“从零开始训练BERT的终极指南:分词器”
Ultimate Guide to Training BERT from Scratch Tokenizer
从文本到标记:BERT标记化的逐步指南

你知道吗,文本的标记化方式可以决定你的语言模型的成败?你是否曾经想过如何在罕见的语言或专业领域中进行文本的标记化?将文本分割成标记不仅是一项繁琐的任务,更是将语言转化为可操作智能的关键。本文将教会你关于标记化的一切,不仅适用于BERT,还适用于其他任何LLM。
在我上一篇文章中,我们讨论了BERT,并探索了它的理论基础和训练机制,并讨论了如何微调它和创建一个问答系统。现在,随着我们深入探讨这个开创性模型的复杂性,是时候关注其中一个不为人知的英雄了:标记化。
从零开始训练BERT的终极指南:介绍
揭秘BERT:改变NLP领域的模型的定义和各种应用。
towardsdatascience.com
我明白,标记化可能看起来像是你和训练模型这个激动人心过程之间最后一个无聊的障碍。相信我,我曾经也是这样想的。但我在这里告诉你,标记化不仅仅是一种“必要之恶”,它本身就是一种艺术形式。
在本文中,我们将审查标记化流程的每个部分。有些步骤是琐碎的(比如归一化和预处理),而其他步骤,比如建模部分,是使每个标记器独特的地方。
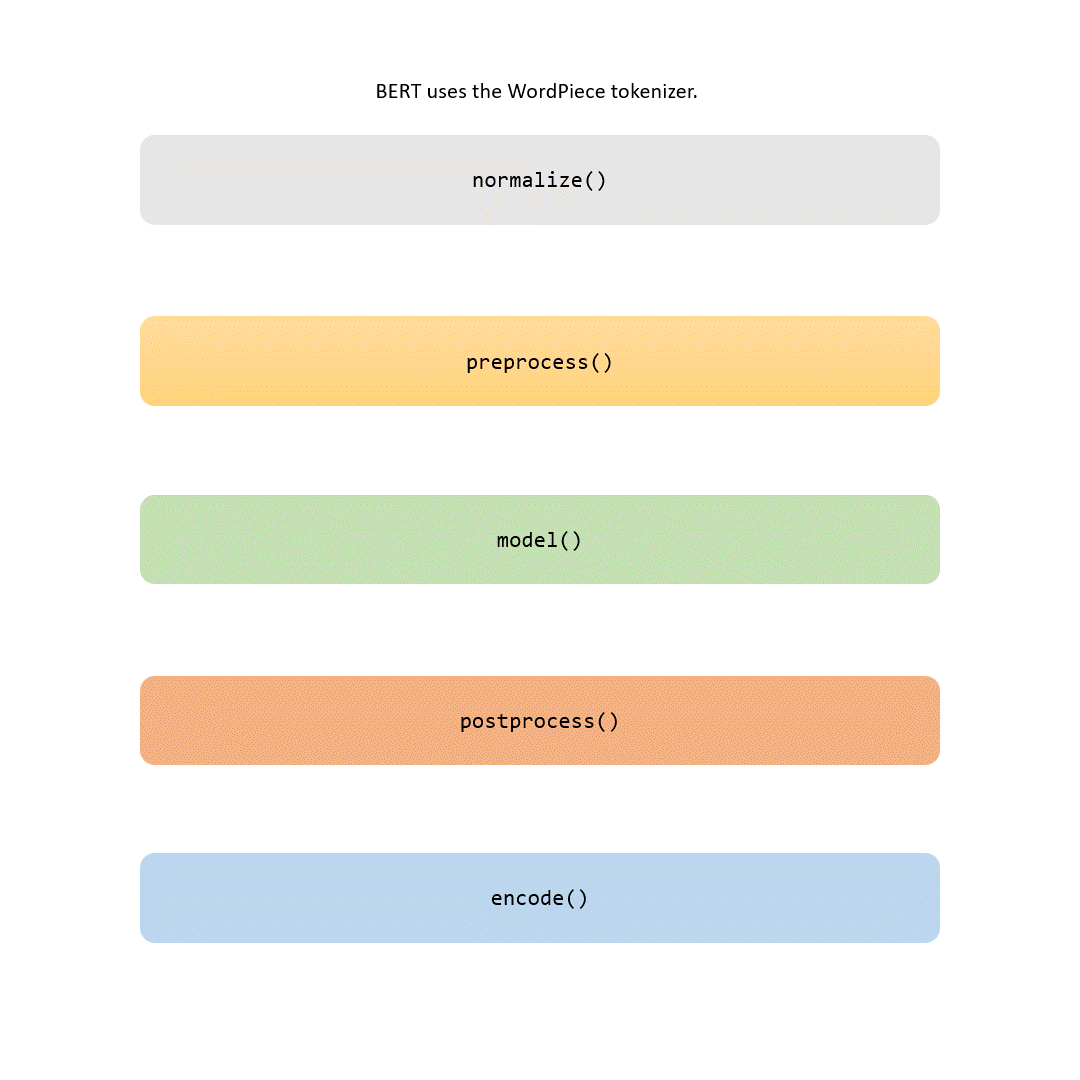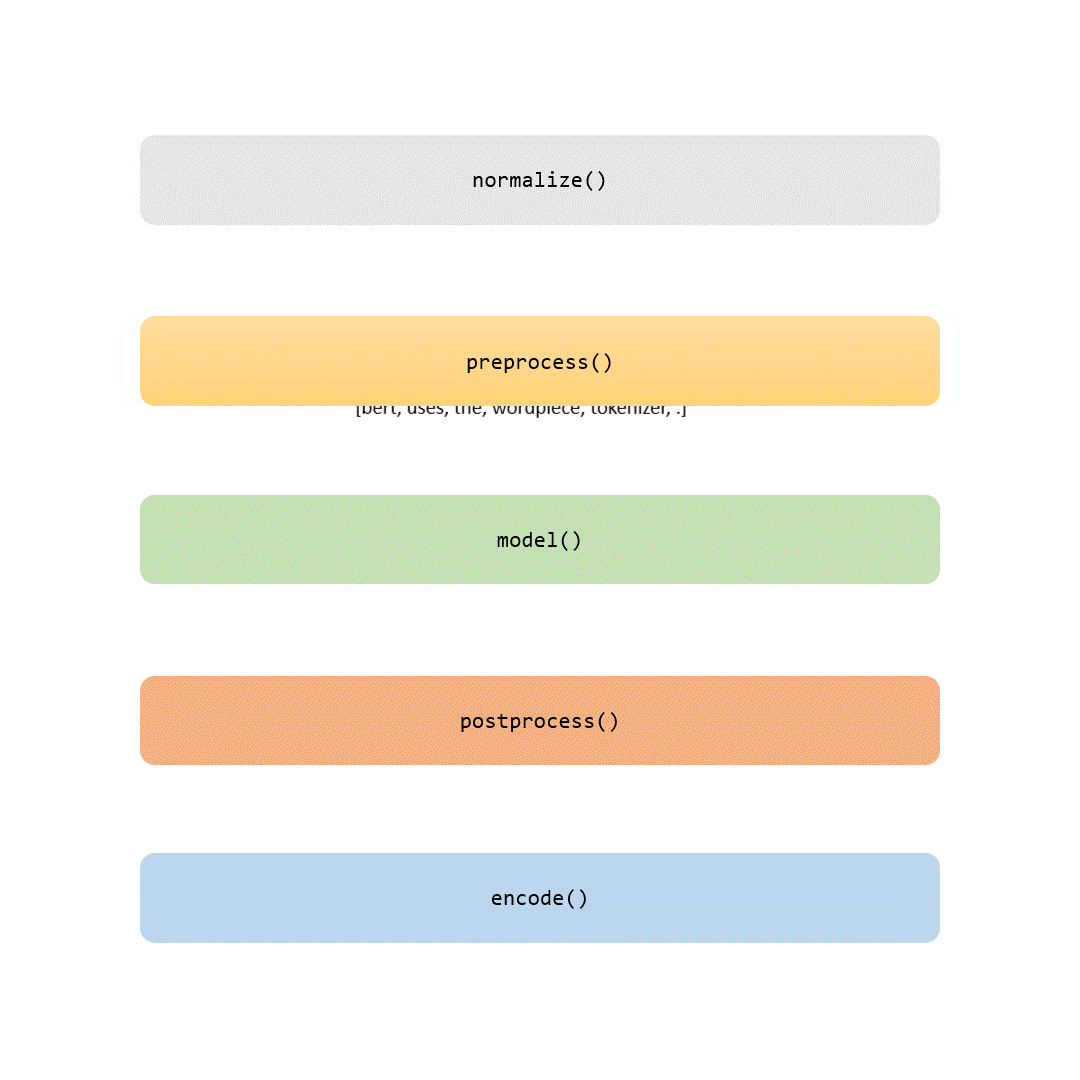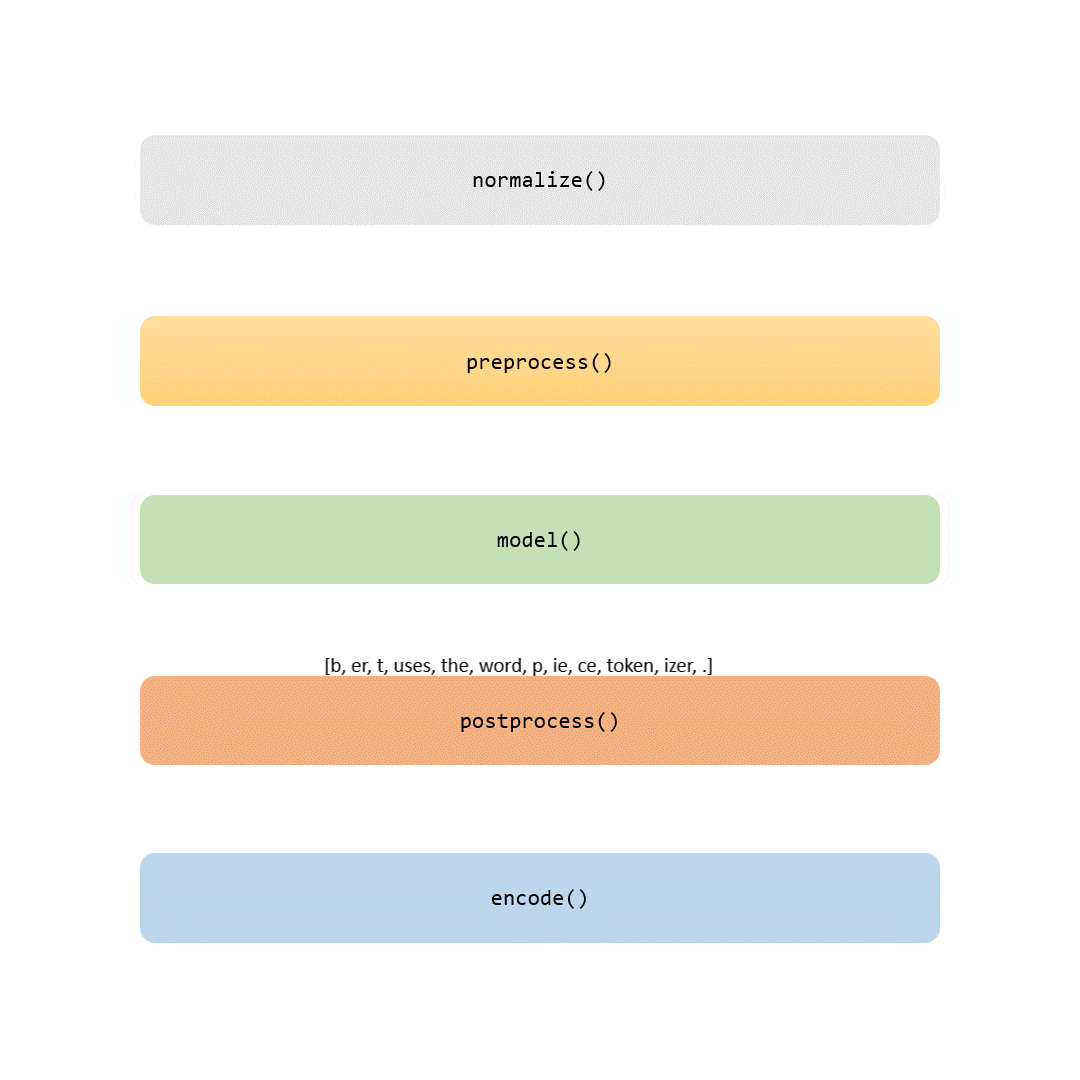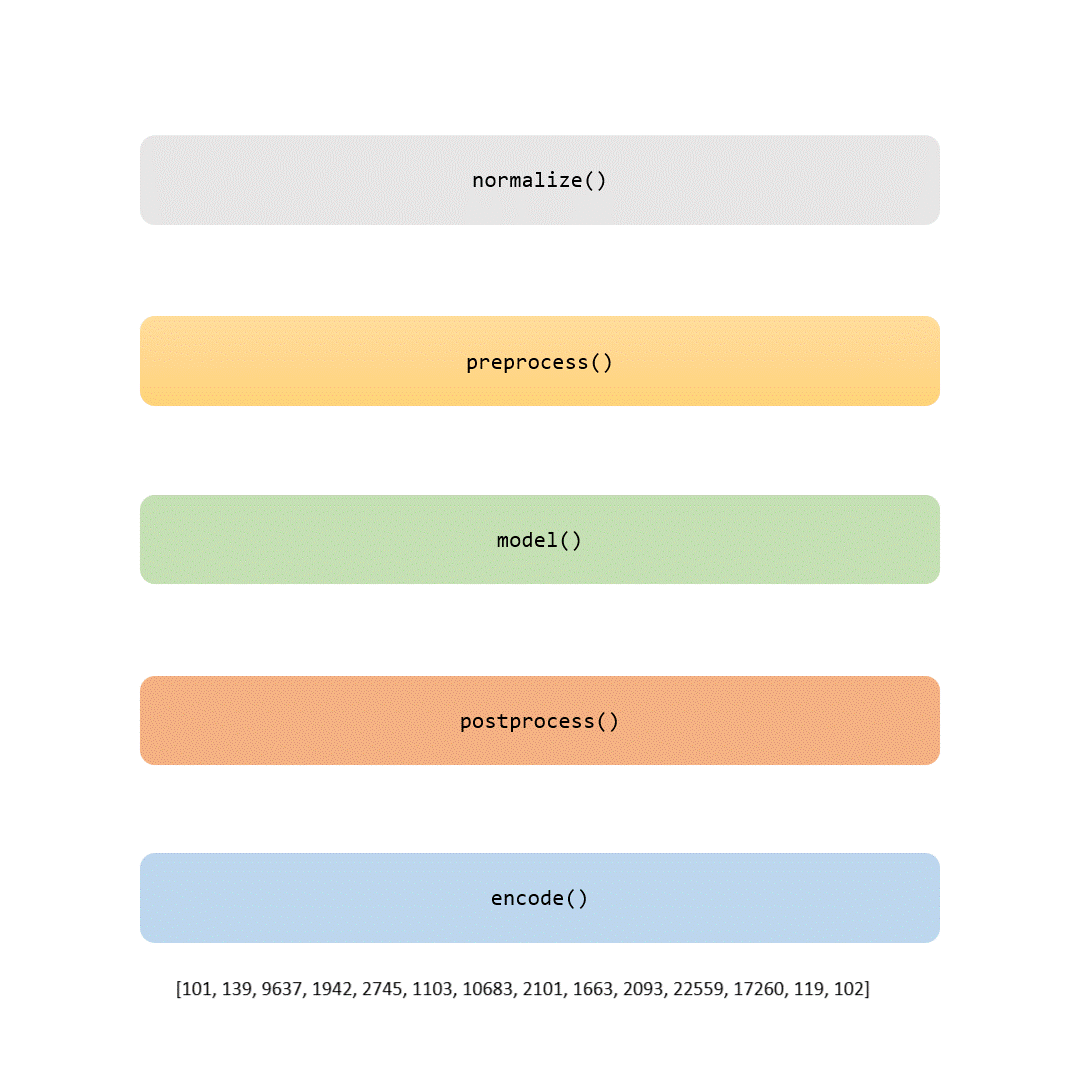
当你完成阅读本文时,你不仅会理解BERT标记器的各个方面,还能够用自己的数据训练它。如果你感到有冒险精神,你甚至可以在从零开始训练自己的BERT模型时自定义这一关键步骤的工具。
将文本分割成标记不仅仅是一项繁琐的任务,更是将语言转化为可操作智能的关键…