从实验到部署:MLflow 101 | 第01部分
从实验到部署:MLflow 101 | 第01部分' can be condensed to 'MLflow 101 | 第01部分
通过使用Streamlit和MLflow打造垃圾邮件过滤器,提升您的MLOps之旅

为什么❓
想象一下:您有一个全新的商业创意,所需数据就在您的指尖之间。您充满激情地准备着创建那个了不起的机器学习模型🤖。但是,让我们面对现实,这个过程并不容易!您将进行各种试验,处理数据预处理,选择算法,并调整超参数直到让您头晕目眩😵💫。随着项目变得更加复杂,就像试图捕捉烟雾一样——您会忘记所有那些疯狂的实验和出色的创意。相信我,记住所有这些比赶猫更难😹
但是,等等,还有更多!一旦您拥有了那个模型,您还必须像冠军一样部署它!而且随着不断变化的数据和客户需求,您将不得不多次重新训练模型,比您更换袜子的次数还要多!这就像一场永不停息的过山车,您需要一个坚如磐石的解决方案来使一切井然有序🔗。这就是MLOps!这是将混乱变得有序的秘密配方⚡
好了,朋友们,既然我们已经明白了<stron
我们将如何实施它?虽然有多种选择,如 Neptune、Comet 和 Kubeflow 等,但我们将选择 MLflow。因此,让我们熟悉 MLflow 并深入了解其原理。
- Langchain 101 提取结构化数据(JSON)
- VoAGI新闻,8月9日:忘记ChatGPT,这个新的AI助手远超其他 • 掌握数据清洗和预处理技术的7个步骤
- 15个用于开发人员的人工智能工具(2023年8月)
MLflow 101
MLflow 就像机器学习的瑞士军刀一样 —— 它非常多功能且开源,帮助您像老大一样管理整个机器学习过程。它与所有主要的机器学习库(如 TensorFlow、PyTorch、Scikit-learn、spaCy、Fastai、Statsmodels 等)兼容。此外,您还可以将其与您喜欢的任何其他库、算法或部署工具一起使用。此外,它还被设计为超级可定制 —— 您可以轻松添加新的工作流程、库和工具,只需使用自定义插件即可。

MLflow 遵循模块化和基于 API 的设计原则,将其功能分解为四个不同的部分。

现在,让我们逐个检查这些部分!
MLflow Tracking:它是一个允许您在机器学习运行期间记录参数、代码版本、指标和工件,并在以后可视化结果的 API 和 UI。它可以在任何环境中工作,可以将日志记录到本地文件或服务器,并比较多个运行。团队还可以将其用于比较不同用户的结果。Mlflow Projects:它是一种简便地打包和重用数据科学代码的方式。每个项目都是一个带有代码或 Git 存储库的目录,以及一个描述符文件,用于指定依赖项和执行说明。当您使用 Tracking API 时,MLflow 会自动跟踪项目版本和参数,使得从 GitHub 或您的 Git 存储库运行项目并将它们链接到多步骤工作流程变得简单。Mlflow Models:它使您能够以不同的格式打包机器学习模型,并提供各种部署工具。每个模型都保存为一个目录,并包含一个列出其支持的格式的描述符文件。MLflow 提供了将常见模型类型部署到各种平台的工具,包括基于 Docker 的 REST 服务器、Azure ML、AWS SageMaker 和 Apache Spark 用于批处理和流处理推断。当您使用 Tracking API 输出 MLflow Models 时,MLflow 会自动跟踪它们的来源,包括它们来自的项目和运行。Mlflow Registry:它是一个集中式模型存储,具有用于协同管理整个 MLflow 模型生命周期的 API 和 UI。它包括模型血统、版本控制、阶段转换和注释,以便有效管理模型。
这就是我们对 MLflow 提供的基本理解。要获取更详细的信息,请参阅官方文档 👉📄。现在,凭借这些知识,让我们深入探讨第二部分。我们将首先创建一个简单的垃圾邮件过滤应用程序,然后我们将进入完整的实验模式,跟踪不同的实验和独特的运行!
第二部分:实验 🧪 和观察 🔍
好了,准备好迎接一段激动人心的旅程吧!在我们深入实验室并开始进行实验之前,让我们先制定攻击计划,以便知道我们要构建什么。首先,我们将使用随机森林分类器来构建一个垃圾邮件分类器(我知道 Multinomial NB 在文档分类方面效果更好,但是嘿,我们想要尝试一下随机森林的超参数调整)。一开始,我们会故意让它的效果不太好,只是为了刺激一下。然后,我们将释放创造力,跟踪各种运行,调整超参数,并尝试使用诸如词袋模型和 Tfidf 等酷炫的东西。而且猜猜看?我们将像老板一样使用 MLflow UI 进行所有这些跟踪操作,并为下一部分做准备。所以,系好安全带,因为我们将会玩得很开心!🧪💥
与数据融为一体 🗃️
对于这个任务,我们将使用Kaggle上可用的垃圾邮件收集数据集。该数据集包含5,574条英文短信,标记为ham(合法)或spam(垃圾)。然而,数据集存在不平衡,ham标签约为4,825个。为了避免偏差并保持简洁,我决定删除一些ham样本,将其减少到约3,000个,并将结果保存为CSV以供模型和文本预处理进一步使用。根据您的需求选择适合您的方法-这只是为了简洁起见。下面是显示我如何实现这个过程的代码片段。
构建基本的垃圾邮件分类器🤖
现在我们已经准备好数据,让我们迅速地构建一个基本的分类器。我不会用老生常谈告诉你计算机无法理解文本语言,因此需要将其向量化表示。一旦完成这一步骤,我们就可以将其输入到ML/DL算法中。如果您需要复习或有任何疑问,不要担心-我在我之前的一篇博客中已经为您提供了相关内容供您参考。您已经知道这一点了,对吧?🤗
掌握回归模型:预测分析的全面指南
简介
levelup.gitconnected.com
好了,让我们开始吧!我们将加载数据,并对消息进行预处理,以删除停用词、标点符号等。我们甚至会对其进行词干化或词形还原以确保准确性。然后就是令人兴奋的部分-将数据向量化,以获得一些令人惊叹的特征。接下来,我们将拆分数据进行训练和测试,将其适配到随机森林分类器中,并对测试集进行预测。最后,是评估时间,看看我们的模型表现如何!让我们言之凿凿地走下去⚡
在这段代码中,我提供了几个实验选项作为注释,例如使用或不使用停用词进行预处理,词形还原,词干化等。同样地,对于向量化,您可以选择词袋模型、TF-IDF或嵌入。现在,让我们来到有趣的部分!我们将通过依次调用这些函数并传递超参数来训练我们的第一个模型。
是的,我完全同意,这个模型几乎毫无用处。准确率接近零,导致F1得分也接近零。由于我们存在轻微的类别不平衡,F1得分比准确率更重要,因为它提供了精确率和召回率的整体度量-这就是它的魔力所在!所以,这就是我们的第一个可怕、无意义和无用的模型。但是,别担心,这都是学习过程的一部分🪜。
现在,让我们启动MLflow,准备尝试不同的选项和超参数。一旦我们调整好了,一切就会变得有意义起来。我们将能够像专家一样可视化和分析我们的进展!
开始使用MLflow♾️
首先,让我们启动和运行MLflow。为了保持整洁,建议设置一个虚拟环境。您可以简单地使用pip安装MLflow👉pip install mlflow
安装完成后,在终端中运行👉mlflow ui启动MLflow UI(确保在安装MLflow的虚拟环境中)。这将在您的本地浏览器上启动MLflow服务器,托管在http://localhost:5000。您将看到类似于👇的页面

由于我们还没有记录任何内容,所以在UI上没有太多可以查看的。MLflow提供了几个跟踪选项,如本地跟踪、带有数据库的本地跟踪、服务器上的跟踪,甚至可以在云上进行跟踪。对于此项目,我们暂时只使用本地跟踪。一旦我们掌握了本地设置,稍后可以传递跟踪服务器URI并配置一些参数-底层原理保持不变。
现在,让我们来深入了解有趣的部分 – 存储指标、参数,甚至模型、可视化或任何其他对象,也被称为artifacts。
在机器学习开发的背景下,MLflow的跟踪功能可以看作是传统日志记录的演进或替代。在传统的日志记录中,通常会使用自定义字符串格式来记录模型训练和评估过程中的超参数、指标和其他相关细节。这种日志记录方法可能会变得繁琐和容易出错,特别是在处理大量实验或复杂的机器学习流程时,而MLflow自动化了记录和组织信息的过程,使其更容易管理和比较实验,从而实现更高效和可重复的机器学习工作流。
Mlflow Tracking 📈
Mlflow跟踪功能围绕着三个主要函数展开:用于记录参数的log_param,用于记录指标的log_metric,以及用于记录artifacts(例如模型文件或可视化)的log_artifact。这些函数有助于在机器学习开发过程中有组织、标准化地跟踪与实验相关的数据。
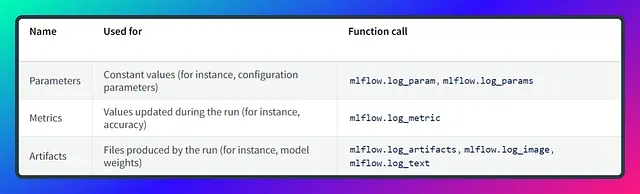
当记录单个参数时,它会以键值对的形式记录在一个元组中。另一方面,当处理多个参数时,您将使用包含键值对的字典。记录指标时也适用相同的概念。以下是一个代码片段,用于说明这个过程。
# 记录一个参数(键值对)log_param("config_value", randint(0, 100))# 记录一个参数字典log_params({"param1": randint(0, 100), "param2": randint(0, 100)})理解实验 🧪 与运行 🏃♀️
实验作为一个容器,代表了一组相关的机器学习运行,为具有共同目标的运行提供了逻辑分组。每个实验都有一个唯一的实验ID,并且您可以为其分配一个易于识别的友好名称。
另一方面,运行对应于实验中机器学习代码的执行。在单个实验中,您可以有多个具有不同配置的运行,并为每个运行分配一个唯一的运行ID。跟踪信息,包括参数、指标和artifacts,存储在后端存储中,例如本地文件系统、数据库(如SQLite或MySQL)或远程云存储(如AWS S3或Azure Blob Storage)。
MLflow提供了统一的API来记录和跟踪这些实验细节,无论使用的后端存储是什么。这种简化的方法允许轻松检索和比较实验结果,增强了机器学习开发过程的透明度和可管理性。
首先,您可以使用mlflow.create_experiment()或更简单的方法mlflow.set_experiment("your_exp_name")创建一个实验。如果提供了一个名称,它将使用现有的实验;否则,将创建一个新的实验来记录运行。
接下来,调用mlflow.start_run()来初始化当前活动的运行并开始记录。在记录必要的信息后,使用mlflow.end_run()关闭运行。
以下是一个基本的代码片段,说明了这个过程:
import mlflow# 创建一个实验(或使用现有的)mlflow.set_experiment("your_exp_name")# 启动运行并开始记录with mlflow.start_run(): # 在此处记录参数、指标和artifacts mlflow.log_param("param_name", param_value) mlflow.log_metric("metric_name", metric_value) mlflow.log_artifact("path_to_artifact")# 运行在'with'块结束时自动关闭使用Streamlit创建超参数调优的用户界面🔥
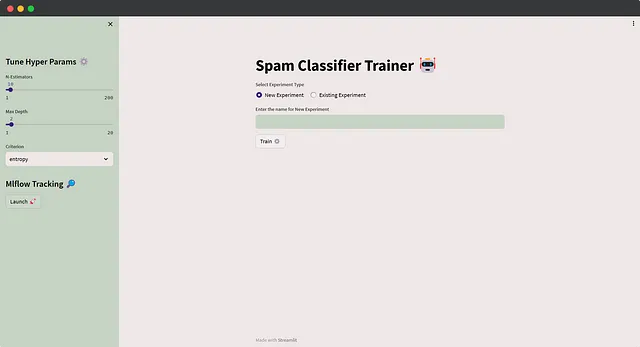
我们将选择一种用户友好的方法,而不是通过shell执行脚本并在那里提供参数。让我们构建一个基本的用户界面,允许用户输入实验名称或特定的超参数值。当单击训练按钮时,它将使用指定的输入调用训练函数。此外,一旦我们保存了大量的运行,我们将探索如何查询实验和运行。
通过这个交互式用户界面,用户可以轻松地尝试不同的配置,并追踪他们的运行,以实现更高效的机器学习开发。我不会深入介绍Streamlit的细节,因为代码很简单。我对之前的train函数进行了微小的调整,以便进行MLflow日志记录,并实现了自定义主题设置。在运行实验之前,用户可以选择输入一个新的实验名称(将运行记录在该实验中),或从下拉菜单中选择一个现有的实验,该菜单是使用mlflow.search_experiments()生成的。此外,用户可以根据需要轻松地微调超参数。以下是应用程序的代码👇
以下是应用程序的外观🚀
好了,是时候暂时告别了👋,但不要担心——我们将在本博客系列的下一部分重新相聚🤝。在即将到来的部分中,我们将深入研究实验,并将我们的模型放入笼子里进行对决,只有最好的模型才能在MLflow Tracking的角斗场中获得成功🦾。一旦你进入了状态,你就不会想要暂停,所以拿杯咖啡🍵,充电🔋,并加入我们进行下一个激动人心的章节⚡。这是第02部分的链接👇
VoAGI
编辑描述
pub.towardsai.net
我们在那里见👀





