语义层:AI驱动的数据体验的支撑
语义层:AI驱动的数据体验的支撑' 趋势解读与全球案例分享
赞助内容
这个指南,”每个语义层的五个关键要素“,可以帮助您了解现代语义层的广度。
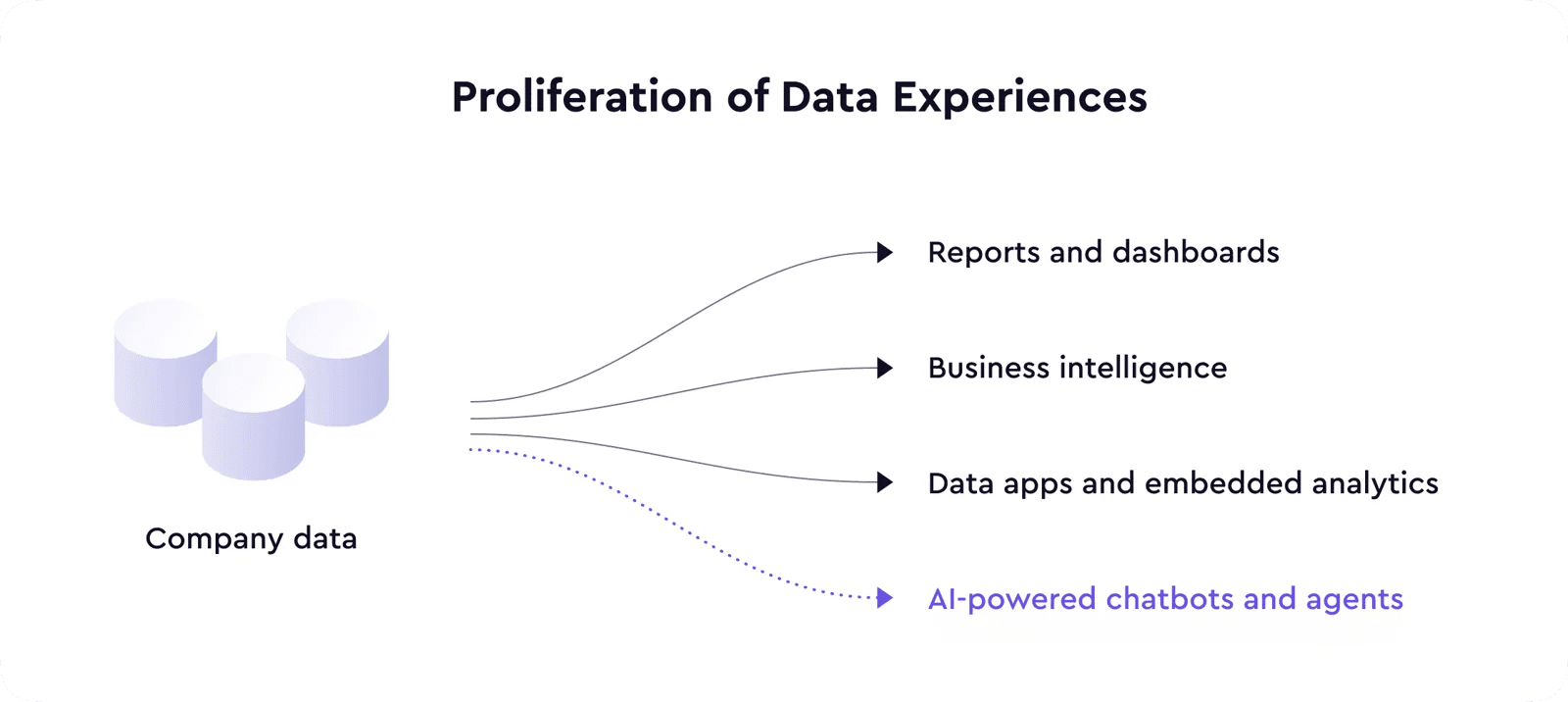
AI驱动的数据体验
前端技术的演进使得将优质分析体验直接嵌入许多软件产品成为可能,进一步加速了数据产品和体验的普及。
- 斯坦福大学、NVIDIA和德克萨斯大学奥斯汀分校的研究人员提出了跨剧集课程(CEC):一种新的人工智能算法,可以提高转换器代理的学习效率和泛化能力
- 当涉及复杂话题时,第一步是最困难的
- 流体扩散转换器的拓扑概括化 (Liútǐ kuòsàn zhuǎnhuànqì de tuòpū gàigé huà)
现在,随着大型语言模型的出现,我们又迎来了技术的飞跃,它将在多个用例和领域中实现许多新功能,甚至可以诞生一个全新的产品类别,包括数据。
利用AI驱动的数据体验,LLM将数据消费层推向了一个新的高度,从聊天机器人回答您关于业务数据的问题,到AI代理根据数据中的信号和异常执行操作。
语义层为LLM提供上下文
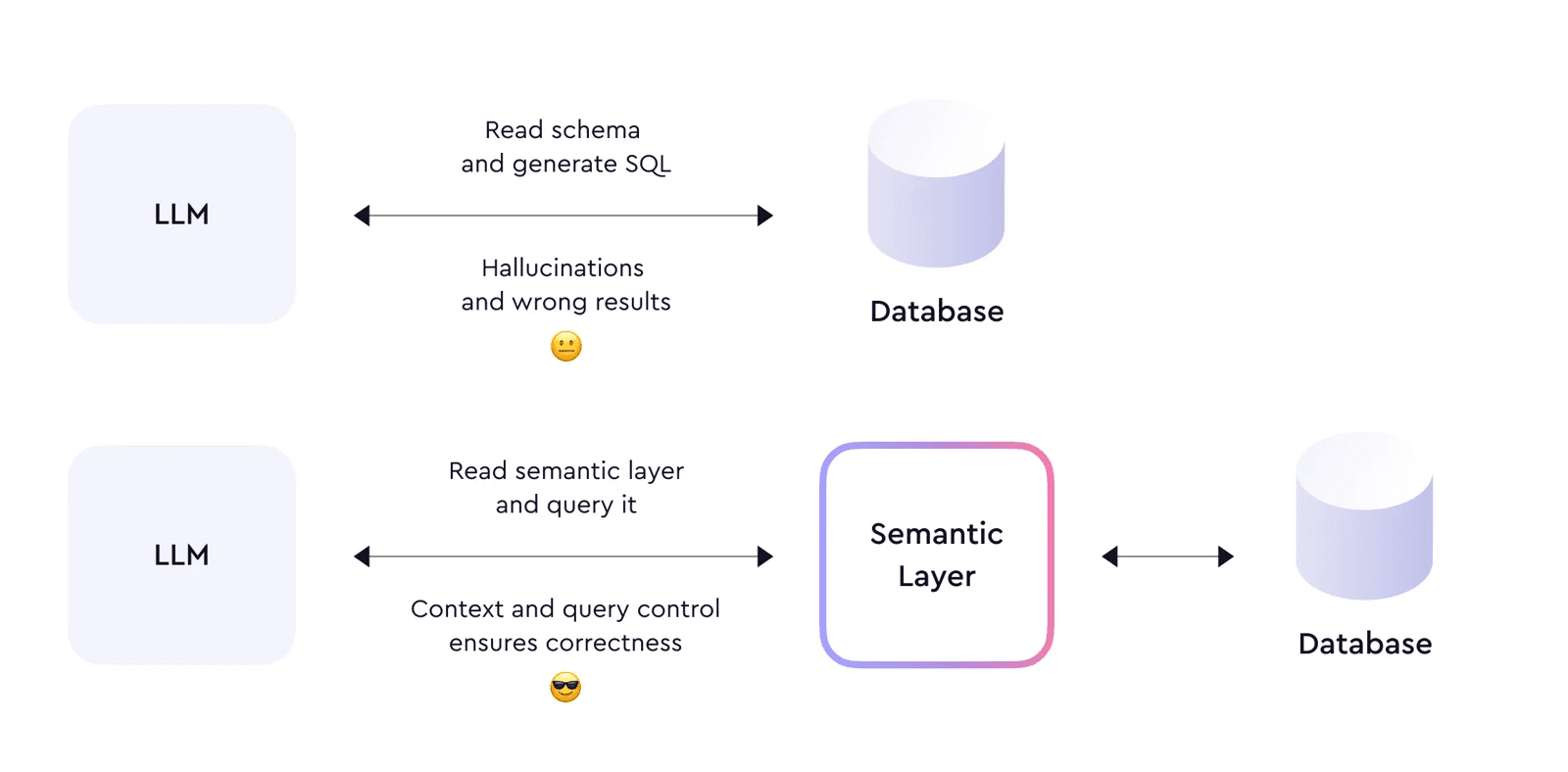
确实,LLM是一个飞跃,但不可避免地,就像每项技术一样,它也有其局限性。LLM会产生幻觉;垃圾进,垃圾出的问题从来没有如此严重。让我们这样想一想:当人类难以理解不一致和无组织的数据时,LLM只会加剧混乱,产生错误答案。
我们不能给LLM提供数据库模式,期望它生成正确的SQL。为了正确运行和执行可信赖的操作,它需要具备足够的上下文和语义,了解它所消费的数据的指标、维度、实体和关系方面。基本上,LLM需要一个语义层。
语义层将数据组织成有意义的业务定义,然后允许对这些定义进行查询,而不是直接查询数据库。
‘查询’应用与‘定义’同等重要,因为它强制LLM通过语义层查询数据,确保查询和返回数据的正确性。通过这种方式,语义层解决了LLM幻觉问题。
此外,将LLM和语义层结合起来可以实现新一代的AI驱动数据体验。在Cube公司,我们已经见证了许多组织构建定制的内部LLM驱动应用程序,而像Delphi这样的初创公司则在Cube的语义层上构建了开箱即用的解决方案(示例在这里)。
在这个发展的前沿,我们看到Cube作为现代AI技术栈的一个重要组成部分,它位于数据仓库之上,为AI代理提供上下文,并作为查询数据的接口。
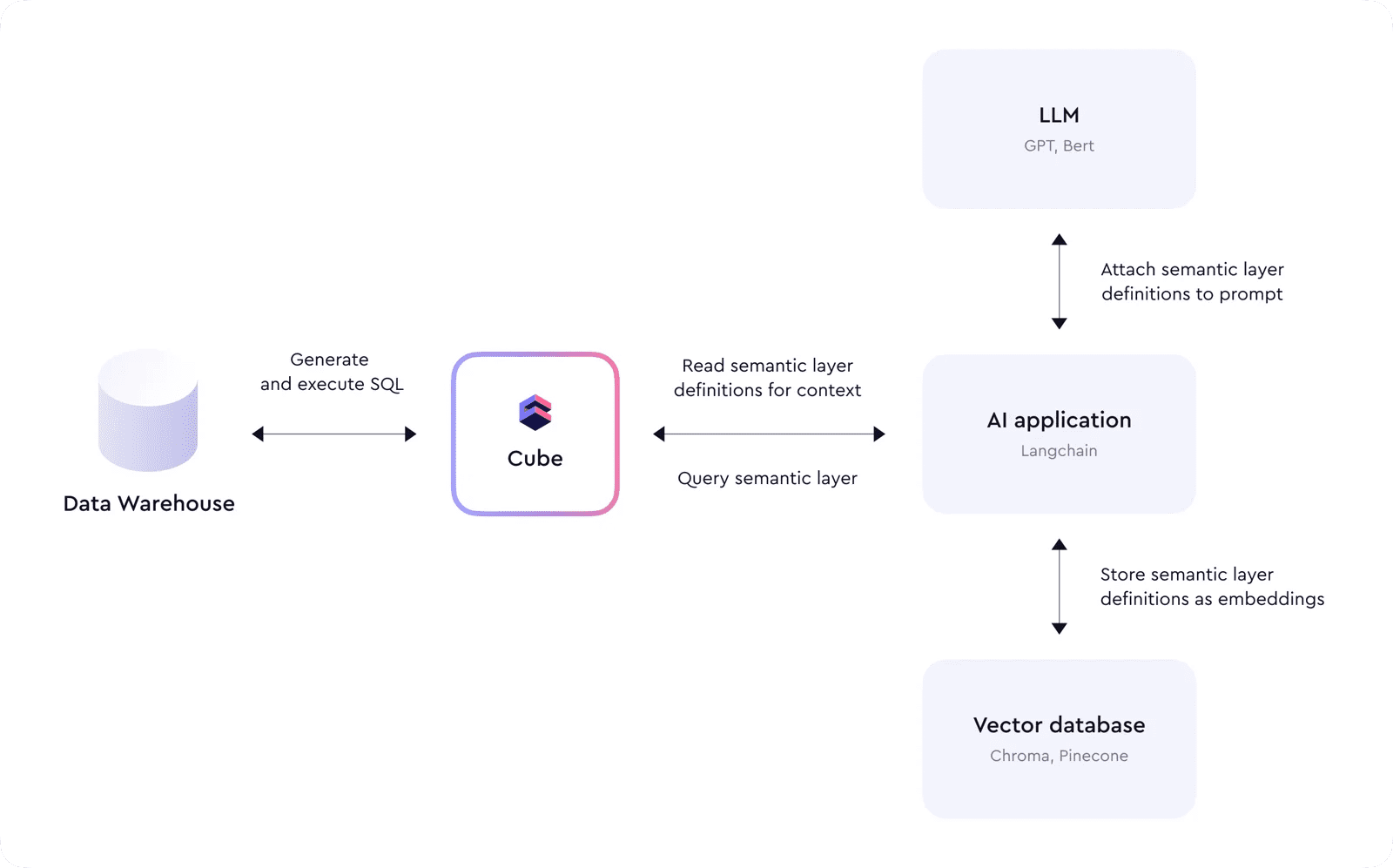
Cube的数据模型为LLM提供了结构和定义,作为理解数据并生成正确查询的上下文。LLM不需要处理复杂的连接和指标计算,因为Cube将其抽象化,并提供了一个简单的界面,其操作基于业务级术语而不是SQL的表和列名。这种简化有助于减少LLM的错误,并避免产生幻觉。
例如,一个基于AI的应用程序首先会读取Cube的元API端点,将语义层的所有定义下载,并将它们存储为嵌入向量数据库中的嵌入。稍后,当用户发送一个查询时,这些嵌入将被用于提示LLM提供附加上下文。LLM将回复一个生成的查询给Cube,然后应用程序将执行它。这个过程可以进行多次的链式重复,以回答复杂的问题或创建摘要报告。
性能
在处理复杂查询和任务时,AI系统可能需要多次查询语义层,应用不同的筛选条件。
因此,为了保证合理的性能,这些查询必须被缓存,而不总是推送到底层的数据仓库。Cube提供了一个关系式高速缓存引擎,构建原始数据之上的预聚合,并实现聚合意识以在可能的情况下将查询路由到这些聚合。
安全
最后,当构建基于AI的应用程序时,安全性和访问控制绝不能是事后思考。如上所述,生成原始SQL并在数据仓库中执行可能导致错误结果。
然而,人工智能还存在额外的风险: 由于无法控制且可能生成任意的SQL语句,AI与原始数据存储之间的直接访问也可能成为一个重大的安全漏洞。相反,通过语义层生成SQL语句可以确保实施细粒度的访问控制策略。
更多信息…
我们将与AI生态系统进行许多令人兴奋的集成,并迫不及待与您分享。同时,如果您正在开发AI驱动的应用程序,请考虑免费测试Cube Cloud。
下载指南“每个语义层的五个基本特征”以获取更多信息。






