使用预训练扩散模型进行图像合成
使用预训练扩散模型合成图像
一种增加对预训练的文本到图像扩散模型生成的图像的控制的技术

文本到图像扩散模型在生成与自然语言描述提示相符的逼真图像方面取得了惊人的性能。开源预训练模型的发布,如稳定扩散,为这些技术的普及做出了贡献。预训练扩散模型使任何人都能够在不需要大量计算资源或长时间训练过程的情况下创建令人惊叹的图像。
尽管文本引导的图像生成提供了一定程度的控制,但即使进行了广泛的提示,获取具有预定构图的图像通常也很棘手。事实上,标准的文本到图像扩散模型在生成的图像中往往对各种元素的控制力很小。
在本文中,我将解释一种基于论文《多扩散:融合扩散路径以实现可控图像生成》的最新技术。这种技术使得可以通过文本引导的扩散模型在生成的图像中放置元素时获得更大的控制。论文中提出的方法更加通用,可以用于其他应用,如生成全景图像,但在这里我将限制在使用基于区域的文本提示进行图像组合的情况下。这种方法的主要优点是可以与开箱即用的预训练扩散模型一起使用,无需昂贵的重新训练或微调。
为了补充这篇文章的代码,我准备了一个简单的Colab笔记本和一个带有我用于生成本文中图像的代码实现的GitHub存储库。该代码基于Hugging Face的diffusers库中的稳定扩散流程,但为了使其更简单易读,只实现了其运行所必需的部分。
扩散模型
在本节中,我将回顾一些关于扩散模型的基本事实。扩散模型是通过反演将数据分布映射到各向同性的高斯分布的扩散过程生成新数据的生成模型。更具体地说,给定一张图像,扩散过程由一系列步骤组成,每个步骤向该图像添加一小部分高斯噪声。在无限步骤的极限情况下,被噪声干扰的图像将无法与从各向同性高斯分布中采样的纯噪声区分开来。
扩散模型的目标是通过尝试猜测扩散过程中第t-1步的被噪声干扰的图像,给定第t步的被噪声干扰的图像,来反演这个过程。例如,可以通过训练一个神经网络来预测在该步骤中添加的噪声,并从被噪声干扰的图像中减去它。
一旦我们训练了这样一个模型,我们就可以通过从各向同性高斯分布中采样噪声,并使用模型逐渐去除噪声来生成新的图像。

文本到图像扩散模型通过试图反演扩散过程来达到与文本提示描述的图像相对应的图像。通常,这是通过一个神经网络来实现的,在每个步骤t中,该网络预测在t-1步的被噪声干扰的图像,不仅以t步的被噪声干扰的图像为条件,还以描述试图重建的图像的文本提示为条件。
包括稳定扩散在内的许多图像扩散模型不是在原始图像空间中操作,而是在一个较小的学习到的潜空间中操作。通过这种方式,可以在减少所需计算资源的同时最小化质量损失。潜空间通常是通过变分自编码器学习的。潜空间中的扩散过程与之前完全相同,允许从高斯噪声生成新的潜向量。从这些潜向量中,可以使用变分自编码器的解码器获得新生成的图像。
使用MultiDiffusion进行图像合成
现在让我们来解释一下如何使用MultiDiffusion方法获得可控图像合成。目标是通过预训练的文本到图像扩散模型来更好地控制生成图像中的元素。具体来说,给定图像的一般描述(例如封面图像中的起居室),我们希望一系列通过文本提示指定的元素出现在特定位置(例如中间的红色沙发,左侧的盆栽和右上方的画作)。这可以通过提供描述所需元素的一组文本提示以及指定元素必须呈现的位置的一组基于区域的二进制掩码来实现。例如,下面的图像包含封面图像中图像元素的边界框。

多扩散用于可控图像生成的核心思想是将多个与不同指定提示相关的扩散过程组合在一起,以获得一个连贯且平滑的图像,显示每个提示的内容在预定的区域内。与每个提示相关联的区域通过与图像相同尺寸的二进制掩码指定。如果提示必须在该位置呈现,则掩码的像素设置为1,否则设置为0。
具体来说,让我们用t表示在潜在空间中进行扩散过程的通用步骤。给定时刻t的噪声潜在向量,模型将预测每个指定文本提示的噪声。从这些预测的噪声中,通过将每个预测的噪声从时刻t的先前潜在向量中删除,我们获得时刻t-1的一组潜在向量(每个提示一个)。为了获得扩散过程中下一个时间步的输入,我们需要将这些不同的向量组合在一起。可以通过将每个潜在向量乘以相应的提示掩码,然后采用掩码加权的逐像素平均来完成。遵循此过程,在特定掩码指定的区域中,潜在向量将遵循由相应局部提示引导的扩散过程的轨迹。在每个步骤之前将潜在向量组合在一起,然后预测噪声,可确保生成图像的整体连贯性以及不同掩码区域之间的平滑过渡。
MultiDiffusion在扩散过程的开始阶段引入了引导阶段,以更好地遵循紧密的掩码。在这些初始步骤中,与不同提示相对应的去噪潜在向量不是组合在一起,而是与与恒定颜色背景对应的一些带噪声潜在向量组合在一起。通过这种方式,由于布局通常在扩散过程的早期确定,可以更好地与指定的掩码匹配,因为模型最初只能专注于遮罩区域以呈现提示。
示例
在本节中,我将展示该方法的一些应用。我使用HuggingFace托管的预训练稳定扩散2模型创建了本文中的所有图像,包括封面图像。
正如讨论的那样,该方法的一个直接应用是获得一个包含在预定义位置生成的元素的图像。


该方法允许指定要呈现的单个元素的样式或其他属性。例如,可以用模糊的背景获得清晰的图像。


元素的样式也可以非常不同,从而产生令人惊叹的视觉效果。例如,下面的图像是通过混合高质量的照片风格和梵高风格的绘画得到的。
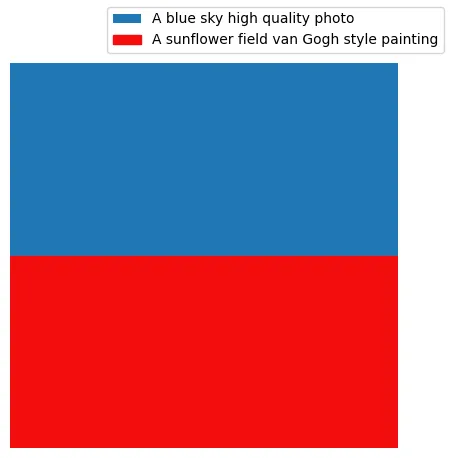

结论
在本文中,我们探讨了一种将不同的扩散过程结合起来,以改善文本条件扩散模型生成图像的控制方法。该方法增加了对图像元素生成位置的控制,并且可以无缝地组合不同风格中所描述的元素。
所描述的方法的主要优点之一是,它可以与预训练的文本到图像扩散模型一起使用,而无需进行微调,这通常是一种昂贵的过程。另一个优点是,可控的图像生成通过更简单的二进制掩码来实现,这些掩码比更复杂的条件更容易指定和处理。
这种技术的主要缺点是,为了预测相应的噪声,在每个扩散步骤中需要对每个提示进行一次神经网络传递。幸运的是,这些可以批量执行以减少推理时间开销,但代价是更大的GPU内存利用率。此外,有时会忽略其中一些提示(尤其是仅在图像的一小部分中指定的提示),或者它们覆盖的区域比相应掩码指定的区域要大。虽然这可以通过引导步骤来减轻,但过多的引导步骤会显著降低图像的整体质量,因为可用于将元素协调在一起的步骤较少。
值得一提的是,将不同的扩散过程结合起来的想法不仅限于本文中所描述的内容,还可以用于进一步的应用,例如在论文《MultiDiffusion: Fusing Diffusion Paths for Controlled Image Generation》中描述的全景图像生成。
希望您喜欢这篇文章,如果您想深入了解技术细节,可以查看这个Colab笔记本和包含代码实现的GitHub存储库。