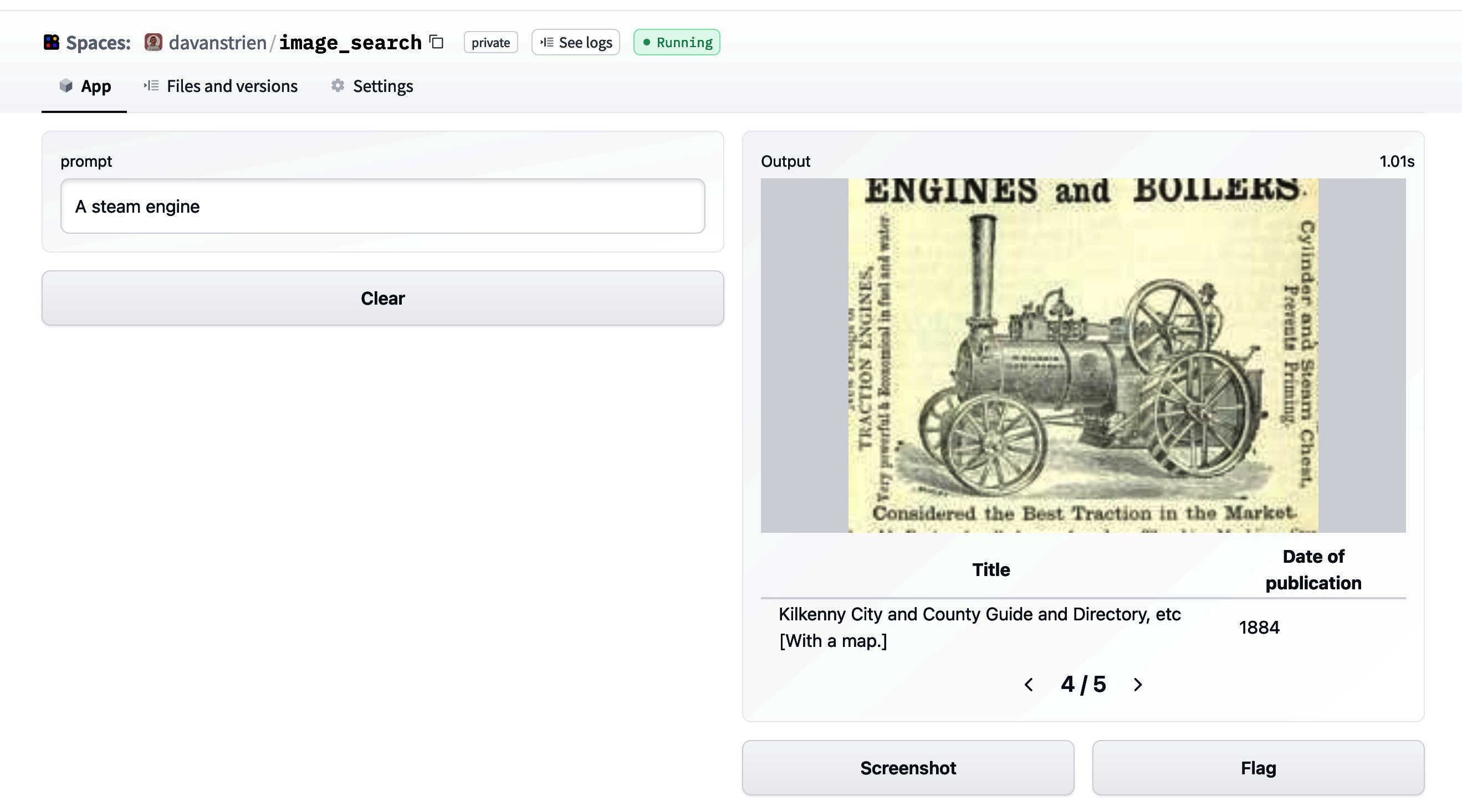
介绍数据测量工具:一个用于查看数据集的交互式工具
介绍数据测量工具:一个交互式的用于查看数据集的工具
tl;dr: 我们制作了一个在线工具,可以用来构建、衡量和比较数据集。
点击此处访问 🤗 数据测量工具。
作为机器学习数据集快速增长的统一存储库的开发者(Lhoest等人,2021年),🤗 Hugging Face团队一直致力于支持数据集文档化的良好实践(McMillan-Major等人,2021年)。尽管静态(如果是不断发展的)文档代表了这个方向上的必要第一步,但要真正了解数据集的内容,需要有明确动机的测量方式以及与之交互的能力,以动态可视化感兴趣的不同方面。
为此,我们介绍了一个名为 🤗 数据测量工具 的开源Python库和无代码界面,该工具使用我们的数据集和空间中心(Dataset and Spaces Hubs)与Streamlit工具相结合。这可以帮助理解、构建、策划和比较数据集。
🤗 数据测量工具是什么?
数据测量工具(DMT)是一个交互界面和开源库,允许数据集创建者和用户自动计算有意义且对负责任的数据开发有用的度量指标。
为什么我们创建了这个工具?
在人工智能开发中,对机器学习数据集的深思熟虑的策划和分析经常被忽视。目前在人工智能中,“大数据”的常规做法(Luccioni等人,2021年;Dodge等人,2021年)包括使用从各个网站上爬取的数据,对不同数据来源所代表的具体测量结果以及它们对模型学习的影响往往不予考虑。虽然数据集注释方法可以帮助策划与开发人员目标更符合的数据集,但对于“测量”这些数据集的不同方面的方法相当有限(Sambasivan等人,2021年)。
人工智能领域的新一波研究呼吁进行基本的范式转变,改变对机器学习数据集的处理方式(Paullada等人,2020年;Denton等人,2021年)。这包括从一开始就定义数据集创建的细致要求(Hutchinson等人,2021年),在考虑有问题的内容和偏见问题时策划数据集(Yang等人,2020年;Prabhu和Birhane,2020年),以及明确数据集构建和维护中固有价值观(Scheuerman等人,2021年;Birhane等人,2021年)。尽管有普遍共识认为数据集开发是许多不同学科的人都能参与的任务,但实际上在与原始数据本身进行交互时常常存在瓶颈,这往往需要复杂的编码技能才能分析和查询数据集。
尽管如此,公开提供给公众的用于测量、审查和比较数据集的工具很少。我们的目标是帮助填补这一空白。我们从最近的工具(如Know Your Data和Data Quality for AI)以及数据集文档化的研究提案(如Vision and Language Datasets(Ferraro等人,2015年)、Datasheets for Datasets(Gebru等人,2018年)和Data Statements(Bender和Friedman,2019年))中学习和构建。结果是一个用于数据集测量的开源库,以及一个配套的无代码界面,用于详细分析数据集。
我什么时候可以使用 🤗 数据测量工具?
🤗 数据测量工具可以用于对一个或多个现有的自然语言处理数据集进行探索性研究,并很快将支持从零开始迭代开发数据集。它提供了研究数据集和负责任数据集开发的可行洞察,使用户能够关注高级信息和具体项目。
使用 🤗 数据测量工具,我可以学到什么?
数据集基础知识
对数据集的高级概述
这有助于回答“这个数据集是什么?它是否有缺失项?”等问题。您可以将其用作对所使用的数据集进行“合理性检查”的参考。
-
数据集描述(来自Hugging Face Hub)
-
缺失值或NaN的数量
描述性统计
用于查看数据集的表面特征
这些开始回答的问题包括“这个数据集中有什么样的语言?它有多种多样?”
-
数据集词汇量和词语分布,包括开放类和闭合类词语。
-
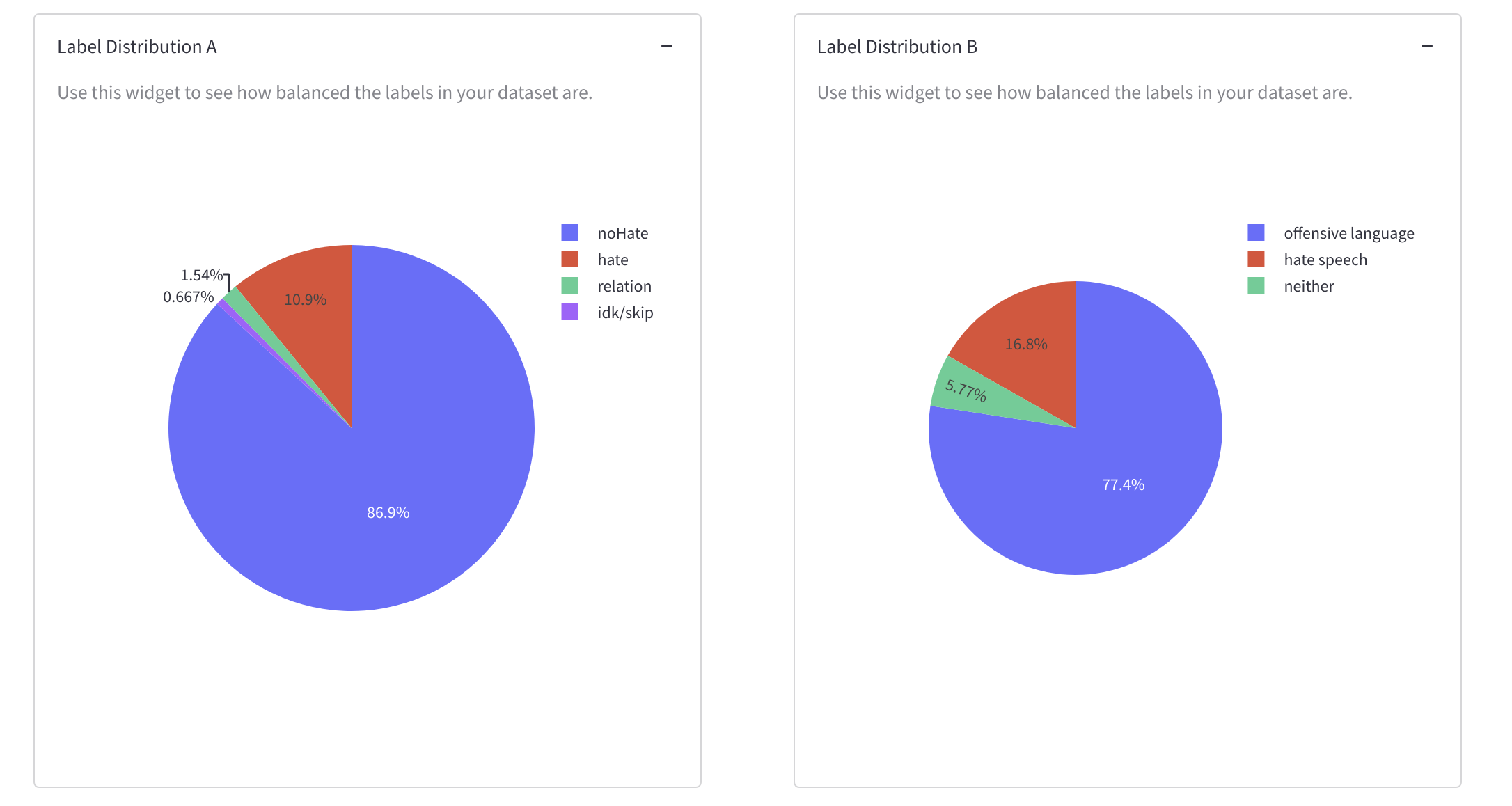
数据集标签分布和有关类别(不)平衡的信息。
-
实例长度的均值、中位数、范围和分布。
-
数据集中的重复项数量及其重复次数。
您可以使用这些小部件检查数据集中最常见和最不常见的内容是否符合数据集的目标。这些测量旨在确定数据集是否能够捕捉各种上下文,或者它捕捉的范围更有限,并且用于衡量标签和实例长度的“平衡”程度。您还可以使用这些小部件识别您可能想要删除的异常值和重复项。
分布统计
用于测量数据集中的语言模式
这些开始回答的问题包括“这个数据集中的语言行为如何?”
- 遵循Zipf定律,提供数据集中词语分布与自然语言中预期词语分布的接近程度的测量。
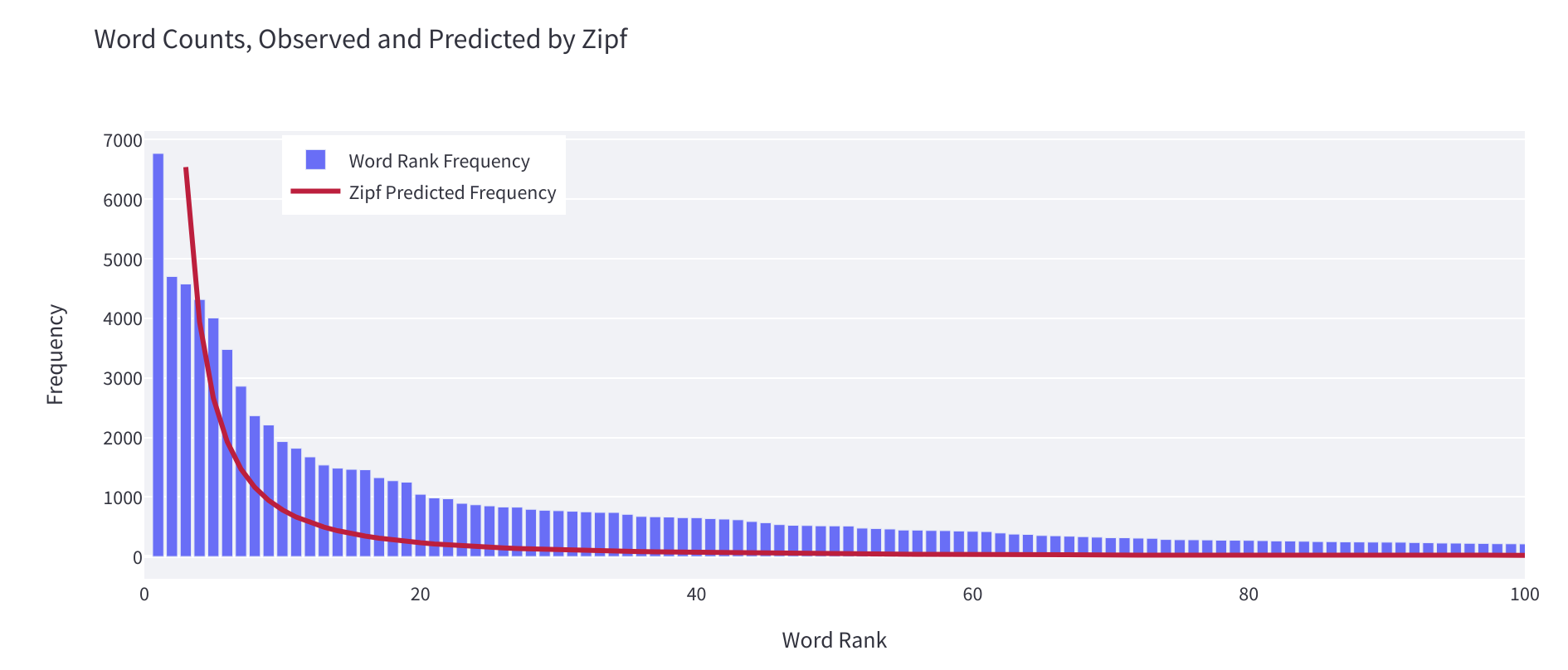
您可以使用这个工具来确定数据集是否以自然语言的行为方式表示,或者是否存在更不自然的情况。如果您是一个喜欢优化的人,您可以将这个工具计算出的alpha值视为在数据集开发过程中尽可能接近1的价值。有关不同语言中遵循Zipf定律的alpha值的更多详细信息,请参阅这里。
通常情况下,大于2的alpha值或大于10的最小排名(请谨慎对待)意味着您的分布对于自然语言来说相对不自然。这可能是数据集中混合工件(例如HTML标记)的迹象。您可以使用这些信息清理数据集,或者指导您确定如何分布添加到数据集中的进一步语言。
比较统计
这些开始回答的问题包括“这个数据集中有什么样的主题、偏见和关联?”
-
嵌入聚类,以确定数据集中相似语言的聚类。当数据集由数百到数十万个句子组成时,考虑到所表示的文本的多样性可能具有挑战性。根据相似性度量对这些文本项进行分组可以帮助用户获得一些有关它们分布的见解。我们展示了基于Sentence-Transformer模型和最大点积单链接准则的数据集中文本字段的分层聚类。您可以通过以下方式探索这些聚类:
- 将鼠标悬停在一个节点上,查看5个最具代表性的示例(去重)
- 在文本框中输入一个示例,查看它与哪些叶节点聚类最相似
- 按ID选择一个聚类,显示其所有示例
-
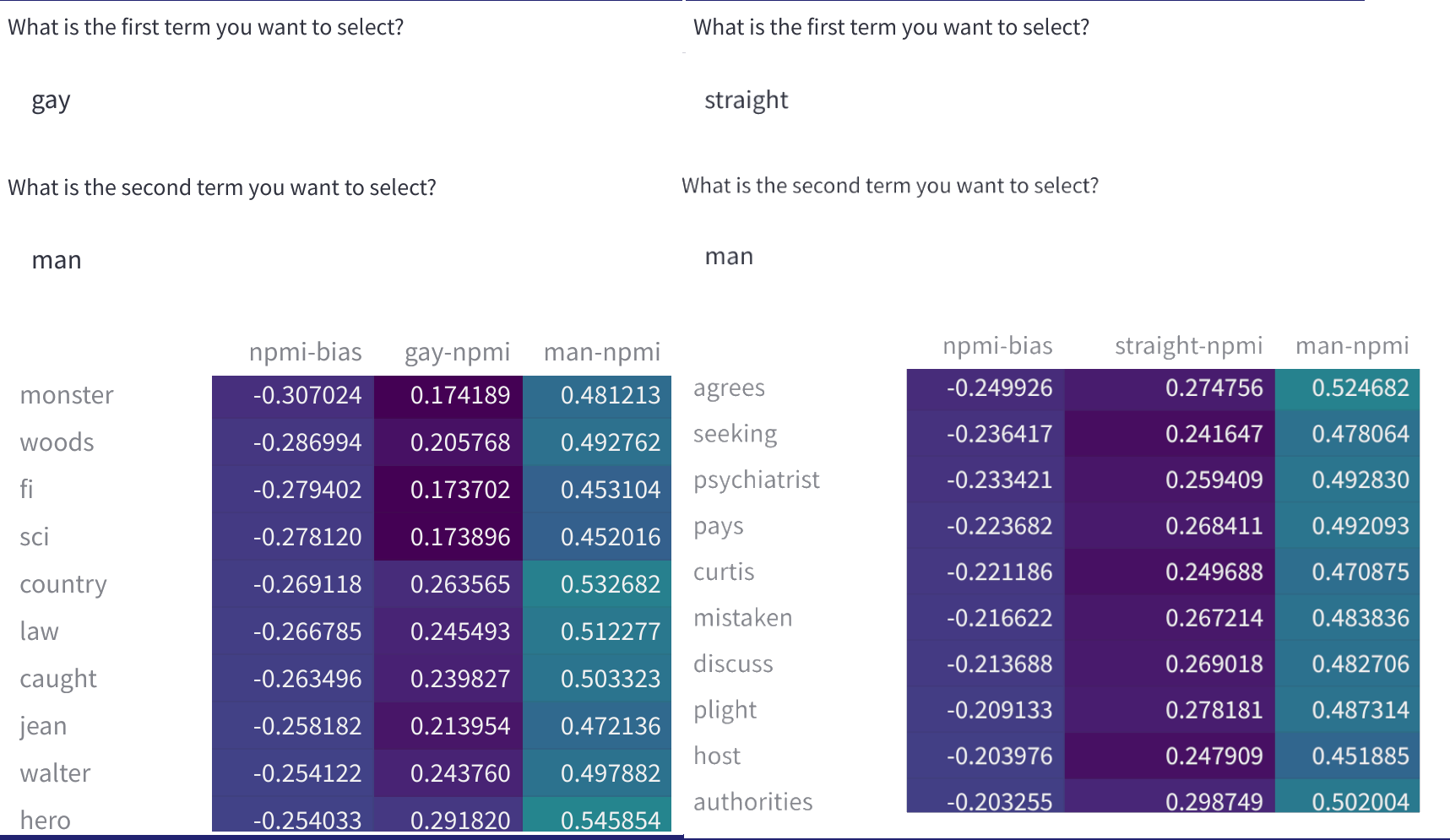
数据集中词语对之间的归一化点互信息(nPMI),可用于识别有问题的刻板印象。您可以将其用作处理数据集“偏见”的工具,这里的“偏见”是指在性别和性取向等身份群体的轴上的刻板印象和偏见。我们将在不久的将来添加更多术语。
🤗数据测量工具的开发状态如何?
我们目前提供该工具的Alpha版本(v0),演示了其在一些热门的英语数据集(例如SQuAD、imdb、C4等)上的实用性,这些数据集可在Dataset Hub上获得,并具备上述功能。我们选择用于nPMI可视化的词语是在我们处理的数据集中频繁出现的身份术语的子集。
在未来的几周和几个月内,我们将扩展该工具以实现以下功能:
- 覆盖更多语言和🤗 Datasets库中的数据集。
- 支持用户提供的数据集和迭代式数据集构建。
- 为工具本身添加更多功能和功能。例如,我们将使您能够为nPMI可视化添加自己的术语,这样您就可以选择最重要的词。
致谢
感谢Thomas Wolf发起此工作,以及🤗团队的其他成员(Quentin,Lewis,Sylvain,Nate,Julien C.,Julien S.,Clément,Omar等等!)对他们的帮助和支持。