使用FastAPI和PyTorch模型在Amazon EC2 Inf1和Inf2实例上优化AWS Inferentia的利用
优化AWS Inferentia的利用,使用FastAPI和PyTorch模型在Amazon EC2 Inf1和Inf2实例上
在大规模部署深度学习模型时,充分利用底层硬件以实现性能和成本效益的最大化至关重要。对于需要高吞吐量和低延迟的生产工作负载,选择Amazon Elastic Compute Cloud(EC2)实例、模型服务堆栈和部署架构非常重要。不高效的架构可能导致加速器利用不佳和不必要的高生产成本。
在本文中,我们将向您介绍在AWS Inferentia设备上部署FastAPI模型服务器的过程(该设备可在Amazon EC2 Inf1和Amazon EC2 Inf2实例上找到)。我们还演示了如何将一个示例模型并行部署在所有NeuronCores上,以实现最大的硬件利用率。
解决方案概述
FastAPI是一个用于提供Python应用程序的开源Web框架,比传统框架如Flask和Django要快得多。它使用异步服务器网关接口(ASGI)而不是广泛使用的Web服务器网关接口(WSGI)。ASGI以异步方式处理传入请求,而不是像WSGI那样按顺序处理请求。这使得FastAPI成为处理延迟敏感请求的理想选择。您可以使用FastAPI部署一个服务器,该服务器在Inferentia(Inf1/Inf2)实例上托管一个端点,并通过指定的端口监听客户端请求。
我们的目标是通过最大化硬件利用率在最低成本下实现最高性能。这使我们能够使用更少的加速器处理更多的推理请求。每个AWS Inferentia1设备包含四个NeuronCores-v1,每个AWS Inferentia2设备包含两个NeuronCores-v2。AWS Neuron SDK允许我们并行地利用每个NeuronCore,这使我们能够更好地控制加载和推理四个或更多模型,而不会降低吞吐量。
使用FastAPI,您可以选择Python Web服务器(Gunicorn、Uvicorn、Hypercorn、Daphne)。这些Web服务器在底层的机器学习(ML)模型之上提供了一个抽象层。请求的客户端无需了解托管模型的名称或版本。客户端不需要知道服务器上已部署的模型的名称或版本;端点名称现在只是一个加载和运行模型的函数的代理。相比之下,在特定于框架的服务工具(如TensorFlow Serving)中,模型的名称和版本是端点名称的一部分。如果服务器端的模型发生更改,客户端必须知道并相应地更改其API调用到新的端点。因此,如果您不断演进版本模型,比如在A/B测试的情况下,使用一个通用的Python Web服务器与FastAPI一起提供模型是一种方便的方式,因为端点名称是静态的。
ASGI服务器的作用是生成指定数量的工作进程,监听客户端请求并运行推理代码。服务器的一个重要能力是确保请求的工作进程数量可用且活动。如果一个工作进程被终止,服务器必须启动一个新的工作进程。在这种情况下,服务器和工作进程可以通过它们的Unix进程ID(PID)来识别。在本文中,我们使用Hypercorn服务器,这是Python Web服务器的常见选择。
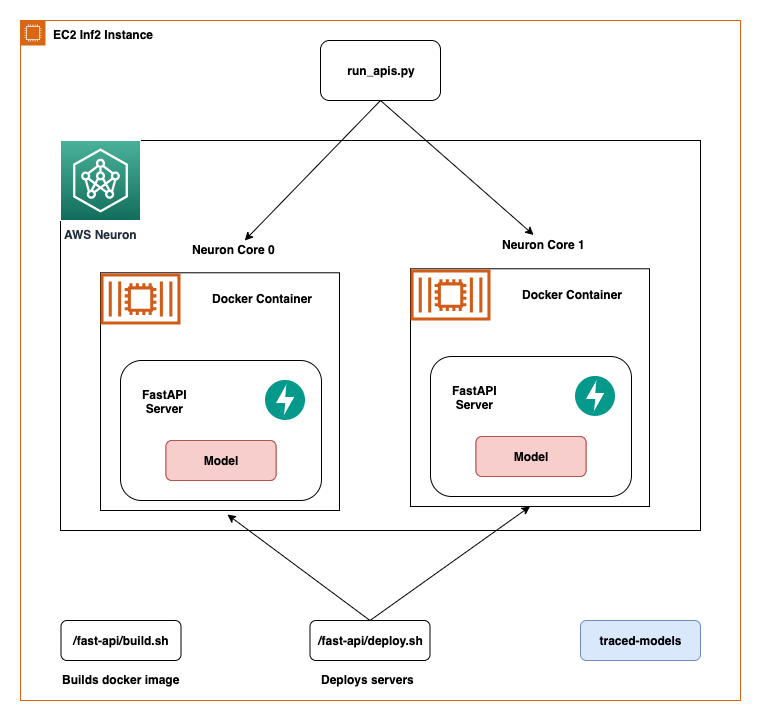
在本文中,我们分享了在AWS Inferentia NeuronCores上使用FastAPI部署深度学习模型的最佳实践。我们展示了您可以在单独的NeuronCores上部署多个模型,并且可以同时调用这些模型。这种设置可以增加吞吐量,因为多个模型可以同时进行推理,并且NeuronCore的利用率得到了充分优化。代码可以在GitHub存储库中找到。下图显示了如何在EC2 Inf2实例上设置解决方案的架构。
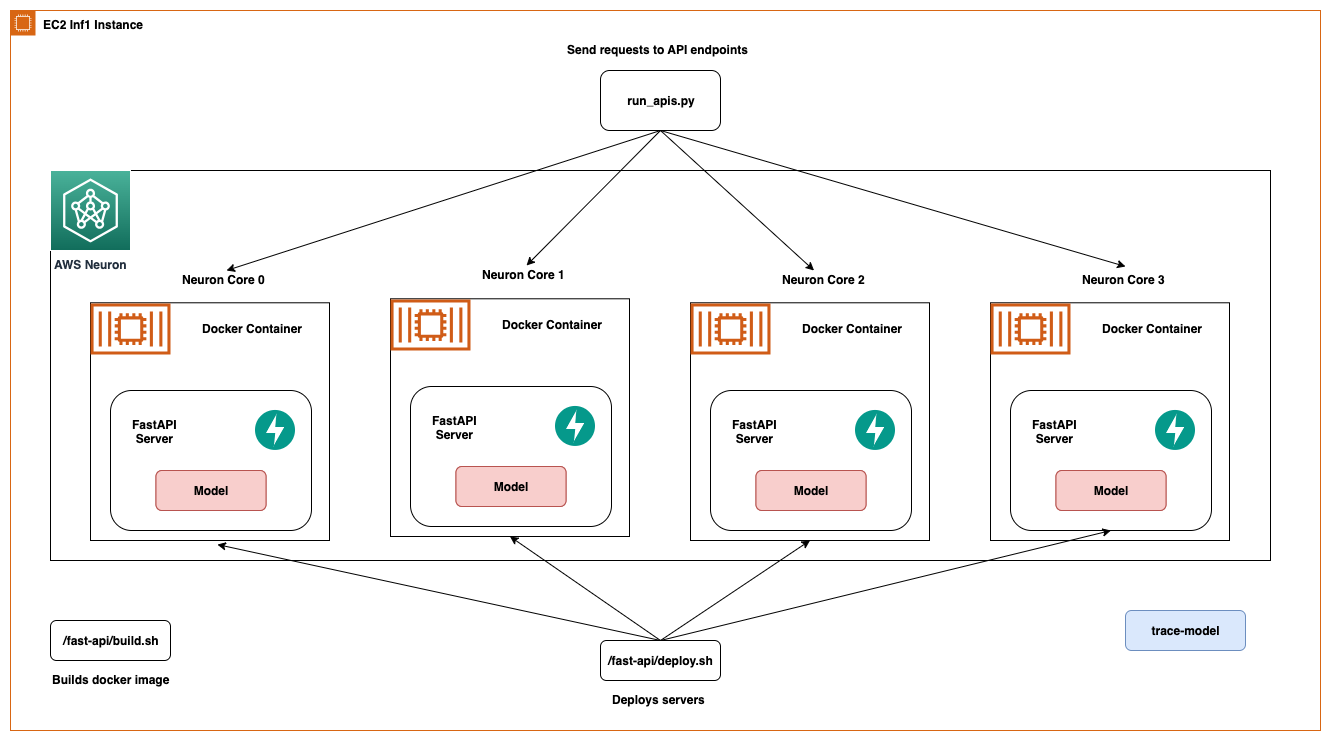
相同的架构也适用于EC2 Inf1实例类型,只是它具有四个内核。因此,架构图有所变化。
AWS Inferentia NeuronCores
让我们深入了解由AWS Neuron提供的与NeuronCores交互的工具。下表显示了每个Inf1和Inf2实例类型中的NeuronCores数量。主机vCPUs和系统内存在所有可用的NeuronCores之间共享。
| 实例大小 | # Inferentia 加速器 | # NeuronCores-v1 | vCPUs | 内存(GiB) |
| Inf1.xlarge | 1 | 4 | 4 | 8 |
| Inf1.2xlarge | 1 | 4 | 8 | 16 |
| Inf1.6xlarge | 4 | 16 | 24 | 48 |
| Inf1.24xlarge | 16 | 64 | 96 | 192 |
| 实例大小 | # Inferentia 加速器 | # NeuronCores-v2 | vCPUs | 内存(GiB) |
| Inf2.xlarge | 1 | 2 | 4 | 32 |
| Inf2.8xlarge | 1 | 2 | 32 | 32 |
| Inf2.24xlarge | 6 | 12 | 96 | 192 |
| Inf2.48xlarge | 12 | 24 | 192 | 384 |
与 Inf1 实例相比,Inf2 实例采用了新的 NeuronCores-v2。尽管核心数量较少,但它们能够提供比 Inf1 实例高 4 倍的吞吐量和比 Inf1 实例低 10 倍的延迟。Inf2 实例非常适合生成式人工智能、OPT/GPT 家族中的大型语言模型(LLM)以及稳定扩散等视觉转换的深度学习工作负载。
Neuron 运行时负责在 Neuron 设备上运行模型。Neuron 运行时确定哪个 NeuronCore 运行哪个模型以及如何运行它。通过使用进程级别的环境变量来控制 Neuron 运行时的配置。默认情况下,Neuron 框架扩展会自动处理用户的 Neuron 运行时配置;然而,也可以显式配置以实现更优化的行为。
两个常用的环境变量是 NEURON_RT_NUM_CORES 和 NEURON_RT_VISIBLE_CORES。使用这些环境变量,可以将 Python 进程绑定到 NeuronCore。通过 NEURON_RT_NUM_CORES,可以为进程保留指定数量的核心,而通过 NEURON_RT_VISIBLE_CORES,可以保留一系列 NeuronCores。例如,NEURON_RT_NUM_CORES=2 myapp.py 将为 myapp.py 保留两个核心,而 NEURON_RT_VISIBLE_CORES=’0-2’ myapp.py 将为 myapp.py 保留零、一和二号核心。还可以在设备(AWS Inferentia chips)之间保留 NeuronCores。因此,在 Ec2 Inf1 实例类型上,NEURON_RT_VISIBLE_CORES=’0-5’ myapp.py 将在 device1 上保留前四个核心,在 device2 上保留一个核心。类似地,在 EC2 Inf2 实例类型上,这个配置将在 device1 和 device2 上保留两个核心,在 device3 上保留一个核心。下表总结了这些变量的配置。
| 名称 | 描述 | 类型 | 预期值 | 默认值 | RT 版本 |
NEURON_RT_VISIBLE_CORES |
进程所需的特定 NeuronCores 范围 | 整数范围 (如 1-3) | 任何值或范围从 0 到系统中的最大 NeuronCore | 无 | 2.0+ |
NEURON_RT_NUM_CORES |
进程所需的 NeuronCores 数量 | 整数 | 从 1 到系统中的最大 NeuronCore 的值 | 0,即解释为“全部” | 2.0+ |
有关所有环境变量的列表,请参阅 Neuron 运行时配置。
默认情况下,加载模型时,模型会加载到 NeuronCore 0,然后加载到 NeuronCore 1,除非前面的环境变量明确指定。如前所述,NeuronCores 共享可用的主机 vCPUs 和系统内存。因此,部署在每个 NeuronCore 上的模型将竞争可用资源。如果模型在 NeuronCores 上只运行部分,并且其余部分在主机 vCPUs 上运行,则考虑每个 NeuronCore 的 CPU 可用性变得重要。这也会影响实例的选择。
以下表格显示了如果每个 NeuronCore 部署一个模型时,每个模型可用的主机 vCPUs 和系统内存数量。根据您的应用程序的 NeuronCore 使用情况、vCPU 和内存使用情况,建议进行测试,找出哪种配置对您的应用程序性能最好。Neuron Top 工具可以帮助可视化核心利用率以及设备和主机内存利用率。根据这些指标,可以做出明智的决策。我们在本博客的最后演示了如何使用 Neuron Top。
| 实例大小 | # Inferentia 加速器 | # 模型 | vCPUs/模型 | 内存/模型 (GiB) |
| Inf1.xlarge | 1 | 4 | 1 | 2 |
| Inf1.2xlarge | 1 | 4 | 2 | 4 |
| Inf1.6xlarge | 4 | 16 | 1.5 | 3 |
| Inf1.24xlarge | 16 | 64 | 1.5 | 3 |
| 实例规模 | # Inferentia 加速器 | # 模型 | vCPUs/模型 | 内存/模型 (GiB) |
| Inf2.xlarge | 1 | 2 | 2 | 8 |
| Inf2.8xlarge | 1 | 2 | 16 | 64 |
| Inf2.24xlarge | 6 | 12 | 8 | 32 |
| Inf2.48xlarge | 12 | 24 | 8 | 32 |
要自行测试 Neuron SDK 的功能,请查看 PyTorch 的最新 Neuron 功能。
系统设置
以下是此解决方案使用的系统设置:
- 实例规模 – 6xlarge(如果使用 Inf1),Inf2.xlarge(如果使用 Inf2)
- 实例的镜像 – 深度学习 AMI Neuron PyTorch 1.11.0(Ubuntu 20.04)20230125
- 模型 – https://huggingface.co/twmkn9/bert-base-uncased-squad2
- 框架 – PyTorch
设置解决方案
我们需要进行一些设置才能配置解决方案。首先,创建一个 IAM 角色,您的 EC2 实例将扮演该角色,使其能够从 Amazon Elastic Container Registry 推送和拉取。
步骤 1:设置 IAM 角色
- 首先登录控制台,访问 IAM > 角色 > 创建角色
- 选择受信实体类型为
AWS 服务 - 选择用例下的服务为 EC2
- 点击 下一步,您将能够看到所有可用的策略
- 针对此解决方案,我们将为我们的 EC2 实例提供对 ECR 的完全访问权限。筛选 AmazonEC2ContainerRegistryFullAccess 并选择它。
- 按下一步并将角色命名为
inf-ecr-access
注意:我们附加的策略给予 EC2 实例对 Amazon ECR 的完全访问权限。我们强烈建议在生产工作负载中遵循最小权限原则。
步骤 2:设置 AWS CLI
如果您使用上面列出的建议的深度学习 AMI,它已经安装了 AWS CLI。如果您使用其他 AMI(Amazon Linux 2023,基础 Ubuntu 等),请按照此指南安装 CLI 工具。
安装了 CLI 工具之后,使用命令 aws configure 配置 CLI。如果您有访问密钥,可以在此处添加,但不一定需要它们与 AWS 服务进行交互。我们依赖 IAM 角色来完成这个。
注意:我们需要输入至少一个值(默认区域或默认格式)来创建默认配置文件。对于此示例,我们选择将区域设置为 us-east-2,将默认输出设置为 json。
克隆Github存储库
Github存储库提供了使用FastAPI在AWS Inferentia实例上部署模型所需的所有脚本。此示例使用Docker容器以确保我们可以创建可重复使用的解决方案。此示例包含以下config.properties文件,供用户提供输入。
# Docker镜像和容器名称
docker_image_name_prefix=<Docker镜像名称>
docker_container_name_prefix=<Docker容器名称>
# 部署设置
path_to_traced_models=<跟踪模型的路径>
compiled_model=<编译后的模型文件名>
num_cores=<部署模型服务器的NeuronCores数量>
num_models_per_server=<每个服务器加载的模型数量>配置文件需要用户定义的Docker镜像和Docker容器的名称前缀。在fastapi和trace-model文件夹中的build.sh脚本使用此前缀创建Docker镜像。
在AWS Inferentia上编译模型
我们将从跟踪模型并生成PyTorch Torchscript .pt文件开始。首先访问trace-model目录并修改.env文件。根据您选择的实例类型,修改.env文件中的CHIP_TYPE。作为示例,我们将选择Inf2作为指南。相同的步骤适用于Inf1的部署过程。
接下来,在同一文件中设置默认区域。此区域将用于创建ECR存储库,并将Docker镜像推送到该存储库。在此文件夹中,我们提供了在AWS Inferentia上跟踪bert-base-uncased模型所需的所有脚本。此脚本适用于Hugging Face上可用的大多数模型。Dockerfile具有运行具有Neuron的模型所需的所有依赖项,并将trace-model.py代码作为入口点运行。
解释Neuron编译
Neuron SDK的API与PyTorch Python API非常相似。PyTorch的torch.jit.trace()接受模型和示例输入张量作为参数。示例输入被馈送到模型,并记录作为输入通过模型层的方式调用的操作,记录为TorchScript。要了解有关PyTorch中JIT跟踪的更多信息,请参阅以下文档。
与torch.jit.trace()类似,您可以使用以下代码检查您的模型是否可以在AWS Inferentia上编译为inf1实例。
import torch_neuron
model_traced = torch.neuron.trace(model,
example_inputs,
compiler_args =
[‘--fast-math’, ‘fp32-cast-matmul’,
‘--neuron-core-pipeline-cores’,’1’],
optimizations=[torch_neuron.Optimization.FLOAT32_TO_FLOAT16])对于inf2,库名为torch_neuronx。以下是如何针对inf2实例测试模型编译的方法。
import torch
import torch_neuronx
model_traced = torch.neuronx.trace(model,
example_inputs,
compiler_args =
[‘--fast-math’, ‘fp32-cast-matmul’,
‘--neuron-core-pipeline-cores’,’1’],
optimizations=[torch_neuronx.Optimization.FLOAT32_TO_FLOAT16])创建跟踪实例后,我们可以像这样传递示例张量输入:
answer_logits = model_traced(*example_inputs)最后将生成的TorchScript输出保存在本地磁盘上
model_traced.save('./compiled-model-bs-{batch_size}.pt')如上所示,您可以使用compiler_args和optimizations来优化部署。有关torch.neuron.trace API的参数详细列表,请参阅PyTorch-Neuron跟踪Python API。
请记住以下重要要点:
- 截至目前,Neuron SDK不支持动态张量形状。因此,必须为不同的输入形状单独编译模型。有关使用桶进行可变输入形状推理的更多信息,请参阅使用桶进行可变输入形状推理。
- 如果在编译模型时遇到内存不足问题,请尝试在具有更多vCPU或内存的AWS Inferentia实例上编译模型,或者甚至使用大型c6i或r6i实例,因为编译只使用CPU。一旦编译完成,跟踪模型可能可以在较小的AWS Inferentia实例上运行。
构建过程解释
现在我们将通过运行build.sh来构建这个容器。构建脚本文件简单地通过拉取基础的深度学习容器镜像并安装HuggingFace的transformers包来创建Docker镜像。根据.env文件中指定的CHIP_TYPE,docker.properties文件决定了适当的BASE_IMAGE。这个BASE_IMAGE指向由AWS提供的Neuron Runtime的深度学习容器镜像。
它通过一个私有的ECR仓库提供。在我们可以拉取镜像之前,我们需要登录并获取临时的AWS凭证。
aws ecr get-login-password --region <region> | docker login --username AWS --password-stdin 763104351884.dkr.ecr.<region>.amazonaws.com注意:我们需要用.env文件中的区域替换命令中的区域标志和仓库URI中的区域。
为了使这个过程更简单,我们可以使用fetch-credentials.sh文件。区域将自动从.env文件中获取。
接下来,我们将使用push.sh脚本推送镜像。推送脚本为您创建一个Amazon ECR仓库并推送容器镜像。
最后,当镜像构建和推送完成后,我们可以通过运行run.sh作为容器运行它,并使用logs.sh尾随运行日志。在编译器日志中(见下图),您将看到在Neuron上编译的算术运算符的百分比以及成功在Neuron上编译的模型子图的百分比。该截图显示了bert-base-uncased-squad2模型的编译器日志。日志显示,95.64%的算术运算符被编译,并且还列出了在Neuron上编译的运算符和不支持的运算符。
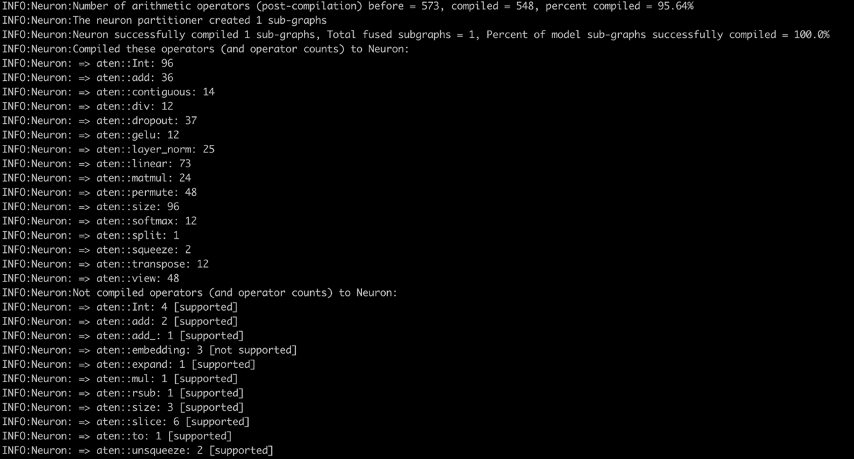
这是最新的PyTorch Neuron包中支持的所有操作符的列表。类似地,这是最新的PyTorch Neuronx包中支持的所有操作符的列表。
使用FastAPI部署模型
模型编译完成后,跟踪模型将出现在trace-model文件夹中。在本示例中,我们将跟踪模型放在了批大小为1的位置。我们在这里考虑了批大小为1的情况,以适应那些不可行或不需要更高批大小的用例。对于需要更高批大小的用例,torch.neuron.DataParallel(对于Inf1)或torch.neuronx.DataParallel(对于Inf2)API也可能有用。
fast-api文件夹提供了使用FastAPI部署模型所需的所有脚本。要部署模型而不进行任何更改,只需运行deploy.sh脚本,它将构建一个FastAPI容器镜像,在指定的核心数上运行容器,并在每个FastAPI模型服务器中部署指定数量的模型。该文件夹还包含一个.env文件,请根据实际情况修改它以反映正确的CHIP_TYPE和AWS_DEFAULT_REGION。
注意:FastAPI脚本依赖于用于构建、推送和运行镜像的相同环境变量。FastAPI部署脚本将使用这些变量的最后已知值。因此,如果您最后为Inf1实例类型跟踪了模型,那么该模型将通过这些脚本进行部署。
fastapi-server.py文件负责托管服务器并将请求发送到模型,它执行以下操作:
- 从属性文件中读取每个服务器上的模型数量和编译模型的位置
- 将可见的NeuronCores设置为Docker容器的环境变量,并读取环境变量以指定要使用的NeuronCores
- 为
bert-base-uncased-squad2模型提供推理API - 使用
jit.load(),根据配置加载每个服务器上指定的模型数量,并将模型和所需的分词器存储在全局字典中
通过这种设置,可以相对容易地设置API,列出存储在每个NeuronCore中的模型及其数量。同样,可以编写API来从特定的NeuronCore中删除模型。
用于构建FastAPI容器的Dockerfile是基于我们为追踪模型构建的Docker镜像构建的。这就是为什么docker.properties文件指定了用于追踪模型的Docker镜像的ECR路径。在我们的设置中,所有NeuronCore上的Docker容器都是相似的,因此我们可以构建一个镜像并从一个镜像运行多个容器。为了避免任何入口错误,我们在Dockerfile中运行startup.sh脚本之前指定了ENTRYPOINT ["/usr/bin/env"],该脚本看起来像hypercorn fastapi-server:app -b 0.0.0.0:8080。这个启动脚本对所有容器都是相同的。如果您使用的是用于追踪模型的相同基础镜像,只需运行build.sh脚本即可构建此容器。与追踪模型之前一样,push.sh脚本保持不变。修改后的Docker镜像和容器名称由docker.properties文件提供。
run.sh文件执行以下操作:
- 从属性文件中读取Docker镜像和容器名称,属性文件再读取
config.properties文件,其中有一个num_cores用户设置 - 从0到
num_cores开始循环,对于每个核心:- 设置端口号和设备号
- 设置
NEURON_RT_VISIBLE_CORES环境变量 - 指定卷挂载
- 运行Docker容器
为了清晰起见,在Inf1的NeuronCore 0中部署的Docker运行命令如下:
docker run -t -d \
--name $ bert-inf-fastapi-nc-0 \
--env NEURON_RT_VISIBLE_CORES="0-0" \
--env CHIP_TYPE="inf1" \
-p ${port_num}:8080 --device=/dev/neuron0 ${registry}/ bert-inf-fastapi在NeuronCore 5中部署的运行命令如下:
docker run -t -d \
--name $ bert-inf-fastapi-nc-5 \
--env NEURON_RT_VISIBLE_CORES="5-5" \
--env CHIP_TYPE="inf1" \
-p ${port_num}:8080 --device=/dev/neuron0 ${registry}/ bert-inf-fastapi容器部署完成后,我们使用run_apis.py脚本,在并行线程中调用API。代码设置为调用部署的六个模型,每个模型在一个NeuronCore上,但可以很容易地更改为不同的设置。我们从客户端调用API如下:
import requests
url_template = http://localhost:%i/predictions_neuron_core_%i/model_%i
# NeuronCore 0
response = requests.get(url_template % (8081,0,0))
# NeuronCore 5
response = requests.get(url_template % (8086,5,0))监视NeuronCore
在部署模型服务器之后,为了监视NeuronCore的利用率,我们可以使用neuron-top实时观察每个NeuronCore的利用率百分比。neuron-top是Neuron SDK中的一个CLI工具,可提供诸如NeuronCore、vCPU和内存利用率等信息。在单独的终端中,输入以下命令:
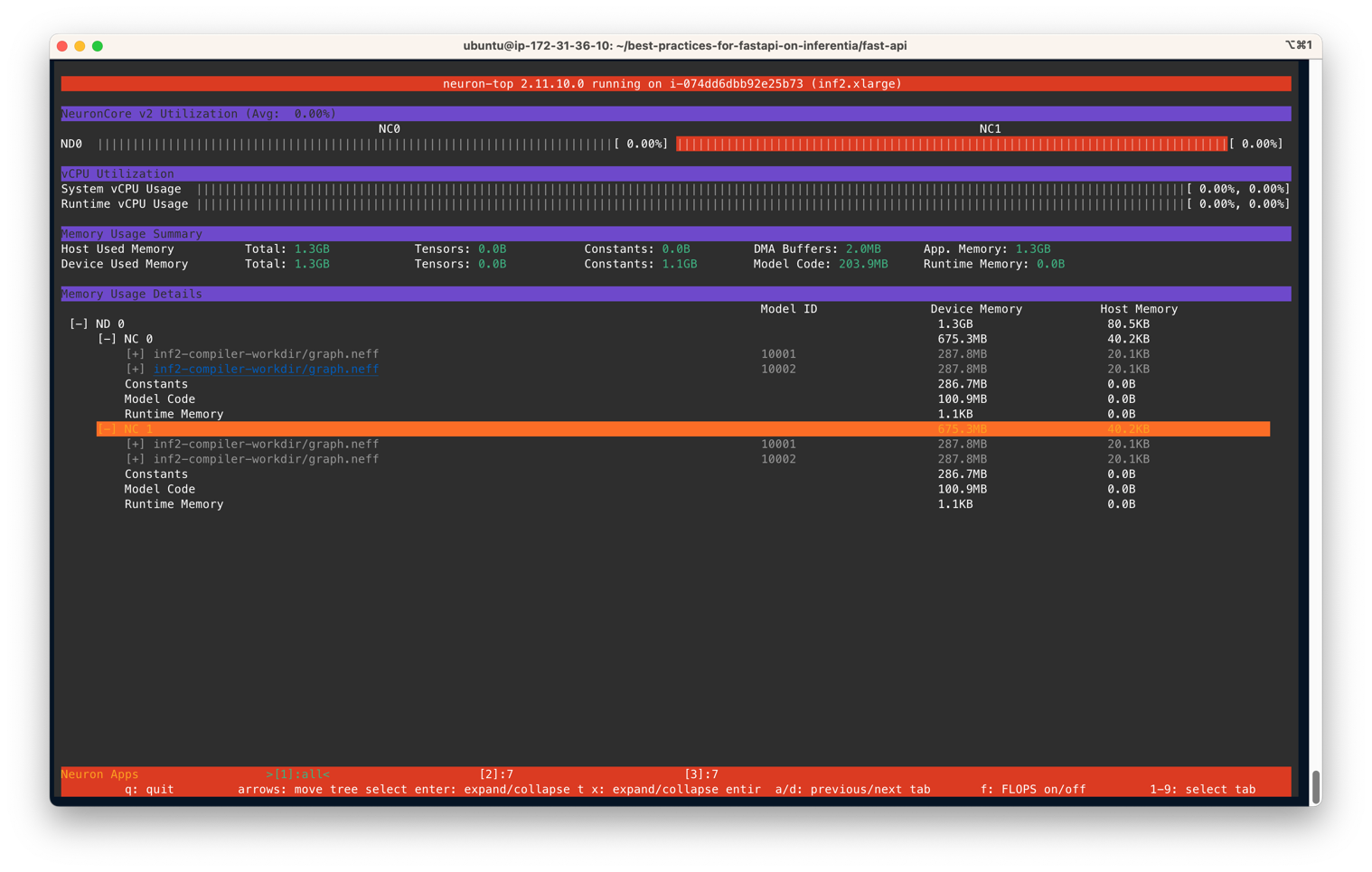
neuron-top您的输出应类似于以下图例。在这种情况下,我们指定在Inf2.xlarge实例上使用两个NeuronCore和两个模型每个服务器。下面的屏幕截图显示了两个大小为287.8MB的模型加载在两个NeuronCore上。加载了4个模型后,您可以看到使用的设备内存为1.3 GB。使用箭头键在不同设备上的NeuronCore之间移动。
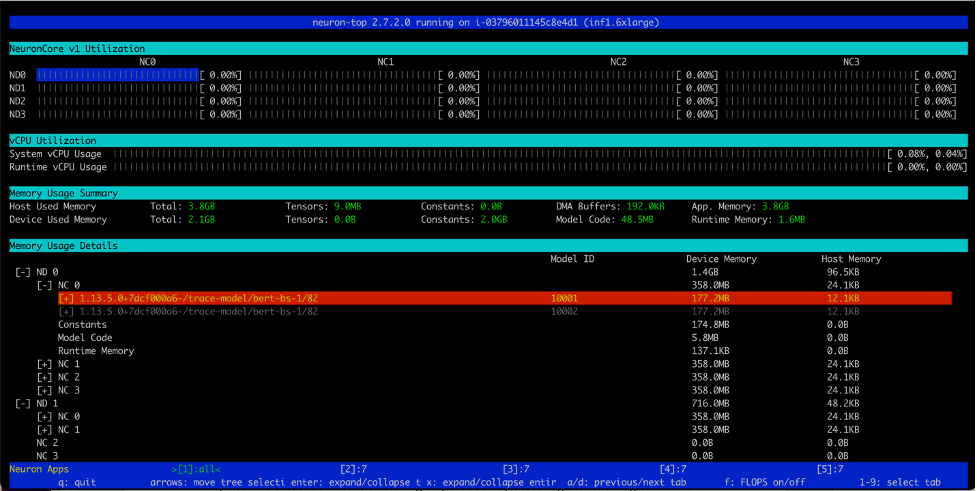
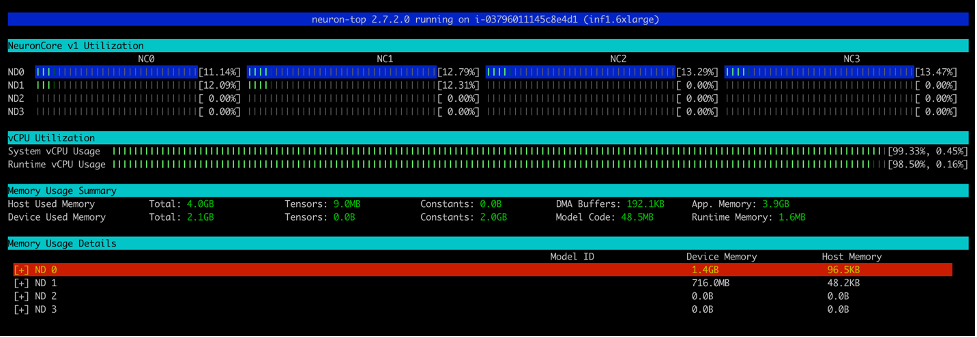
同样,在Inf1.16xlarge实例类型上,我们看到加载了总共12个模型(每个核心2个模型,共6个核心)。总共消耗了2.1GB的内存,每个模型大小为177.2MB。
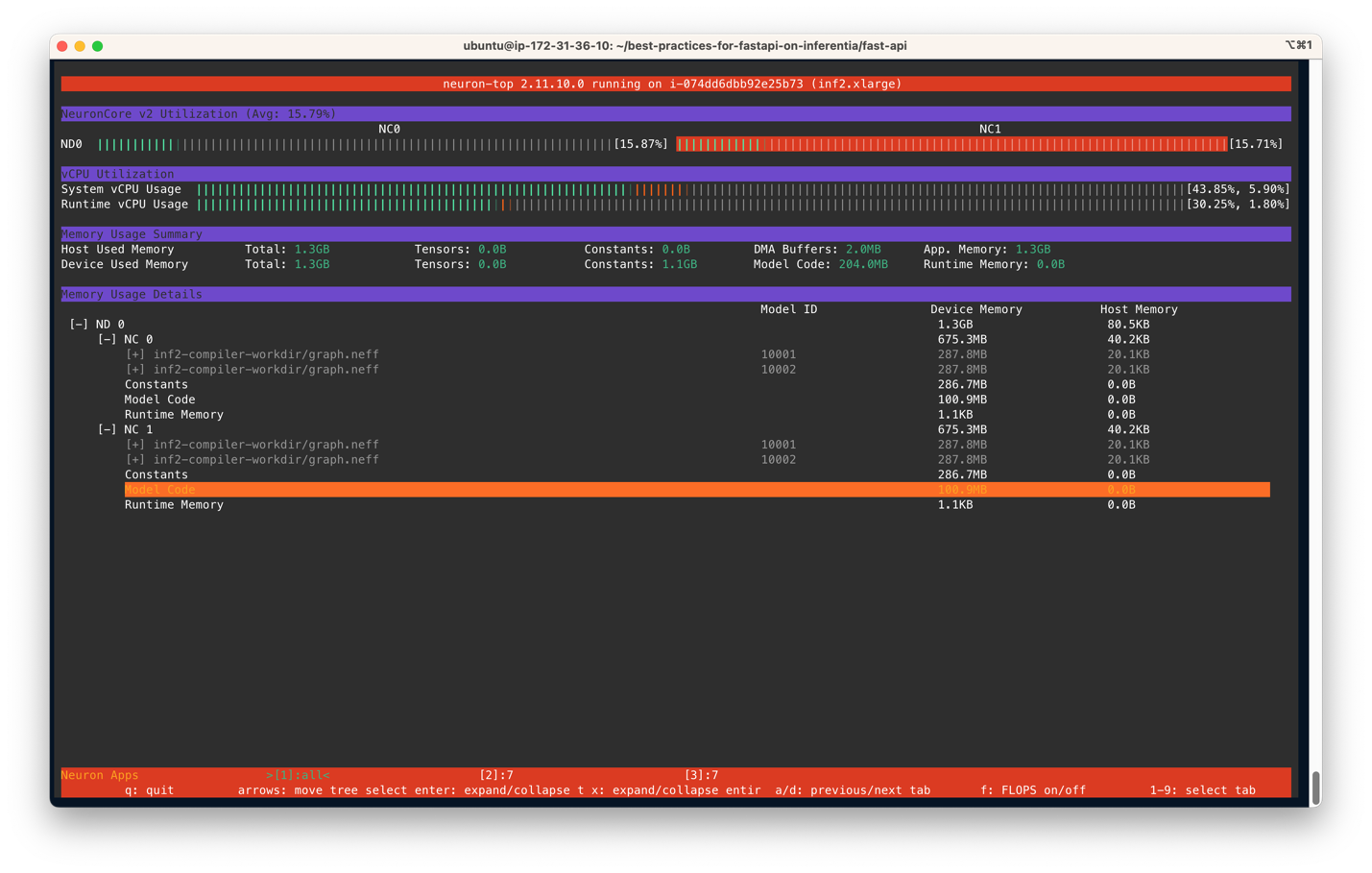
在运行run_apis.py脚本后,您可以查看每个六个NeuronCores的利用率百分比(请参见以下截图)。您还可以查看系统vCPU使用率和运行时vCPU使用率。
以下截图显示了Inf2实例核心使用率百分比。
同样,此截图显示了inf1.6xlarge实例类型中的核心利用率。
清理
要清理您创建的所有Docker容器,我们提供了一个cleanup.sh脚本,该脚本将删除所有正在运行和停止的容器。此脚本将删除所有容器,因此如果您要保留一些容器运行,请不要使用它。
结论
生产工作负载通常具有高吞吐量、低延迟和成本要求。低效的架构可能导致加速器的次优利用,从而导致不必要的高生产成本。在本文中,我们展示了如何使用FastAPI来最大限度地利用NeuronCores,以实现最大吞吐量和最低延迟。我们已在GitHub仓库中发布了这些指令。通过这种解决方案架构,您可以在每个NeuronCore中部署多个模型,并在不损失性能的情况下并行运行多个模型在不同的NeuronCores上。有关如何使用Amazon Elastic Kubernetes Service(Amazon EKS)等服务大规模部署模型的更多信息,请参阅在Amazon EKS上以每小时低于50美元的价格运行3,000个深度学习模型。