MLOps 思维:始终保持生产就绪状态
MLOps 思维:始终保持生产就绪状态' can be condensed as 'MLOps 思维:保持生产就绪'.
机器学习(ML)在许多领域取得了成功,但也带来了一系列新的挑战,特别是需要持续训练和评估模型,并持续检查训练数据的漂移。持续集成和部署(CI/CD)是任何成功的软件工程项目的核心,通常被称为DevOps。DevOps有助于简化代码演进,实现各种测试框架,并为各种部署服务器(开发、暂存、生产等)提供灵活性。
与ML相关的新挑战扩展了CI/CD的传统范围,还包括现在通常称为持续训练(CT)的概念,这个术语最早由Google引入。持续训练要求对新数据集进行持续训练和评估,然后再部署到生产环境中,并提供更多的ML特定功能。如今,在机器学习的背景下,DevOps被称为MLOps,包括CI、CT和CD。
MLOps原则
所有产品开发都基于一定的原则,MLOps也不例外。以下是三个最重要的MLOps原则。
- 持续性:MLOps的重点应该是演进,无论是持续训练、持续开发、持续集成还是任何不断演进/变化的事物。
- 跟踪一切:由于ML的探索性质,需要跟踪和收集发生的一切,类似于科学实验中的过程。
- 拼图方法:任何MLOps框架都应支持可插拔组件。然而,平衡很重要:过多的可插拔性会导致兼容性问题,而过少会限制使用。
在这些原则的基础上,让我们确定一个良好的MLOps框架所需的关键要求。
MLOps要求
如前所述,机器学习为Ops带来了一套新的独特要求。
- 可重复性:使ML实验能够重复产生相同的结果以验证性能。
- 版本管理:从所有方向保持版本管理,包括:数据、代码、模型和配置。执行“数据-模型-代码”版本管理的一种方法是使用像GitHub这样的版本控制工具。
- 流水线:尽管有向无环图(DAG)的基于管道的流水线通常用于非ML场景(例如Airflow),但ML为连续训练带来了自己的流水线需求。将流水线组件用于训练和预测确保了特征提取的一致性,减少了数据处理错误。
- 编排和部署:ML模型训练需要涉及GPU的分布式机器框架,因此,在云中执行流水线是ML训练周期的固有部分。基于各种条件(指标、环境等)进行模型部署在机器学习中带来了独特的挑战。
- 灵活性:为选择数据源、选择云提供商以及决定不同工具(数据分析、监控、ML框架等)提供灵活性。可以通过提供对外部工具的插件选项和/或提供自定义组件定义能力来实现灵活性。灵活的编排和部署组件确保了云无关的流水线执行和ML服务。
- 实验跟踪:对于ML来说,实验是任何项目的一个隐含部分。经过多轮实验后(即在架构或超参数中进行实验),ML模型变得成熟。为将来参考保留每个实验的日志对于ML至关重要。实验跟踪工具可以用于确保代码和模型版本控制,而类似DVC的工具可以确保代码和数据版本控制。
实际考虑因素
在创建ML模型的激情中,人们通常会忽略一些特定的ML卫生习惯,例如初始数据分析、超参数调整或预/后处理等。在许多情况下,项目开始时缺乏ML生产思维,导致在项目后期(特别是在生产阶段)出现意外(内存问题、预算超支等),导致重新建模和延迟上市时间。但从ML项目开始时使用MLOps框架可以从一开始就解决生产考虑因素,并强制执行解决机器学习问题(如数据分析、实验跟踪等)的系统方法。
MLOps也使得在任何给定的时间点都可以准备投入生产。这对于初创公司来说通常至关重要,因为他们需要缩短上市时间。通过MLOps提供的编排和部署的灵活性,可以通过预定义的编排器(例如GitHub动作)或部署器(例如MLflow,KServe等)实现生产就绪。
现有的MLOps框架
像Google、Amazon、Azure等云服务提供商提供了自己的MLOps框架,可以在它们自己的平台上使用,也可以作为现有机器学习框架的一部分(例如Tensorflow框架中的TFX编排)。这些MLOps框架易于使用,功能齐全。
使用云服务提供商的MLOps框架会限制组织在其环境中使用MLOps。对于许多组织来说,这成为一个重大限制,因为云服务的使用取决于客户的需求。在许多情况下,需要一个提供选择云提供商灵活性并且具有大多数MLOps功能的MLOps框架。
开源的MLOps框架在这种情况下非常方便。ZenML、MLRun、Kedro、Metaflow是一些广泛使用的众所周知的开源MLOps框架,各有利弊。它们都在选择云提供商、编排/部署和ML工具方面提供了很好的灵活性。选择任何一个这些开源框架取决于具体的MLOps需求。然而,所有这些框架都足够通用,可以满足各种需求。
根据对当前状态的这些开源MLOps框架的经验,我推荐以下内容:
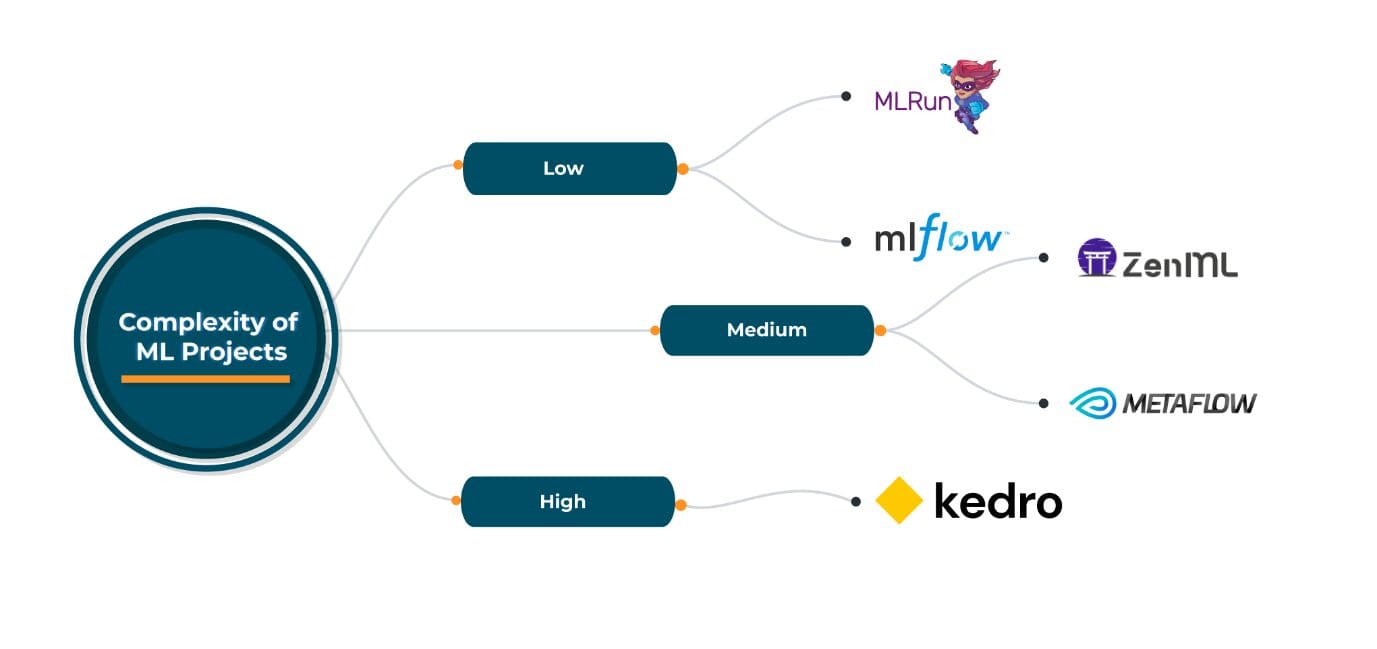
早期采用MLOps
MLOps是DevOps的下一个演进阶段,它将来自不同领域的人们聚集在一起:数据工程师、机器学习工程师、基础架构工程师以及其他人。在将来,我们可以预期MLOps将变得类似于当前我们在DevOps中看到的低代码。特别是初创公司应该在产品早期阶段采用MLOps,以确保更快的上市时间以及它带来的其他好处。 Abhishek Gupta是Talentica Software的首席数据科学家。在他目前的角色中,他与许多公司密切合作,为他们的产品线提供人工智能/机器学习支持。Abhishek是印度科学院班加罗尔分校的校友,他在人工智能/机器学习和大数据领域工作了7年以上。他在通信网络和机器学习等各个领域拥有多项专利和论文。






