R和brms在学校毕业生结果上的贝叶斯比较
R和brms的学生结果比较
ANOVA — 贝叶斯风格
我们对离开学校后要做什么很关注。我们被问到我们长大后想做什么,然后继续在13年的学前教育中度过。在公共政策中,政府、天主教和独立学校系统之间的差异被广为关注,特别是当涉及非政府学校的公共资金和资源分配时。
在澳大利亚维多利亚州,州政府每年进行一项调查来了解高中毕业后的结果(On Track Survey)。该数据集(根据CC BY 4.0可用)可在多年中获得,我们只会查看最近一年的数据,即本文撰写时的2021年。
本文将使用贝叶斯分析方法(使用R包brms)来回答这些问题。
加载库和数据集
下面我们加载所需的软件包,数据集以宽报告格式呈现,其中包含许多合并的单元格。R不喜欢这样,所以我们需要进行一些硬编码来重新标记向量并创建一个整洁的数据框。
library(tidyverse) #Tidyverse元包library(brms) #贝叶斯建模包library(tidybayes) #用于贝叶斯模型的整洁辅助函数和可视化几何图形library(readxl)df <- read_excel("DestinationData2022.xlsx", sheet = "SCHOOL PUBLICATION TABLE 2022", skip = 3)colnames(df) <- c('vcaa_code', 'school_name', 'sector', 'locality', 'total_completed_year12', 'on_track_consenters', 'respondants', 'bachelors', 'deferred', 'tafe', 'apprentice_trainee', 'employed', 'looking_for_work', 'other') df <- drop_na(df)以下是我们数据集的示例。
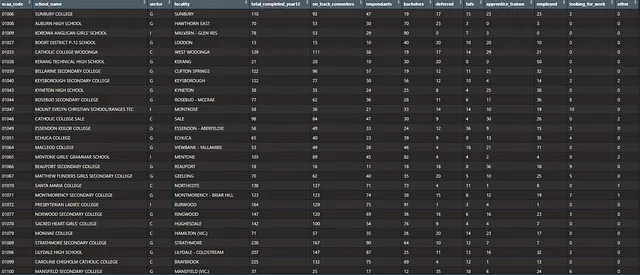
数据集有14个字段。
- VCAA Code — 每个代码的管理ID
- 学校名称
- 部门 — G = 政府, C = 天主教 & I = 独立
- 地点或郊区
- 完成12年级的学生总数
- On Track Consenters
- 调查受访者
- 其余列表示每个结果的受访者比例
为了进行我们的横断面研究,我们对部门的结果比例感兴趣,因此我们需要将这个宽数据框转换为长格式。
df_long <- df |> mutate(across(5:14, ~ as.numeric(.x)), #将所有数值字段转换为字符 across(8:14, ~ .x/100 * respondants), #从比例计算计数 across(8:14, ~ round(.x, 0)), #四舍五入为整数 respondants = bachelors + deferred + tafe + apprentice_trainee + employed + looking_for_work + other) |> #重新计算总受访者 |> filter(sector != 'A') |> #低占比 select(sector, school_name, 7:14) |> pivot_longer(c(-1, -2, -3), names_to = 'outcome', values_to = 'proportion') |> mutate(proportion = proportion/respondants)
探索性数据分析
让我们简要地对数据集进行可视化和总结。在这个数据集中,政府部门有157所学校,独立学校有57所,天主教学校有50所。
df |> mutate(sector = fct_infreq(sector)) |> ggplot(aes(sector)) + geom_bar(aes(fill = sector)) + geom_label(aes(label = after_stat(count)), stat = 'count', vjust = 1.5) + labs(x = '部门', y = '数量', title = '按部门统计的学校数量', fill = '部门') + scale_fill_viridis_d(begin = 0.2, end = 0.8) + theme_ggdist()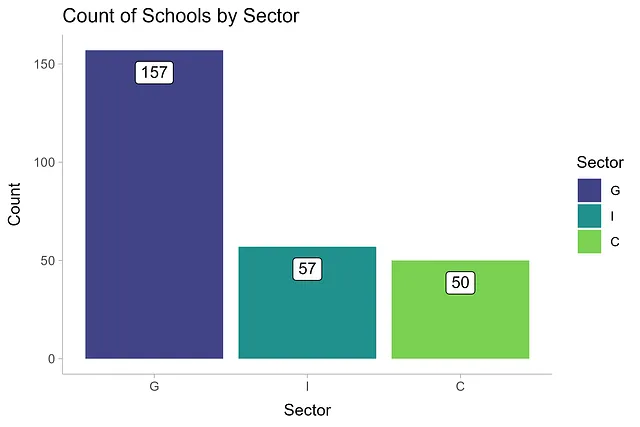
df_long |> ggplot(aes(sector, proportion, fill = outcome)) + geom_boxplot(alpha = 0.8) + geom_point(position = position_dodge(width=0.75), alpha = 0.1, color = 'grey', aes(group = outcome)) + labs(x = '部门', y = '比例', fill = '结果', title = '按部门和结果划分的比例箱线图') + scale_fill_viridis_d(begin = 0.2, end = 0.8) + theme_ggdist()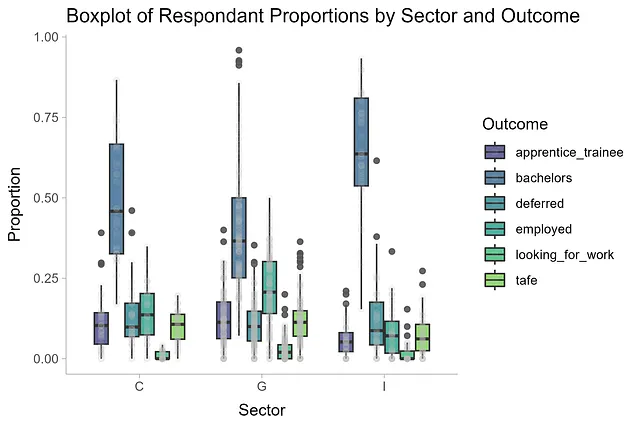
这些分布讲述了一个有趣的故事。学士学位结果在所有部门中的变异性最大,独立学校的学生比例选择攻读本科教育最多。有趣的是,政府学校在高中毕业后就业的学生比例中位数最高。其他结果变化不大,我们将很快回顾这一点。
统计建模 — Beta似然回归
我们关注的是学生在学校就读期间以及高中毕业后的结果比例。在这种情况下,贝塔似然是我们最好的选择。brms是Buerkner开发的一个出色的包,用于开发贝叶斯模型。我们的目标是对结果和部门的比例分布进行建模。
贝塔回归模型有两个参数,μ和φ。μ表示比例的均值,φ表示精度(或方差)。
我们的第一个模型如下所示,请注意我们已经从Sector和Outcome之间开始进行交互,因为这是我们想要模型回答的问题,因此这是一个方差分析模型。
我们要求模型为每个Sector和Outcome的组合创建单独的Beta项,带有一个汇总的φ项,或者用相同的方差模拟不同的比例均值。我们期望这些比例中有50%位于logit比例尺上的(-3, 1)之间,或者在比例上是(0.01, 0.73)。这个范围足够宽广,但也是有先验知识的。全局Phi估计是一个正数,所以我们使用了一个足够宽广的伽马分布。
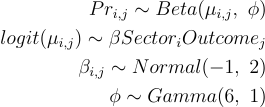
# 使用Beta进行部门:结果交互项建模 - 池化Phi项m3a <- brm( proportion ~ sector:outcome + 0, family = Beta, data = df_long |> mutate(proportion = proportion + 0.01), # Beta回归不能处理为0的结果,所以我们在这里添加了一个小增量 prior = c(prior(normal(-1, 2), class = 'b'), prior(gamma(6, 1), class = 'phi')), iter = 8000, warmup = 1000, cores = 4, chains = 4, seed = 246, save_pars = save_pars(all = T), control = list(adapt_delta = 0.99, max_treedepth = 15)) |> add_criterion(c('waic', 'loo'), moment_match = T)summary(m3a)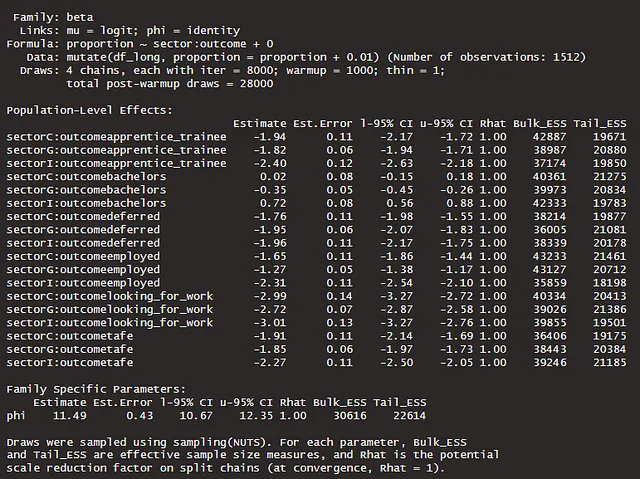
请注意,在模型设置中,我们对所有比例增加了1%的增量——这是因为Beta回归不能处理零值。我们尝试使用零膨胀贝塔模型来建模,但收敛时间更长。
同样地,我们可以在没有汇总的φ的情况下进行建模,根据我们在上面的分布中观察到的情况,这是有直觉的,每个部门和结果组合之间存在变化。模型定义如下。
m3b <- brm( bf(proportion ~ sector:outcome + 0, phi ~ sector:outcome + 0), family = Beta, data = df_long |> mutate(proportion = proportion + 0.01), prior = c(prior(normal(-1, 2), class = 'b')), iter = 8000, warmup = 1000, cores = 4, chains = 4, seed = 246, save_pars = save_pars(all = T), control = list(adapt_delta = 0.99)) |> add_criterion(c('waic', 'loo'), moment_match = T)summary(m3b)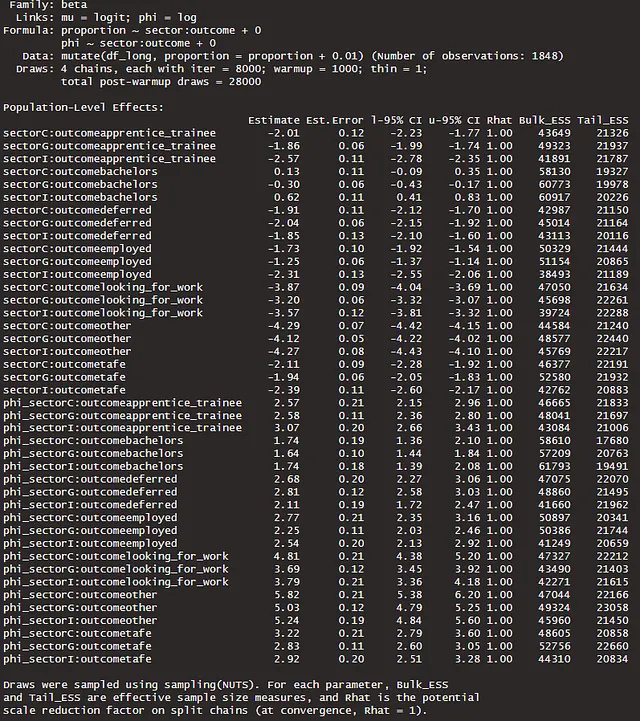
模型诊断和比较
现在我们有两个模型,我们将使用基于Bayesian LOO估计的预期对数点预测密度(elpd_loo)来比较它们的样本外预测准确性。
comp <- loo_compare(m3a, m3b)print(comp, simplify = F)
简单来说,预期的对数点离群值越高,对未见数据的预测准确性就越高。这给我们提供了模型之间的相对准确性好坏的良好相对度量。我们可以通过完成后验预测检查进一步验证这一点,比较观察值和模拟值。在我们的案例中,模型m3b是更好的模型,它符合观察数据。
alt_df <- df_long |> select(sector, outcome, proportion) |> rename(value = proportion) |> mutate(y = 'y', draw = 99) |> select(sector, outcome, draw, value, y)sim_df <- expand_grid(sector = c('C', 'I', 'G'), outcome = unique(df_long$outcome)) |> add_predicted_draws(m3b, ndraws = 1200) |> rename(value = .prediction) |> ungroup() |> mutate(y = 'y_rep', draw = rep(seq(from = 1, to = 50, length.out = 50), times = 504)) |> select(sector, outcome, draw, value, y) |> bind_rows(alt_df)sim_df |> ggplot(aes(value, group = draw)) + geom_density(aes(color = y)) + facet_grid(outcome ~ sector, scales = 'free_y') + scale_color_manual(name = '', values = c('y' = "darkblue", 'y_rep' = "grey")) + theme_ggdist() + labs(y = 'Density', x = 'y', title = '分布-观察值和复制的比例-按部门和结果划分')
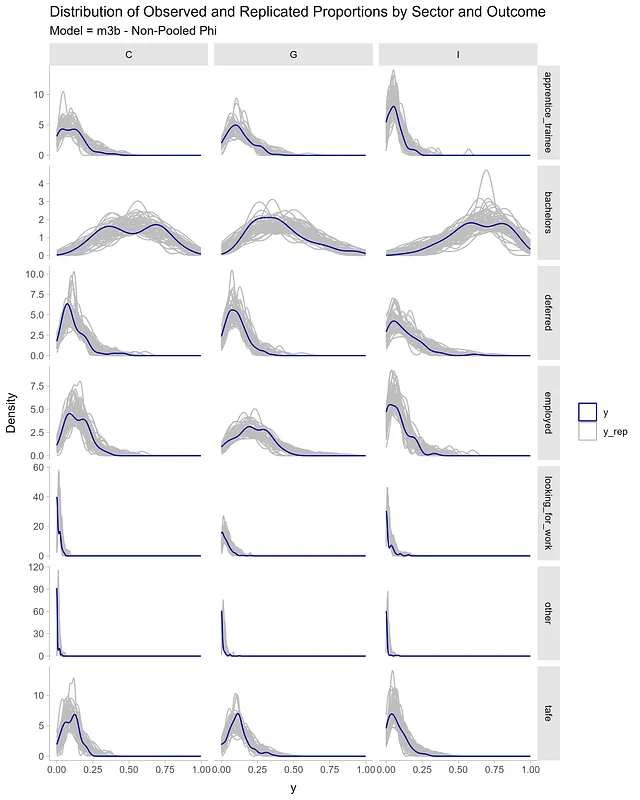
给定非汇总方差或phi项,模型m3b能够更好地捕捉各个部门和结果的比例分布的变化。
ANOVA — 贝叶斯风格
回想一下,我们的研究问题是要了解不同部门之间的结果是否存在差异,并确定差异的程度。在频率统计学中,我们可以使用ANOVA(方差分析)作为一种组间均值差异的方法。但是这种方法的缺点是,结果仅提供估计值和置信区间,没有反映这些估计值的不确定性,而且还有一个令人费解的p值,用于判断均值差异是否具有统计学意义。不,谢谢。
下面我们生成了每个部门和结果组合交互的一组预期值,然后使用优秀的tidybayes::compare_levels()函数来执行繁重的计算工作。它计算了每个结果的部门之间的后验均值差异。为了简洁起见,我们排除了“其他”结果。
new_df <- expand_grid(sector = c('I', 'G', 'C'), outcome = c('apprentice_trainee', 'bachelors', 'deferred', 'employed', 'looking_for_work', 'tafe'))epred_draws(m3b, newdata = new_df) |> compare_levels(.epred, by = sector, comparison = rlang::exprs(C - G, I - G, C - I)) |> mutate(sector = fct_inorder(sector), sector = fct_shift(sector, -1), sector = fct_rev(sector)) |> ggplot(aes(x = .epred, y = sector, fill = sector)) + stat_halfeye() + geom_vline(xintercept = 0, lty = 2) + facet_wrap(~ outcome, scales = 'free_x') + theme_ggdist() + theme(legend.position = 'bottom') + scale_fill_viridis_d(begin = 0.4, end = 0.8) + labs(x = '比例差异', y = '部门', title = '部门和结果的后验均值差异', fill = '部门')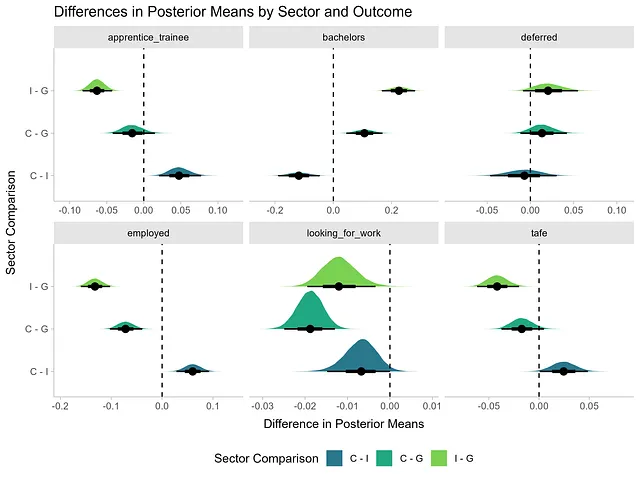
或者我们可以用一个整洁的表格总结所有这些分布,以便更容易解释,并提供89%的可信区间。
marg_gt <- epred_draws(m3b, newdata = new_df) |> compare_levels(.epred, by = sector, comparison = rlang::exprs(C - G, I - G, C - I)) |> median_qi(.width = .89) |> mutate(across(where(is.numeric), ~round(.x, 3))) |> select(-c(.point, .interval, .width)) |> arrange(outcome, sector) |> rename(diff_in_means = .epred, Q5.5 = .lower, Q94.5 = .upper) |> group_by(outcome) |> gt() |> tab_header(title = '结果的部门边缘分布') |> #tab_stubhead(label = '部门比较') |> fmt_percent() |> gtExtras::gt_theme_pff()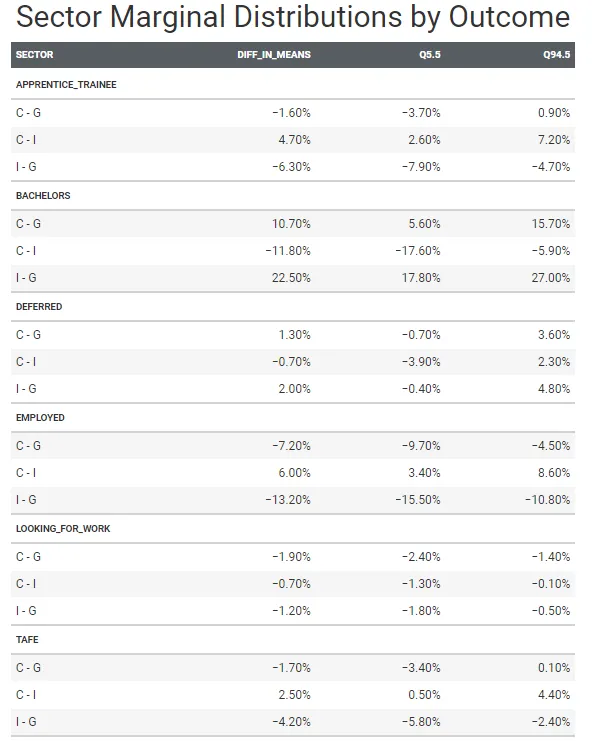
例如,如果我们要在正式报告中总结一个比较,我们可能会写以下内容。
政府学校的学生比天主教学校和独立学校的学生更不可能在完成高中后开始本科学位。
平均而言,政府学校学生的比例为42.5%(介于39.5%和45.6%之间),天主教学校学生的比例为53.2%(介于47.7%和58.4%之间),独立学校学生的比例为65%(介于60.1%和69.7%之间),他们在完成高中后开始本科教育。
天主教学校和政府学生的本科注册之间的差异的后验概率为89%,差异范围为5.6%至15.7%,平均为10.7%。此外,独立学校和政府学生的本科注册之间的差异范围为17.8%至27%,平均为22.5%。
这些差异是显著的,这些差异不为零的概率为100%。
总结和结论
在本文中,我们演示了如何使用贝叶斯建模来模拟比例数据,并使用贝叶斯方差分析来探索不同行业之间比例结果的差异。
我们并没有寻求对这些差异进行因果理解。可以想象,有多个因素影响个体学生的表现,如社会经济背景、父母教育水平,以及学校层面的影响和资源等。这是一个非常复杂的公共政策领域,往往会陷入零和论的困境。
就个人而言,我是家族中第一个上大学并完成学业的人。我曾就读于一所中等水平的公立高中,通过了合理好的考试成绩进入了我首选的大学。我的父母鼓励我接受教育,他们都选择在16岁时离开学校。虽然这篇文章提供了证据表明政府学校和非政府学校之间的差异是真实存在的,但它纯粹是描述性的。





