从零开始的强化学习动态定价:Q学习
从零开始的强化学习动态定价:Q学习
介绍 Q-Learning 和实际的 Python 示例
目录
- 介绍
- 强化学习基础2.1 关键概念2.2 Q 函数2.3 Q 值2.4 Q-Learning2.5 Bellman 方程2.6 探索与利用2.7 Q-Table
- 动态定价问题3.1 问题描述3.2 实现
- 结论
- 参考文献
1. 介绍
在本文中,我们介绍强化学习的核心概念,并深入探讨 Q-Learning,这种方法使智能代理能够通过基于奖励和经验做出明智决策来学习最优策略。
我们还分享了一个从头开始构建的实际的 Python 示例。具体来说,我们训练一个代理来掌握定价的艺术,这是业务的关键方面,以便它能够学会如何最大化利润。
言归正传,让我们开始我们的旅程。
2. 强化学习基础
2.1 关键概念
强化学习(RL)是机器学习的一个领域,代理通过试错的方式学习完成任务。
- DeepMind研究人员介绍了Reinforced Self-Training(ReST):一种简单的算法,通过Growing Batch Reinforcement Learning(RL)受到人类偏好的启发,用于将LLMs与人类偏好对齐
- 嘿开发者:图表不需要那么复杂
- GPT-4:一机八模型;秘密揭晓
简而言之,代理尝试动作,并通过奖励机制与积极或消极的反馈相关联。代理调整其行为以最大化奖励,从而学习实现最终目标的最佳行动方案。
让我们通过一个实际的例子介绍 RL 的关键概念。想象一个简化的街机游戏,一只猫必须在避开建筑工地的同时穿过迷宫收集宝藏 – 牛奶和毛线球:
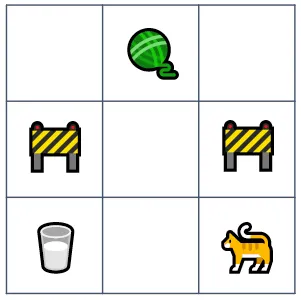
- 代理 是选择行动的人。在这个例子中,代理是控制摇杆决定猫的下一步动作的玩家。
- 环境 是…




