腾讯AI实验室的研究人员推出了IP-Adapter:一种用于文本到图像扩散模型的文本兼容图像提示适配器
Tencent AI Lab researchers have developed IP-Adapter, a text-compatible image prompt adapter for text-to-image diffusion models.


“苹果”,瞬间你的脑海中浮现出一个苹果的图像。我们的大脑如此迷人,同样令人着迷的是,生成式人工智能带来了同样的创造力和力量,使机器能够产生我们所称之为原创内容的东西。最近,出现了令人印象深刻的文本到图像模型,可以创建高度逼真的图像。你可以将“苹果”输入模型,获得各种苹果的图像。
然而,通过文本提示使这些模型生成我们想要的内容是非常具有挑战性的。通常需要精心设计合适的提示。另一种方法是利用图片提示。虽然当前一套直接改进预先存在的模型的技术取得了成功,但它们需要大量的计算能力,并且缺乏与不同基础模型、文本提示和结构调整的兼容性。
可控图像生成的最新进展突出了文本到图像扩散模型中交叉注意力模块的问题。这些模块使用特定于预训练扩散模型的交叉注意力层中键和值数据的投影权重,主要针对文本特征进行优化。因此,在该层中将图像特征与文本特征对齐主要是将图像特征与文本特征对齐。然而,这可能忽视图像的具体细节,在使用参考图像时导致更广泛的控制(例如管理图像风格)。
- Meta AI发布了SeamlessM4T:一个基础的多语言和多任务模型,可以在语音和文本之间无缝地进行翻译和转录
- 超越条形图:使用桑基图、圆形打包和网络图的数据
- 这篇人工智能论文提出了MATLABER:一种新颖的潜在BRDF自编码器,用于材质感知的文本到3D生成

在上面的图像中,我们可以看到右侧的示例展示了图像变化、多模态生成和图像提示修复的结果,而左侧的示例展示了使用图像提示和其他结构条件进行可控生成的结果。
研究人员引入了一种名为IP-Adapter的有效图像提示适配器,以解决当前方法所带来的挑战。IP-Adapter使用一种独立的方法来处理文本和图像特征。在扩散模型的UNet中,研究人员额外添加了一个专门用于图像特征的交叉注意力层。在训练过程中,调整新的交叉注意力层的设置,使原始UNet模型保持不变。这个适配器既高效又强大:即使只有2200万个参数,一个IP适配器也可以生成与从文本到图像扩散模型派生的完全微调的图像提示模型一样好的图像。
研究结果证明了IP-Adapter的可重用性和灵活性。在基础扩散模型上训练的IP-Adapter可以推广到从相同基础扩散模型微调的其他定制模型。此外,IP-Adapter与其他可控适配器(如ControlNet)兼容,可以轻松地将图像提示与结构控制相结合。由于独立的交叉注意力策略,图像提示可以与文本提示一起工作,创建多模态图像。
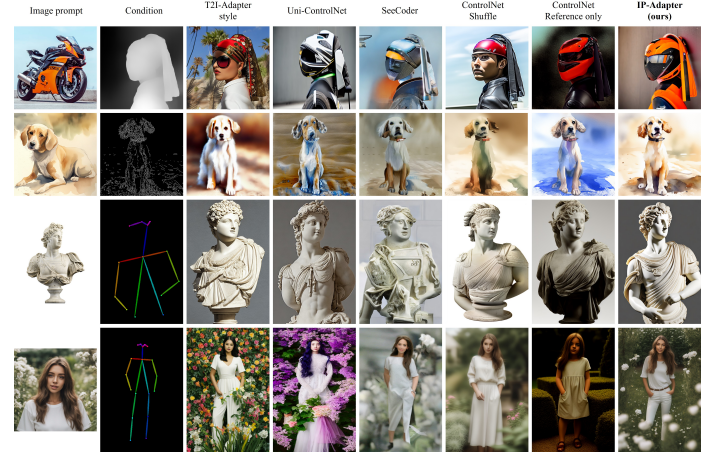
上面的图像演示了IP-Adapter在不同结构条件下与其他方法的比较。尽管IP-Adapter非常有效,但它只能生成与参考图像在内容和风格上相似的图像。换句话说,它无法合成与给定图像的主题高度一致的图像,如一些现有方法,例如文本反转和DreamBooth。未来,研究人员的目标是开发更强大的图像提示适配器,以增强一致性。




