您将其纳入机器学习生命周期。一些模型是开放权重模型,允许您访问和修改模型权重和脚本,而一些是闭合权重模型,不允许您访问它们以保护模型提供者的知识产权。闭合权重模型要求您从AWS Marketplace模型详细页面订阅模型,目前SDXL 1.0是一个闭合权重模型。在本节中,我们将介绍如何从SageMaker Studio发现、订阅和部署闭合权重模型。
您可以在SageMaker Studio的主页上选择预构建和自动化解决方案下的JumpStart来访问SageMaker JumpStart。
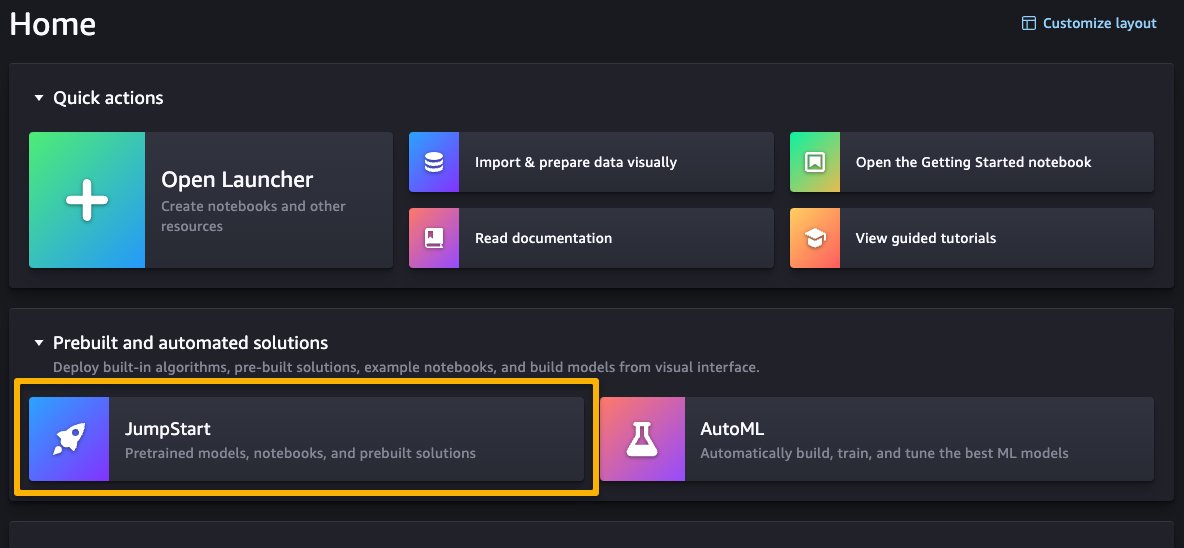
从SageMaker JumpStart登陆页面,您可以浏览解决方案、模型、笔记本和其他资源。以下截图显示了一个带有解决方案和基础模型列表的登陆页面示例。
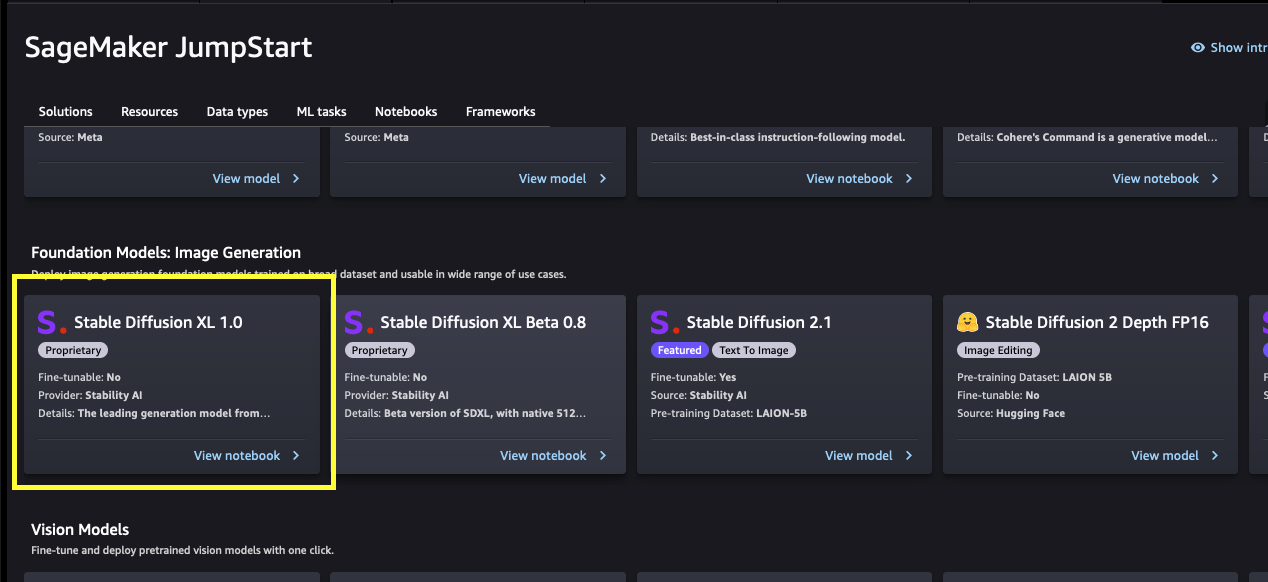
每个模型都有一个模型卡片,如下截图所示,其中包含模型名称、是否可微调、提供者名称和有关模型的简短描述。您可以在“基础模型:图像生成”旋转木马中找到Stable Diffusion XL 1.0模型,或在搜索框中搜索。
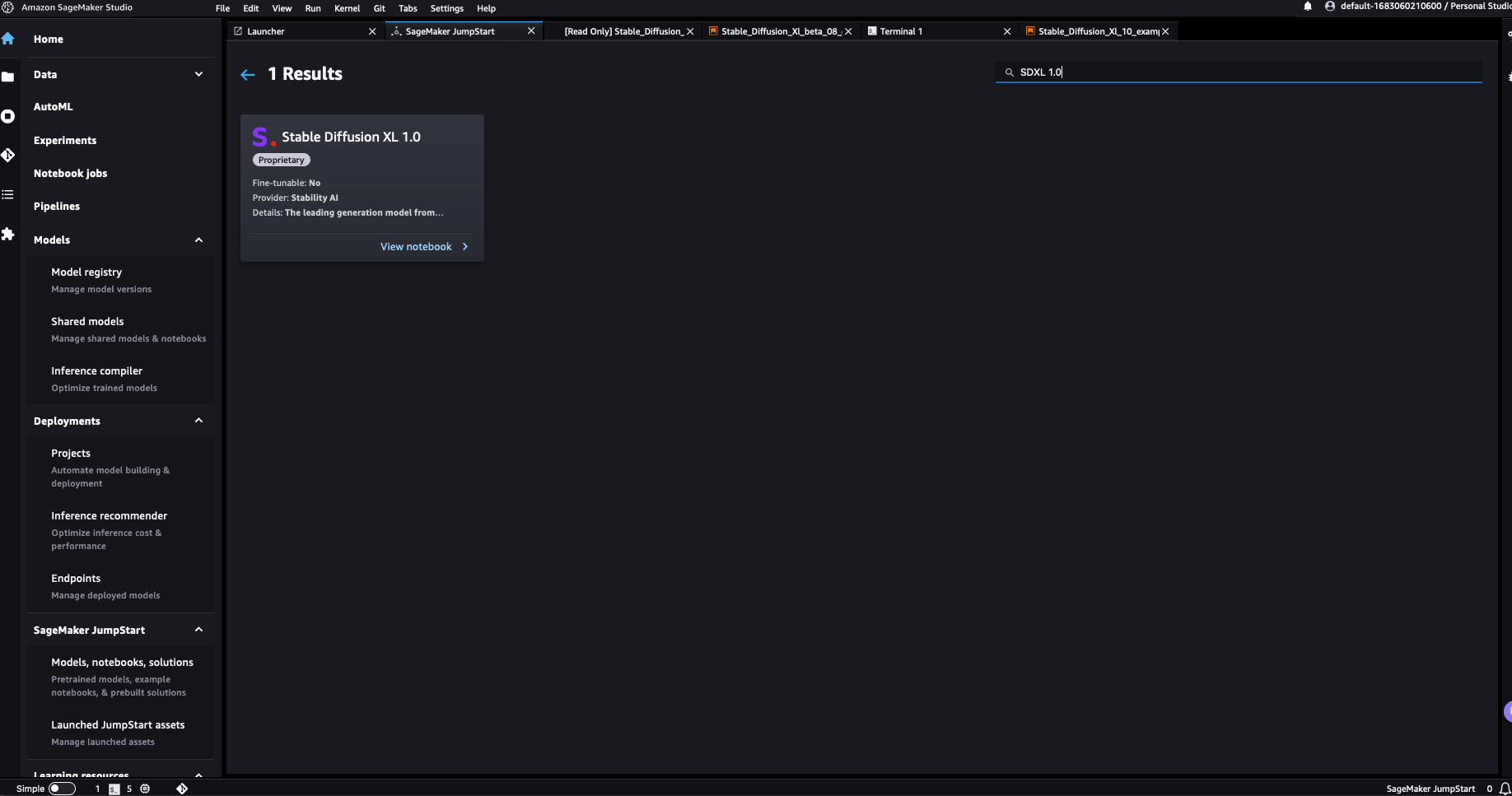
您可以选择“Stable Diffusion XL 1.0”打开一个示例笔记本,该笔记本将指导您如何使用SDXL 1.0模型。示例笔记本以只读模式打开;您需要选择“导入笔记本”来运行它。

导入笔记本后,在运行代码之前,您需要选择适当的笔记本环境(映像、内核、实例类型等)。
从SageMaker JumpStart部署SDXL 1.0
在本节中,我们将介绍如何订阅和部署该模型。
- 使用SageMaker JumpStart示例笔记本中提供的链接,打开AWS Marketplace中的模型列表页面。
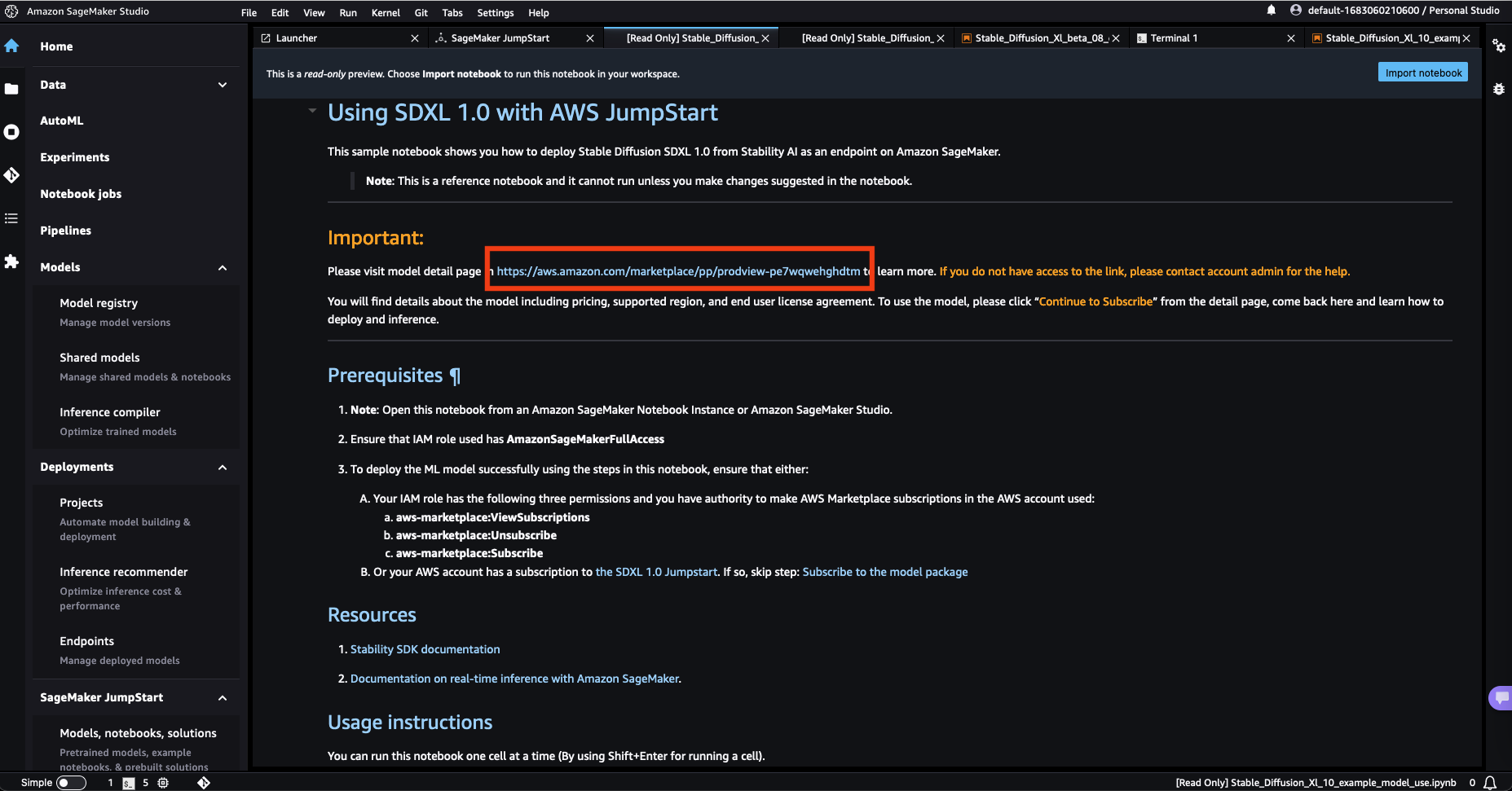
- 在AWS Marketplace列表中,选择“继续订阅”。
如果您没有查看或订阅模型所需的权限,请联系您的AWS管理员或采购联系人。许多企业可能会限制AWS Marketplace权限,以控制某人在AWS Marketplace管理门户中可以执行的操作。
- 选择“继续订阅”。
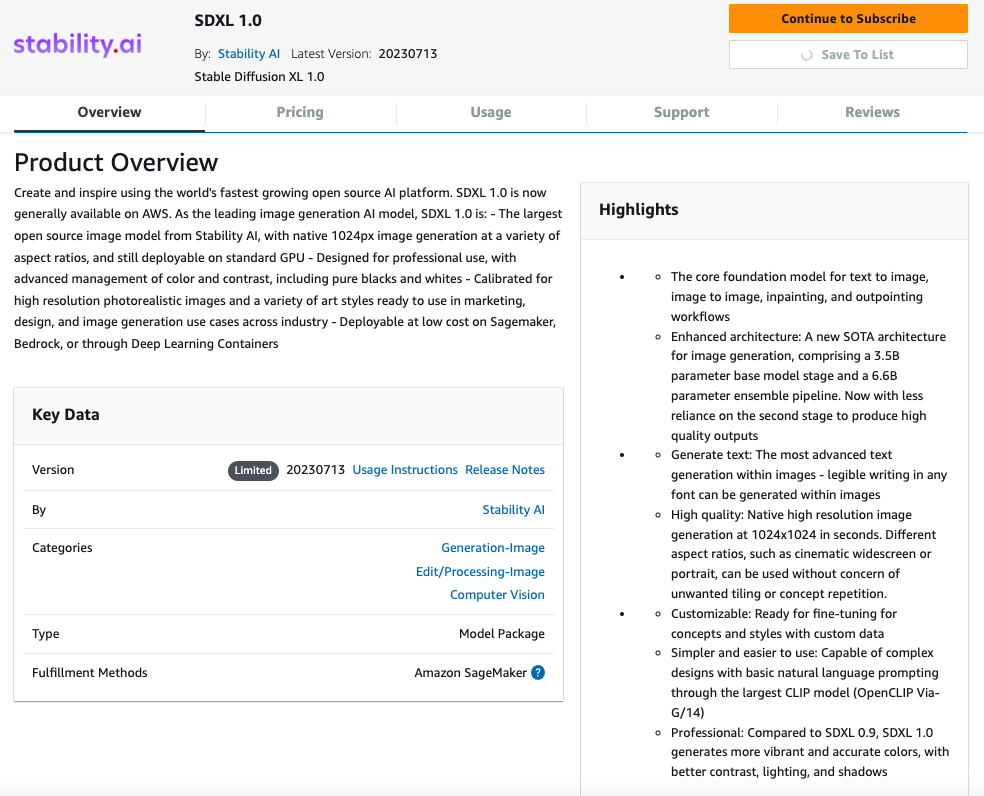
- 在“订阅此软件”页面上,查看定价详细信息和最终用户许可协议(EULA)。如果同意,请选择“接受报价”。
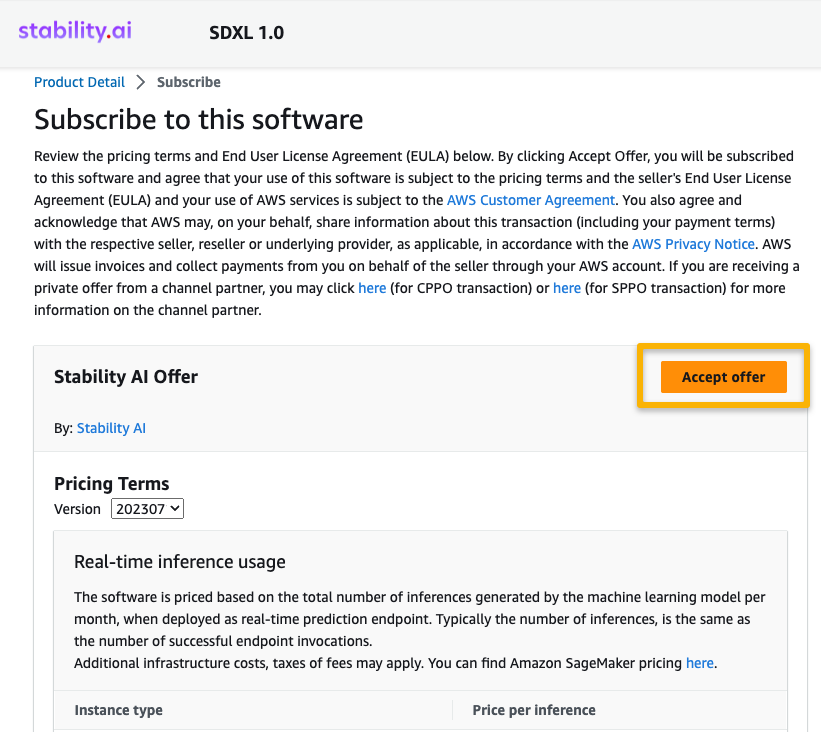
- 选择“继续配置”以开始配置您的模型。
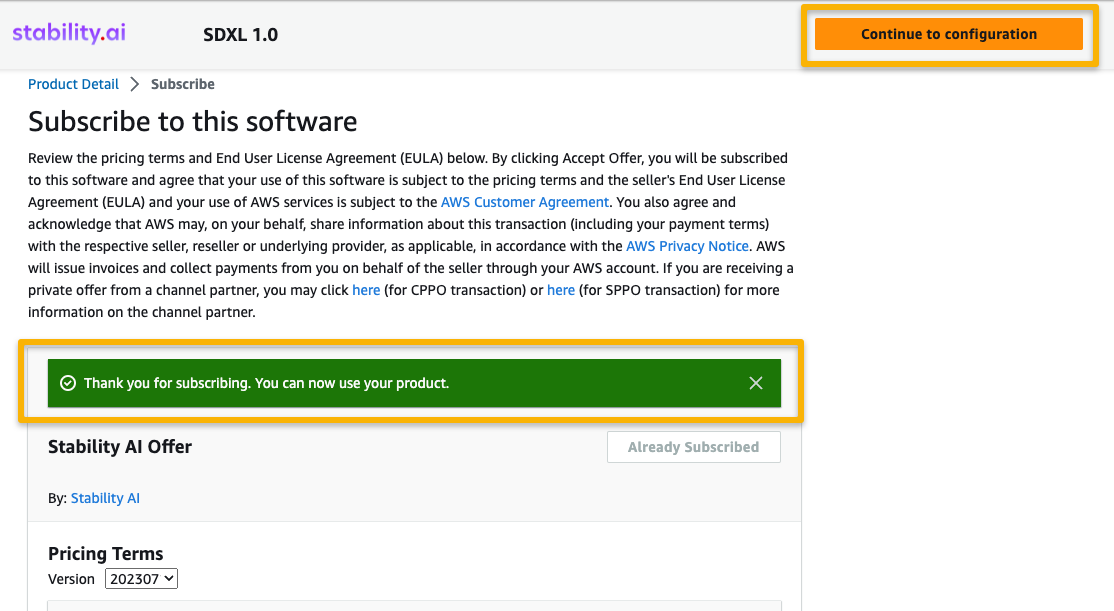
- 选择一个支持的地区。
您将看到显示的产品ARN。这是您在使用Boto3创建可部署模型时需要指定的模型包ARN。
- 复制与您地区对应的ARN,并在笔记本的单元指令中指定相同的ARN。
ARN信息可能已经在示例笔记本中提供。
- 现在,您已经准备好开始跟随示例笔记本。
您也可以继续从AWS Marketplace开始,但我们建议在SageMaker Studio中跟随示例笔记本,以更好地了解部署的工作原理。
清理
当您完成工作后,可以删除端点以释放与其关联的Amazon Elastic Compute Cloud(Amazon EC2)实例并停止计费。
使用AWS CLI获取SageMaker端点列表,如下所示:
!aws sagemaker list-endpoints然后删除端点:
deployed_model.sagemaker_session.delete_endpoint(endpoint_name)结论
在本文中,我们向您展示了如何在SageMaker Studio中使用新的SDXL 1.0模型入门。通过该模型,您可以利用SDXL提供的不同功能来创建逼真的图像。由于基础模型是预训练的,它们还可以帮助降低训练和基础设施成本,并为您的用例提供定制化能力。
资源
- SageMaker JumpStart
- JumpStart基础模型
- SageMaker JumpStart产品页面
- SageMaker JumpStart模型目录





